







1.为什么需要对决策树做出剪枝操作?
“剪枝”是决策树学习算法对付”过拟合“的主要手段。
为什么会出现过拟合?
为了尽可能正确分类训练样本,结点的划分过程会不断重复直到不能再分,这样就可能会把训练样本的一些特点当做所有数据都具有的一般性质,从而导致过拟合。
解决策略
可以通过”剪枝“一定程度上避免因为决策分支过多,以至于把自身的一些特点当作所有数据集都具有的一般性质而导致的过拟合。
2.剪枝的基本策略
策略一 预剪枝
基本思想:在决策树的生成过程中,对每个结点划分前先做评估,如果划分不能提升决策树的泛化性能,就停止划分并将此节点记为叶节点;
策略二 后剪枝
基本思想:在决策树构造完成后,自底向上对非叶节点进行评估,如果将其换成叶节点能提升泛化性能,则将该子树换成叶节点。
3. 西瓜案例完成剪枝
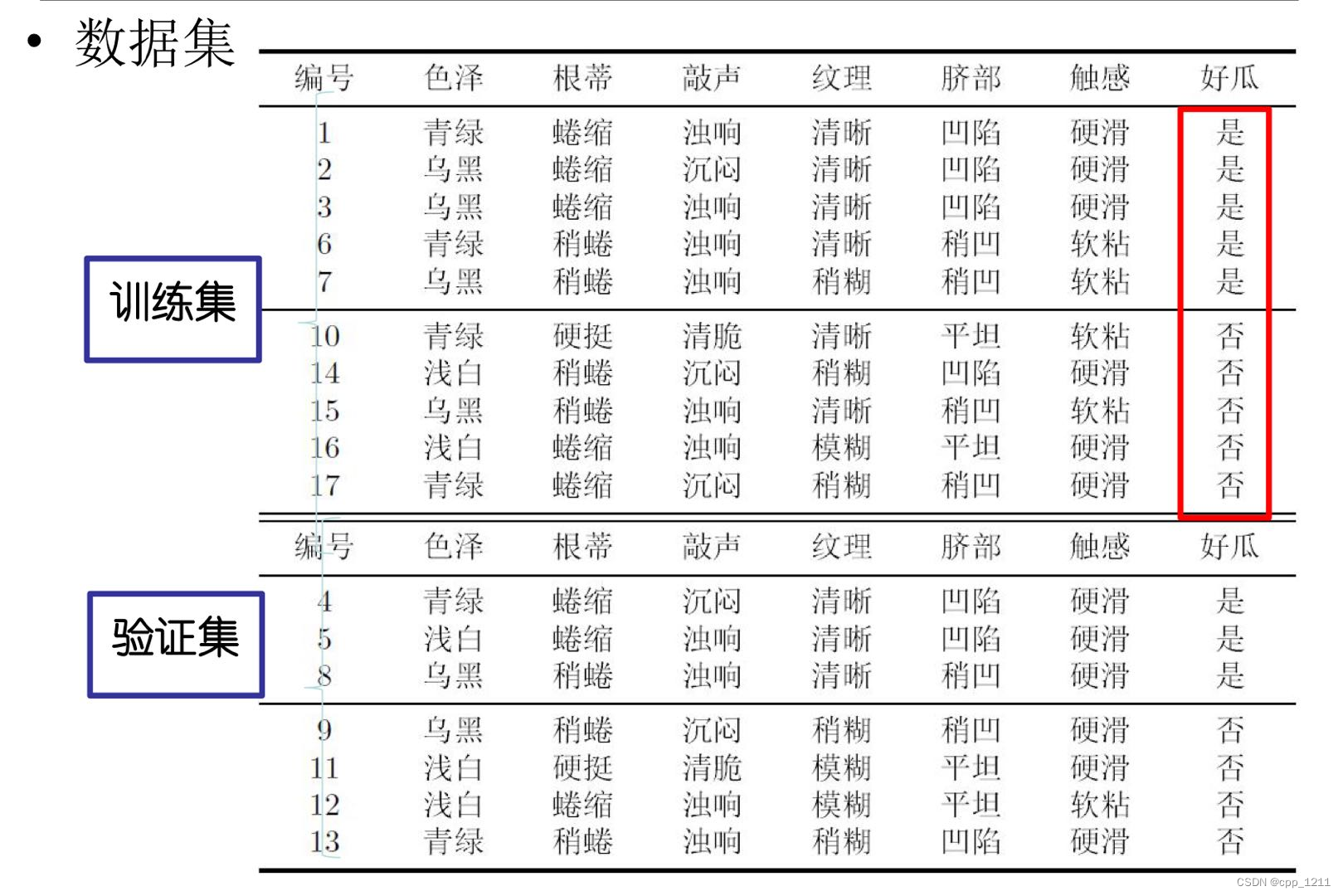
3.1 数据集
3.2 预剪枝
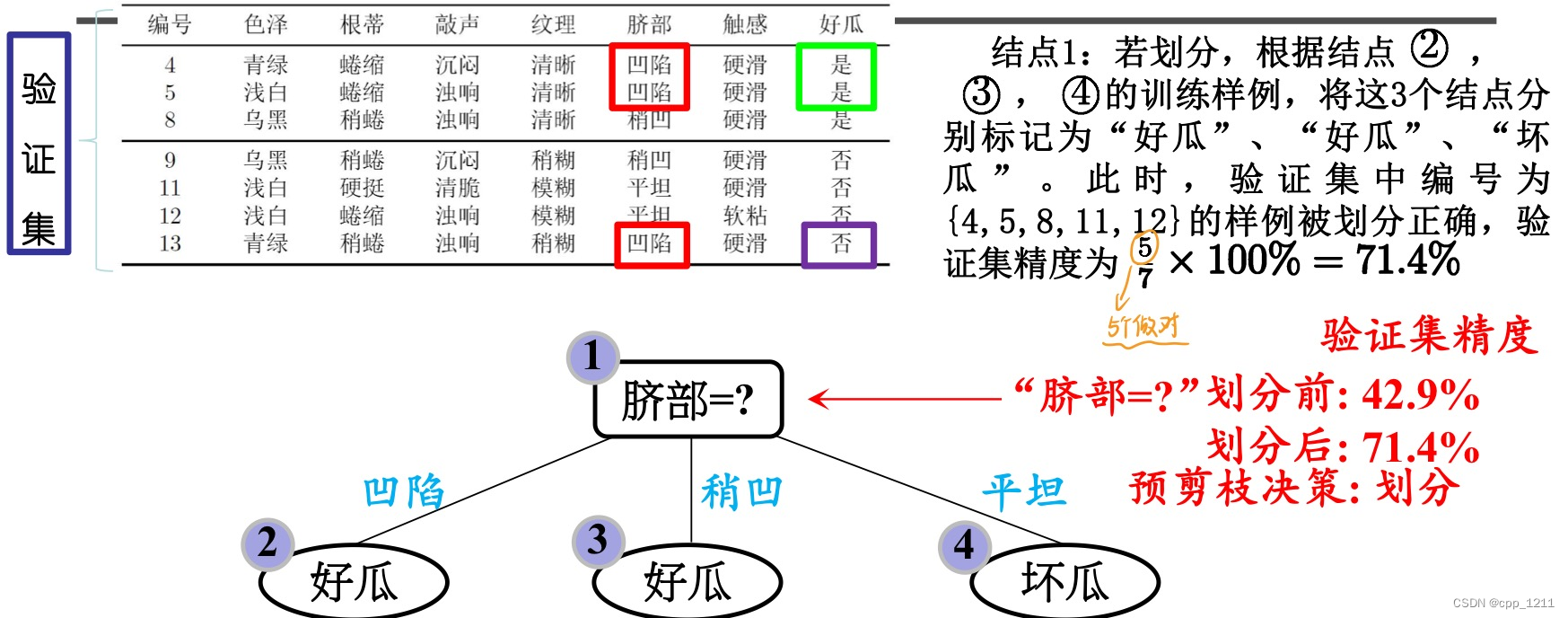
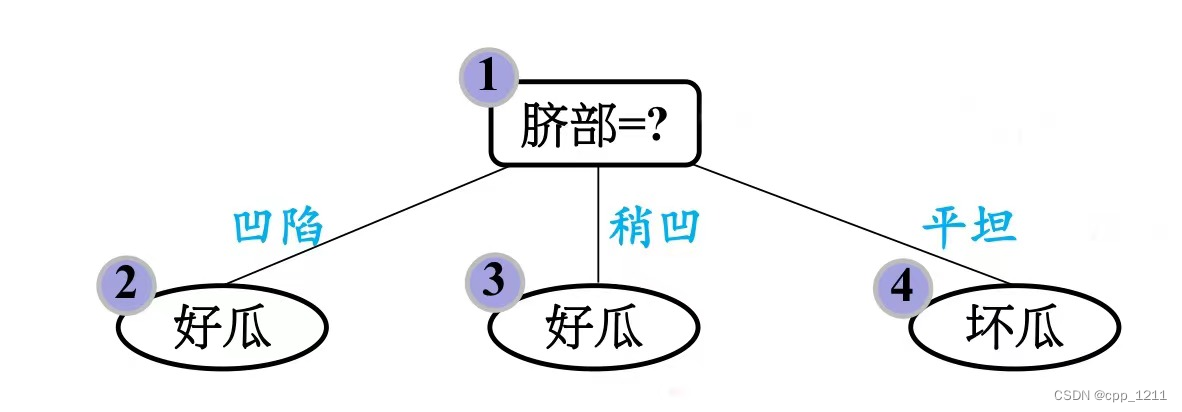
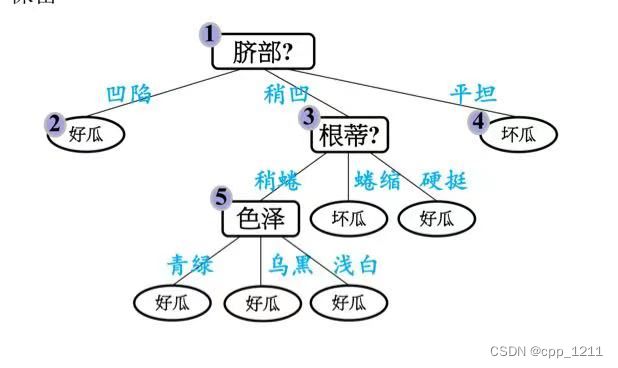
(1)针对上述数据集,基于信息增益准则,选取属性“脐部”划分训练集。分别计算划分前(即直接将该结点作为叶结点)及划分后的验证集精度,判断是否需要划分。
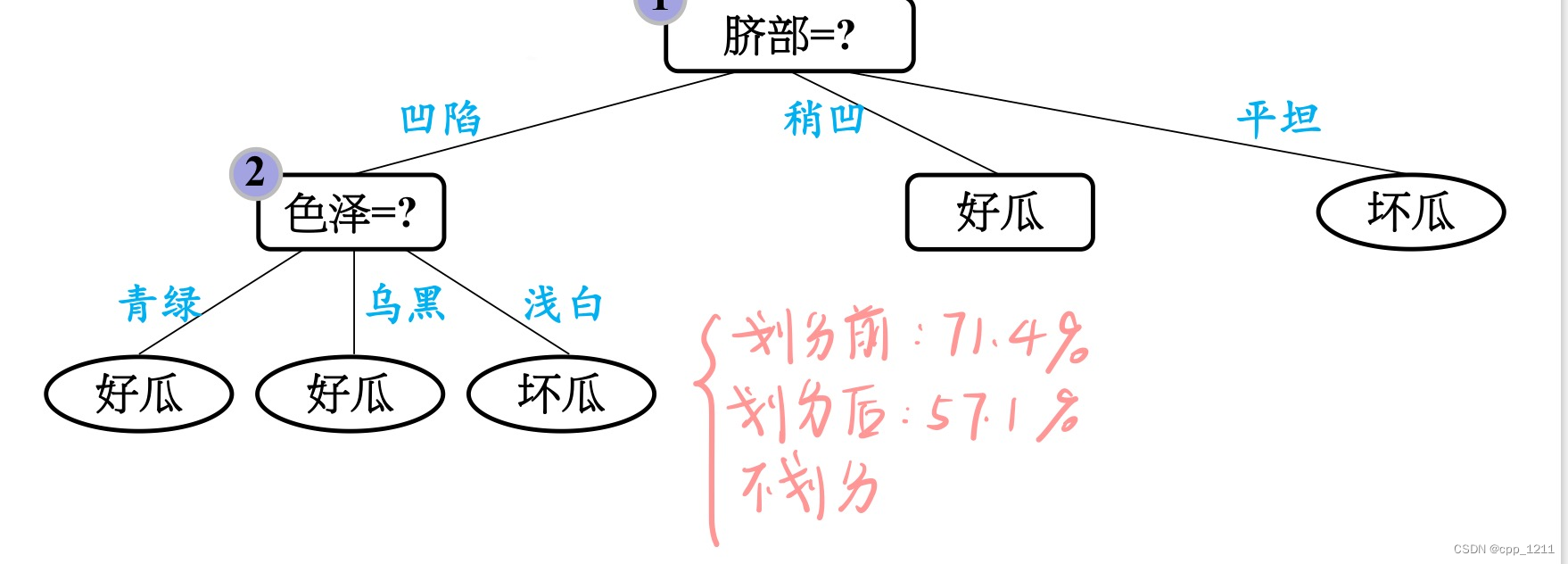
