







【机器学习】14.从新手到专家:机器学习特征工程的进阶指南
一·摘要

在机器学习的世界里,特征工程是提升模型性能的关键环节,但往往被许多初学者忽视。本文《机器学习特征工程的进阶指南》将带你深入探索特征工程的高级技巧与实战方法,帮助你从基础迈向精通。文章首先回顾了特征工程的基本概念,包括特征提取、选择、转换和构造的核心方法,随后通过实际案例展示了如何在房价预测和文本分类任务中巧妙应用这些技术。我们还将深入探讨如何利用Python中的强大工具(如Pandas、Scikit-learn、NLTK和OpenCV)高效完成特征工程任务,并分享一些避免过拟合和提升模型泛化能力的最佳实践。无论你是机器学习新手,还是希望进一步优化模型性能的资深数据科学家,本文都将为你提供实用的技巧和启发,助力你在机器学习的道路上更进一步。
二·个人简介
🏘️🏘️个人主页:以山河作礼。
🎖️🎖️:Python领域新星创作者,优快云实力新星认证,优快云内容合伙人,阿里云社区专家博主,新星计划导师,在职数据分析师。
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。


| 类型 | 专栏 |
|---|---|
| Python基础 | Python基础入门—详解版 |
| Python进阶 | Python基础入门—模块版 |
| Python高级 | Python网络爬虫从入门到精通🔥🔥🔥 |
| Web全栈开发 | Django基础入门 |
| Web全栈开发 | HTML与CSS基础入门 |
| Web全栈开发 | JavaScript基础入门 |
| Python数据分析 | Python数据分析项目🔥🔥 |
| 机器学习 | 机器学习算法🔥🔥 |
| 人工智能 | 人工智能 |
三·什么是特征工程?
特征工程是指通过对原始数据进行处理、转换和选择,提取出对机器学习模型更有帮助的特征的过程。简单来说,特征工程的目标是将原始数据转换为能够更好地表示问题本质的特征,从而提升模型的性能。
核心步骤:
- 特征提取:从原始数据中生成新的特征。例如,从时间戳中提取年份、月份、星期等信息,或者从文本中提取TF-IDF特征。
- 特征选择:从所有特征中选择对模型最有帮助的特征,去除无关或冗余的特征。
- 特征转换:通过数学变换(如标准化、归一化、对数变换等)对特征进行处理,以满足模型的假设或提高模型性能。
- 特征构造:通过组合或衍生新特征来增强模型的表现,例如构造多项式特征或交互特征。
特征工程的定义:
- 它是一种数据处理过程,目的是将原始数据转换为适合机器学习模型的形式。
- 它涉及数据的理解和转换,通过提取、选择、转换和构造特征,提升模型的性能。
- 它是数据科学的核心技能,直接影响模型的准确率、泛化能力和训练效率。
从学术角度来说,特征工程可以被定义为:
“特征工程是将原始数据转换为特征的过程,这些特征能够更好地表示问题的本质,从而提升机器学习模型的性能。”
