







波士顿房价案例
借助此案例熟悉
- 线性回归算法的API
- 正规方程法API
- 梯度下降法的API
1 案例背景

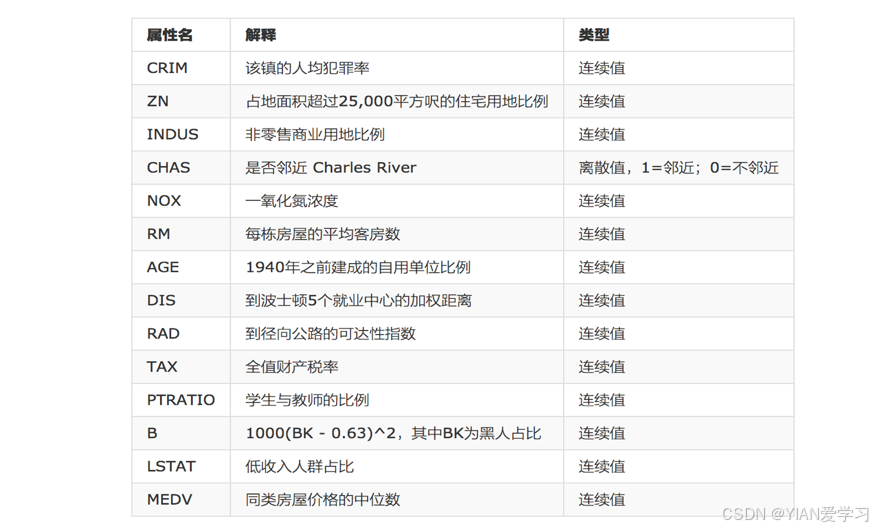
2 数据属性
3 分析思路
- 导入数据及相应的工具包
- 查看数据,回归数据中大小不一致,量纲不同,对于结果影响大,进行数据标准化
- 数据标准化
- 数据集划分
- 模型训练
- 正规方程法
- 梯度下降法
- 结果预测
- 模型评估(MSE)
4 正规方程法
# 0.导包
# from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_squared_error,mean_absolute_error
# 1.加载数据
# boston = load_boston()
# print(boston)
import pandas as pd
import numpy as np
# 导入数据
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 2.数据集划分
x_train,x_test,y_train,y_test =train_test_split(data,target,test_size=0.2,random_state=22)
# 3.标准化
process=StandardScaler()
x_train=process.fit_transform(x_train)
x_test=process.transform(x_test)
# 4.模型训练 - 采用线性回归模型
# 4.1 实例化(正规方程)
# 默认采用的就是正规方程法
model =LinearRegression(fit_intercept=True)
# 4.2 fit
model.fit(x_train,y_train)
"""
coef:
[-0.73088157 1.13214851 -0.14177415 0.86273811 -2.02555721 2.72118285
-0.1604136 -3.36678479 2.5618082 -1.68047903 -1.67613468 0.91214657
-3.79458347]
intercept:
22.57970297029704
"""
print(model.coef_)
print(model.intercept_)
# 5.预测
y_predict=model.predict(x_test)
print(y_predict)
# 6.模型评估
# 使用MSE进行评估
"""
MSE: 20.77068478427006
RMSE: 4.557486674063903
MAE: 3.425181871853366
"""
print("MSE:",mean_squared_error(y_test,y_predict))
print("RMSE:",mean_squared_error(y_test,y_predict) ** 0.5)
print("MAE:",mean_absolute_error(y_test,y_predict))
5 梯度下降法
# 0.导包
# from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_squared_error,mean_absolute_error
# 1.加载数据
# boston = load_boston()
# print(boston)
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 2.数据集划分
x_train,x_test,y_train,y_test =train_test_split(data,target,test_size=0.2,random_state=22)
# 3.标准化
process=StandardScaler()
x_train=process.fit_transform(x_train)
x_test=process.transform(x_test)
# 4.模型训练
# 4.1 实例化(正规方程)
# 随机梯度下降法
model = SGDRegressor(learning_rate='constant',eta0=0.01)
# 4.2 fit
model.fit(x_train,y_train)
# print(model.coef_)
# print(model.intercept_)
# 5.预测
y_predict=model.predict(x_test)
print(y_predict)
# 6.模型评估
"""
MSE: 23.39259636923585
RMSE: 4.836589332291491
MAE: 3.562918092849904
"""
print("MSE:",mean_squared_error(y_test,y_predict))
print("RMSE:",mean_squared_error(y_test,y_predict) ** 0.5)
print("MAE:",mean_absolute_error(y_test,y_predict))
6 小结
- 通过正规方程法进行优化
model = sklean.linear_model.LinearRegression(fit_intercept-True)
- fit_intercept:是否计算偏置,一般选择True,默认是True
属性:model.coef_(回归系数)、model.intercept_(偏置)
- 通过梯度下降法进行优化
model = sklean.linear_model.SGDRegressor(
loss="squared_loss",
fit_intercept="True",
learning_rate="constant",
eta0=0.01
)
-
SGDRegressor类实现了随机梯度下降学习,它支持不同的损失函数和正则化惩罚项,来拟合线性回归模型。
-
loss(损失函数类型):squared_loss(均方误差)
-
fit_intercept:是否计算偏置,一般选择True,默认是True
-
learning_rate(学习率策略):string,optional,可以配置学习率随着迭代次数不断变小,策略:
-
learning_rate = “invscaling”
-
eta = eta0 / pow(t,power_t=0.25)
学习率固定为常数
-
learning_rate = “constant”
-
eta0 = 0.001
-
-
属性:model.coef_(回归系数)、model.intercept_(偏置) -
正规方程法得到的是最优解,梯度下降法只能逼近最优解

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