(2)再看“脐部”为凹陷这个分支,如果对其进行划分,选择“色泽”作为划分属性。
色泽继续划分,验证集中 编号为{4,8,11,12} 的样例被划 分正确,验证集精度为4/7*100% = 57.1%
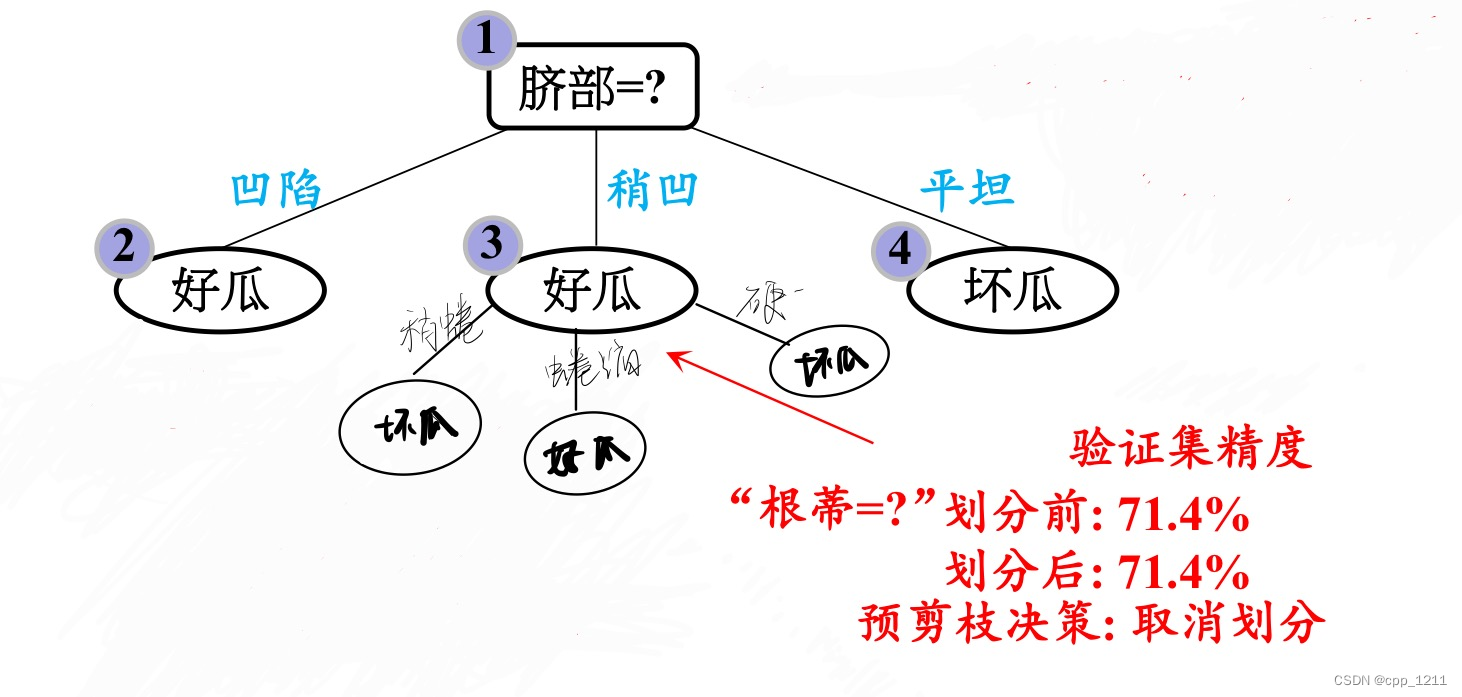
(3)再看“脐部“为稍凹这个分支,如果对其进行划分,选择“根蒂”作为划分属性。
根蒂继续划分,验证集中 编号为{4,5,9,11,13} 的样例被划 分正确,验证集精度为5/7*100% = 71.4%
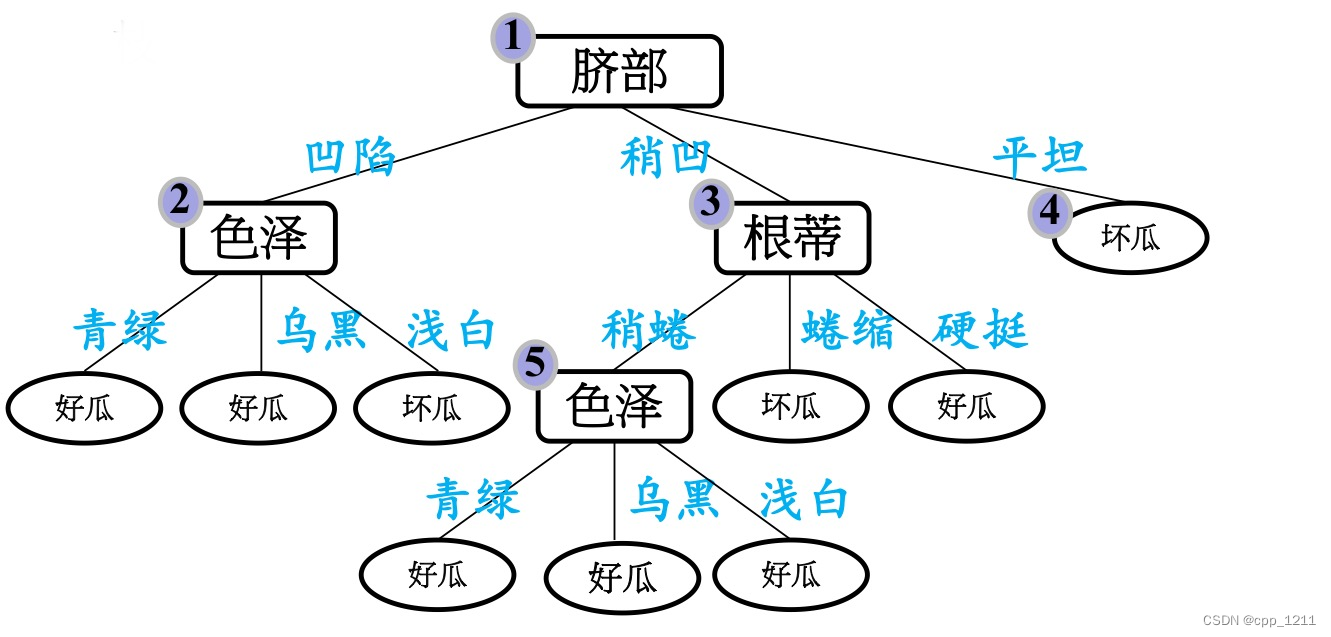
(4)最终的决策树
(5)预剪枝的优缺点