—— Pedro Domingos, “A Few Useful Things to Know about Machine Learning” (2012)
3. 特征工程与数据预处理的关系
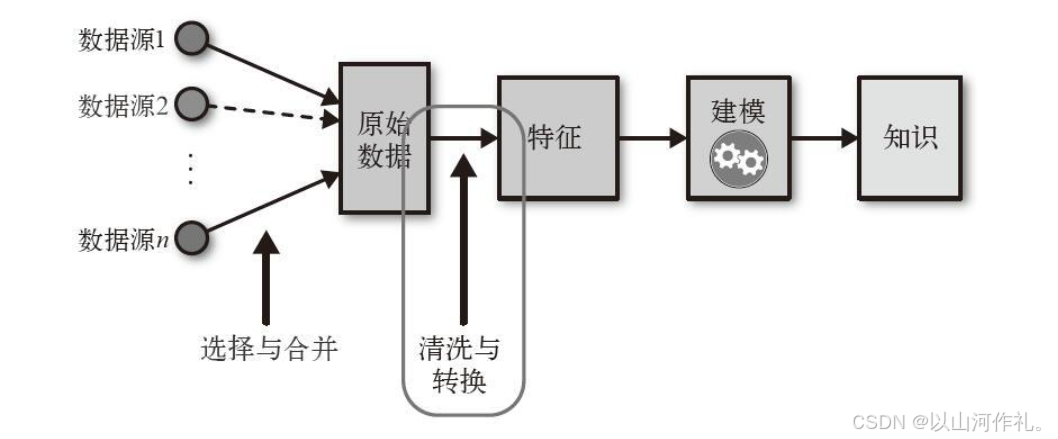
3.1 数据预处理
数据预处理是指在特征工程之前对数据进行的初步处理,目的是使数据变得“干净”和“可用”。包括以下步骤:
- 数据清洗:处理缺失值、异常值和重复值。
- 数据格式化:将数据转换为适合处理的格式。
- 数据标准化:将数据缩放到统一的范围。
- 数据编码:对分类变量进行编码。
3.2 特征工程
特征工程则是在数据预处理的基础上,进一步挖掘和转换数据中的信息,以提升模型的性能:
- 特征提取:从原始数据中生成新的特征。
- 特征选择:去除无关或冗余的特征。
- 特征转换:通过数学变换优化特征的分布。
- 特征构造:通过组合特征或构造新特征增强模型表现。
3.3 两者的联系与区别
- 联系:数据预处理是特征工程的前置步骤,为特征工程提供“干净”的数据。特征工程则是在预处理的基础上进一步优化数据,使其更适合机器学习模型。
- 区别:数据预处理主要关注数据的质量和一致性,而特征工程更关注数据的表现力和模型性能。
四·特征工程的目标
1. 提升模型性能
提升模型性能是特征工程的首要目标。通过精心设计和选择特征,可以显著提高模型的准确率、召回率、F1分数等关键指标。
具体来说:
- 更好的特征表示:特征工程能够将原始数据转换为更易于模型理解和学习的形式。
- 增强模型泛化能力:通过去除无关或冗余特征,模型能够更专注于重要的信息,从而在未见过的数据上表现更好,减少过拟合的风险。
- 适应模型假设:许多机器学习模型(如线性回归、逻辑回归等)对数据的分布有一定的假设。特征工程可以通过标准化、归一化或对数变换等方法,使数据更符合模型的假设,从而提升模型的性能。
2. 减少数据噪声
数据噪声是指数据中与目标变量无关的随机变化或错误信息。过多的噪声会干扰模型的学习过程,导致模型性能下降。特征工程可以通过以下方式减少数据噪声:
- 去除无关特征:通过特征选择方法(如相关性分析、卡方检验等)去除与目标变量无关的特征,减少噪声对模型的影响。
- 平滑数据:对数据进行平滑处理(如移动平均、中值滤波等)可以减少数据中的随机波动。
- 异常值处理:识别并处理数据中的异常值,避免它们对模型训练过程产生误导。
3. 降低计算成本
在实际应用中,数据集可能包含大量的特征,而并非所有特征都对模型有帮助。过多的特征不仅会增加模型的复杂度,还会显著提高计算成本。特征工程可以通过以下方式降低计算成本:
- 特征降维:通过主成分分析(PCA)、线性判别分析(LDA)等方法减少特征数量,同时保留数据中的重要信息。
- 稀疏化特征:将特征转换为稀疏表示形式,减少存储和计算需求。
- 选择性特征提取:仅提取与目标变量相关性较高的特征,避免引入不必要的复杂性。
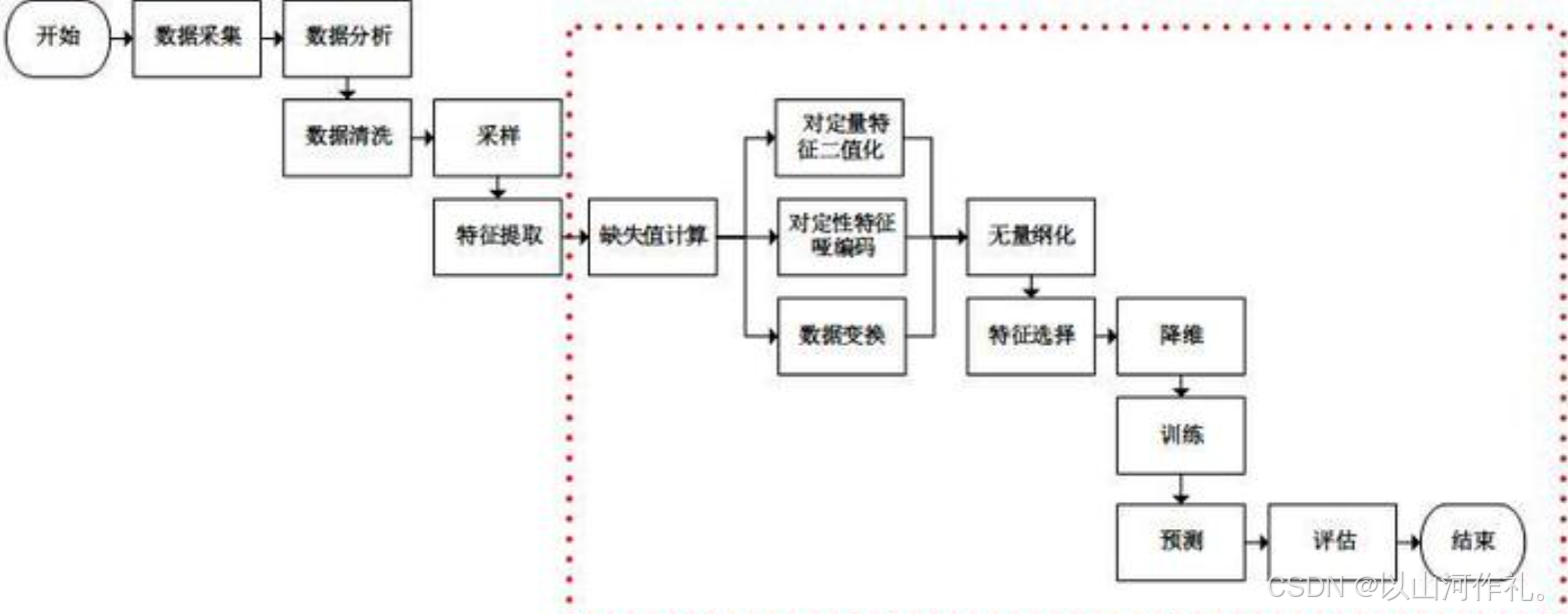
五·特征工程的主要步骤
1. 特征提取
