







一、PT
1.通过pt_shell启动 pt工具。
2.导入想要检查的session,(restore_session $对应session)一般情况下会考虑hold & set up 的最恶劣情况检查,分别是ff和ss情况下。
session主要记录的是
3.报出想看的timing rpt (report_timing)
【1】 常用option 1.-from (指定startpoint)
2.-to (指定endpoint)
3.-group (指定组别类型)
4.-pba_mode (设置PBA模式开关)
全称path based analysis(基于路径的分析),是一种STA分析方式
5.-nets -crosstalk_delta -capacitance (在报告中体现出对应的延迟)
6.-nosplit (不进行换行 方便查看)
7.-delay_type (选择rpt的时序检查 hold使用min setup使用max)
8.-path_type full_clock (rpt中显示出全部的clock path)
9.-max_paths (输出此数量的符合条件的rpt)
【2】报告分析
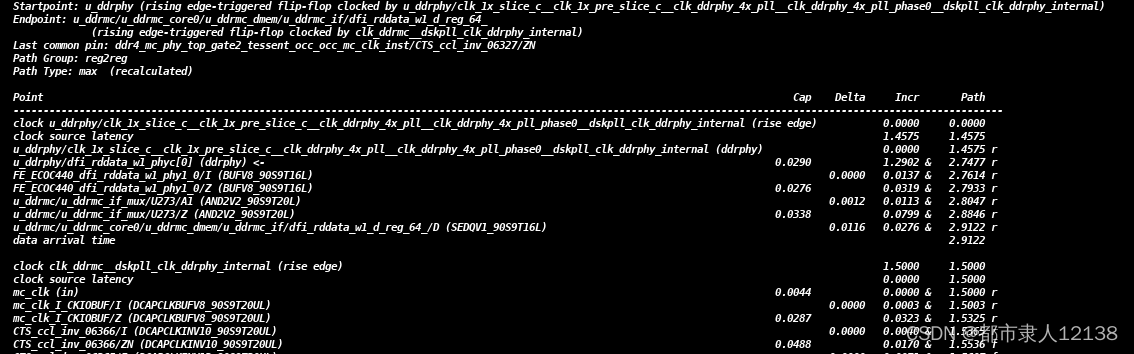