优点:降低过拟合的风险,显著减少训练时间和测试开销时间
缺点:有欠拟合的风险,当前的划分虽然不能提升泛化性能,但在其基础上进行的后续划分却有可能显著提高性能
3.3 后剪枝
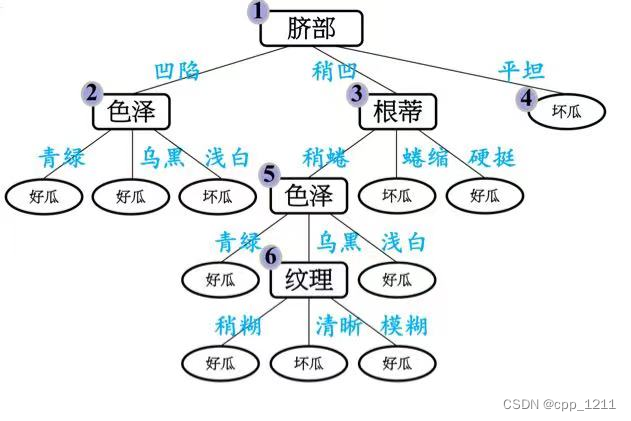
(1)先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行 分析计算,若将该结对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
首先生成一棵完整 的决策树,验证的编号{4,11,12}划分正确,该决策 树的验证集精度为3/7= 42.9%