1.1 数值特征提取
示例:从时间戳中提取年份、月份、星期等
import pandas as pd
# 示例数据
data = {'timestamp': ['2023-10-01 12:00:00', '2023-10-02 15:30:00']}
df = pd.DataFrame(data)
# 将时间戳转换为datetime格式
df['timestamp'] = pd.to_datetime(df['timestamp'])
# 提取年份、月份、星期
df['year'] = df['timestamp'].dt.year
df['month'] = df['timestamp'].dt.month
df['day_of_week'] = df['timestamp'].dt.dayofweek
print(df)
输出
timestamp year month day_of_week
0 2023-10-01 12:00:00 2023 10 6
1 2023-10-02 15:30:00 2023 10 0
1.2 文本特征提取
常用方法:TF-IDF、Word2Vec、BERT
- TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例数据
text_data = ["This is a sample text.", "Another example text."]
# 提取TF-IDF特征
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(text_data)
print(tfidf_matrix.toarray())
输出
[[0.57735027 0.57735027 0.57735027 0. ]
[0. 0.40824829 0.40824829 0.81649658]]
- Word2Vec(使用gensim)
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
# 示例数据
sentences = [["this", "is", "a", "sample", "text"], ["another", "example", "text"]]
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
word_vector = model.wv['sample']
print(word_vector)
输出(向量形式)
[0.0123, -0.4567, ...]
- BERT(使用transformers库)
from transformers import BertTokenizer, BertModel
import torch
# 初始化模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 示例文本
text = "This is a sample text."