首先是 StartPoint 后面跟着的是 时序的开始节点、EndPoint同理;
接下来是last common pin 是最近的common 的pin节点,用于寻找这条时序线的commonpath,launch path,capture path。
path group 记录的是该path的种类,一般分为input2optput、input2reg、reg2reg、reg2output。
path type记录了检查的类型是setup 检查还是hold检查 分别对应max和min类型,类型指代的是data arrive time 的传输时间最大最小值,当进行setup检查时,悲观的考虑就是数据传输时间最长的时候,相同的min就是hold检查时最严苛的考虑。
接下来就是时序的信息了,该信息根据option不同有所不同
分别记录的是data的传输路径和时钟信息的传输路径 以中间空行为分割,分别记录了传输路径中经过的cell名字和cell的类型,cap这一列记录了cell对应的capacitance,Delata列记录了crosstalk的影响,Incr列记录了上一行到本行的增量,path是指到本行为止积累的延迟。
所以修复过程中根据data path的增量情况进行修复。
4.修复Timing Violation
常用的修复方法有size cell和add buffer,remove buffer当然还有很多其他方法,目前为止本小白只实操过以上两种方法,其他方法实操后补充。
size_cell $inst名字 $cell 类型
insert_buffer $插入buffer的位置 $cell 类型
remove_buffer $inst名字 (会维持原本的逻辑链接只是在逻辑中删除了该cell,而不是打断连线)
5.输出PT中所做的修改
write_changes -format $输出的文件格式类型 -output $输出文件的目录和名字
6.根据报告点对点报出所有的timing violation path,主要用于顶层给的rpt,方便对齐到block中

perl 转换ICC2---innovus
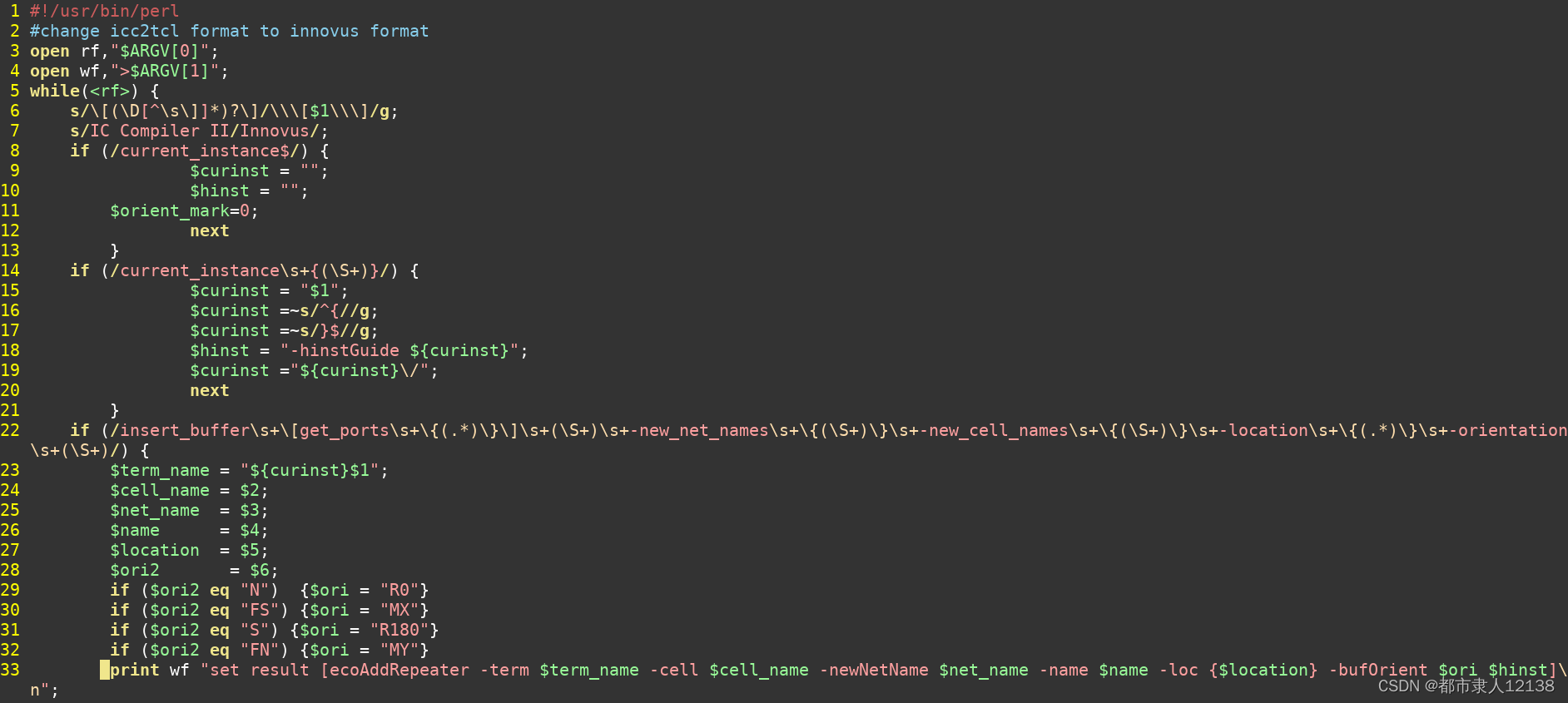

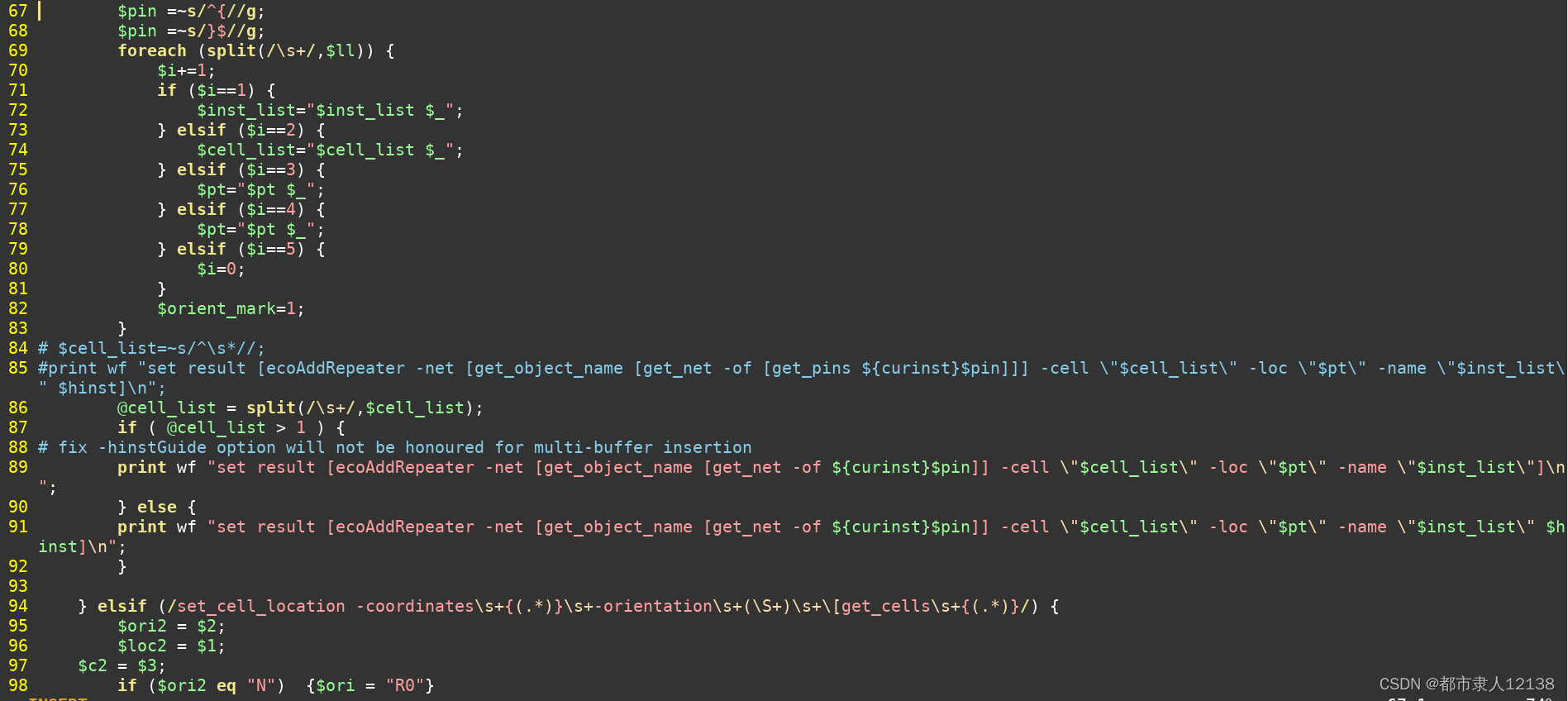
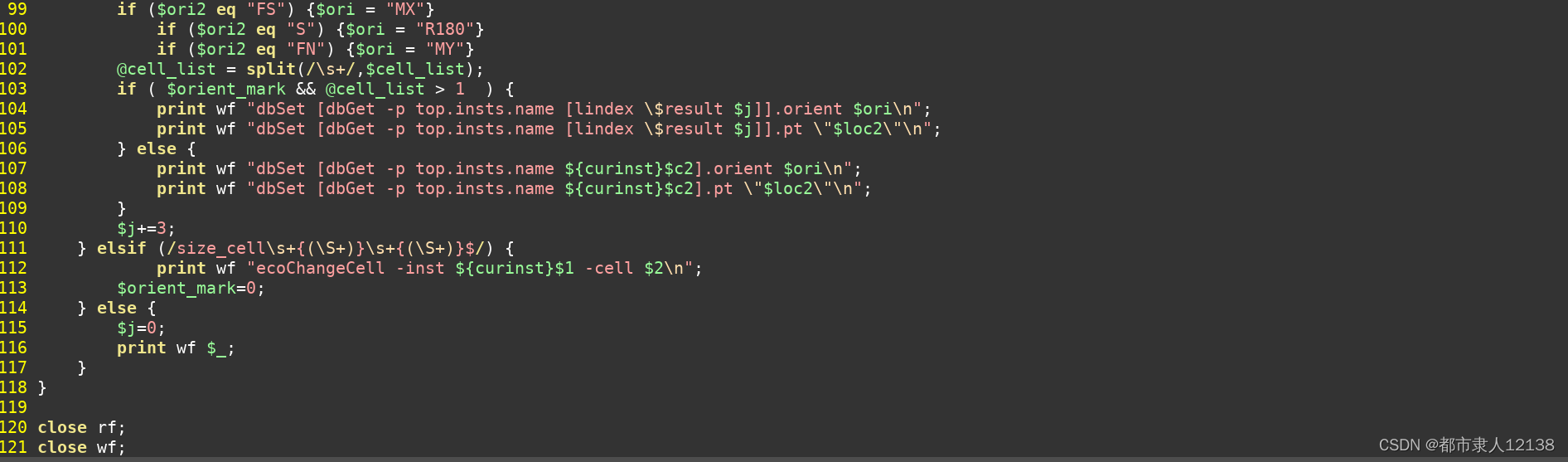


















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