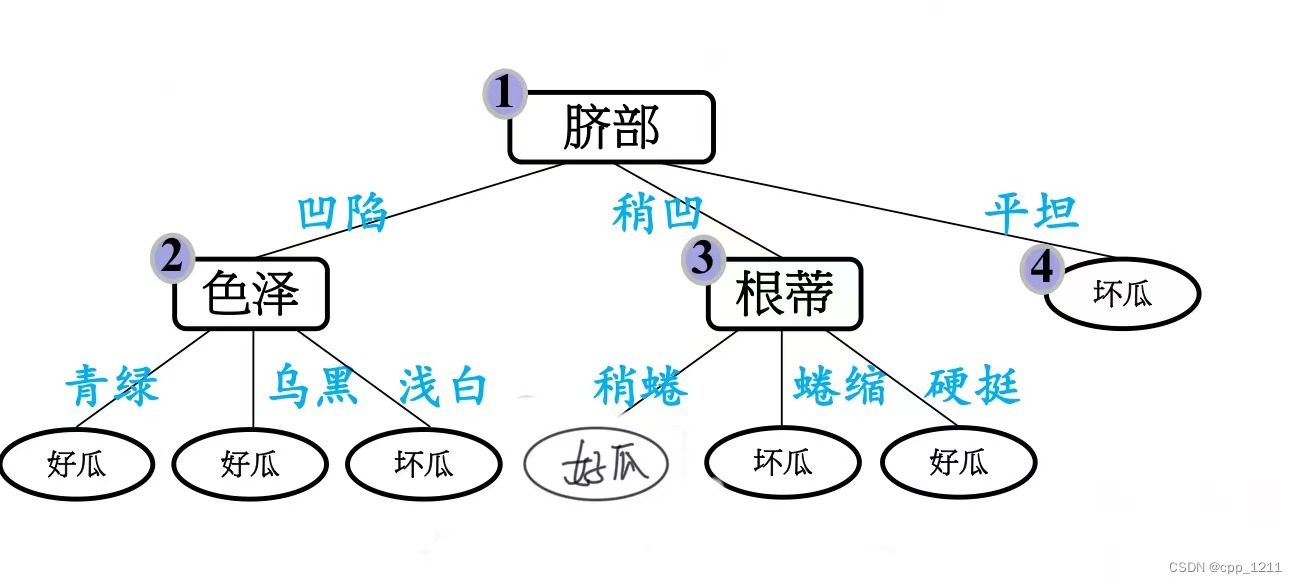
(2)首先考虑结点6,若将其替换为叶结点,根据落在其上的训练样本{7,15}将其标记为“好瓜”。
验证的编号{4,8,11,12}划分正确,得到验证集精度提高为4/7=57.1%,则决定剪枝。
(3)然后考虑结点5,若将其替换为叶结点,根据落在其上的训练样本{6,7,15}将其标记为“好瓜”
验证的编号{4,8,11,12}划分正确,得到验证集精度为4/7=57.1%,精度未提高,则决定不剪枝。
(4)对结点2,若将其替换为叶结点,根据落在其上的训练样本{1,2,3,14},将其标记为“好瓜”
验证集中 编号为{4,5,9,11,13} 的样例被划 分正确,验证集精度为5/7*100% = 71.4%,则决定剪枝。
(5)最终的决策树
(6)后剪枝的优缺点
优点:后剪枝比预剪枝保留了更多的分支,欠拟合风险小 ,泛化性能往往优于预剪枝决策树
缺点:训练时间开销大
4.决策树剪枝算法实现
4.1 数据集
这里的数据集取的是毕业生薪资等级的数据集。
professional:专业编号;gender:性别(1:男;0:女);age:年龄;socialSkill:社交能力;professionalSkill:专业能力;
isJob:薪资等级标签
这里只抽取了前16个训练样本。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