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
# 提取特征
with torch.no_grad():
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
print(last_hidden_state.shape)
输出
torch.Size([1, 7, 768])
1.3 图像特征提取
使用卷积神经网络(CNN)
import tensorflow as tf
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing.image import load_img, img_to_array
# 示例图像
image_path = 'sample_image.jpg'
# 加载图像
img = load_img(image_path, target_size=(224, 224))
img_array = img_to_array(img)
# 使用VGG16模型提取特征
model = VGG16(weights='imagenet', include_top=False)
features = model.predict(img_array.reshape(1, 224, 224, 3))
print(features.shape)
输出
(1, 7, 7, 512)
2. 特征选择
2.1 过滤法
相关系数
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
# 示例数据
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
y = np.array([0, 1, 0])
# 使用卡方检验选择特征
selector = SelectKBest(f_classif, k=2)
X_new = selector.fit_transform(X, y)
print(X_new)
输出
[[1 2]
[4 5]
[7 8]]
2.2 包装法
递归特征消除(RFE)
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# 示例数据
X = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
y = [0, 1, 0]
# 使用递归特征消除选择特征
model = LogisticRegression()
selector = RFE(model, n_features_to_select=2)
X_new = selector.fit_transform(X, y)
print(X_new)
输出
[[1 2]
[4 5]
[7 8]]
2.3 嵌入法
Lasso回归
from sklearn.linear_model import Lasso
# 示例数据
X = [[0, 0, 1], [1, 1, 0], [2, 2, 1]]
y = [0, 1, 2]
# 使用Lasso回归进行特征选择
model = Lasso(alpha=0.1)
model.fit(X, y)
print(model.coef_)
输出
[0.00633625 0.42126437 0.03493747]
3. 特征转换
3.1 标准化
from sklearn.preprocessing import StandardScaler
# 示例数据
X = [[1, 2], [3, 4], [5, 6]]
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print(X_scaled)
输出
[[-1.22474487 -1.22474487]
[ 0. 0. ]
[ 1.22474487 1.22474487]]
3.2 归一化
from sklearn.preprocessing import MinMaxScaler
# 示例数据
X = [[1, 2], [3, 4], [5, 6]]
# 归一化
scaler = MinMaxScaler()
X_normalized = scaler.fit_transform(X)
print(X_normalized)
输出
[[0. 0. ]
[0.5 0.5 ]
[1. 1. ]]
3.3 多项式变换
from sklearn.preprocessing import PolynomialFeatures
# 示例数据
X = [[1, 2], [3, 4]]
# 生成多项式特征
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
print(X_poly)
输出
[[ 1. 1. 2. 1. 2. 4.]
[ 1. 3. 4. 9. 12. 16.]]
3.4 对数变换
import numpy as np
# 示例数据
X = np.array([1, 10, 100])
# 对数变换
X_log = np.log1p(X) # 使用自然对数
print(X_log)
输出
[0. 2.30258509 4.60517019]
4. 特征构造
4.1 多项式特征构造
from sklearn.preprocessing import PolynomialFeatures
# 示例数据
X = [[1, 2], [3, 4]]
# 生成多项式特征
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
print(X_poly)
输出
[[ 1. 1. 2. 1. 2. 4.]
[ 1. 3. 4. 9. 12. 16.]]
4.2 交互特征构造
import pandas as pd
# 示例数据
data = {'feature1': [1, 3], 'feature2': [2, 4]}
df = pd.DataFrame(data)
# 添加交互特征
df['interaction'] = df['feature1'] * df['feature2']
print(df)
输出
feature1 feature2 interaction
0 1 2 2
1 3 4 12
六·案例分析
4.1 案例一:房价预测
数据集介绍
房价预测案例通常使用的是波士顿房价数据集(Boston Housing Dataset)或Kaggle的房价预测竞赛数据集。这些数据集包含多个特征,如房屋的面积、房间数量、地理位置等,目标是预测房屋的价格。
特征工程过程
-
数据清洗:
- 处理缺失值:使用均值或中位数填充缺失值。
- 异常值处理:识别并处理异常值,避免对模型训练产生误导。
-
特征提取:
- 从原始数据中提取新的特征,例如从房屋的总面积中提取居住面积、从地理位置中提取距离市中心的距离等。
-
特征选择:
- 使用相关性分析、卡方检验等方法选择与目标变量(房价)相关的特征。
- 使用递归特征消除(RFE)等方法进一步筛选特征。
-
特征转换:
- 标准化:将特征值转换为均值为0,标准差为1的分布。
- 归一化:将特征值缩放到[0,1]区间。
- 对数变换:对特征值取对数,减少数据的偏态。
-
特征构造:
- 构造新的特征,例如每户的房间数、每户的人口数等。
模型训练与评估
-
模型选择:
- 选择合适的模型,如线性回归、决策树、随机森林等。
- 使用交叉验证评估模型的性能。
-
模型训练:
- 使用训练数据集训练模型。
-
模型评估:
- 使用测试数据集评估模型的性能,常用的评估指标包括均方误差(MSE)、R²分数等。
示例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 加载数据集
data = pd.read_csv('housing.csv')
# 特征工程
# 数据清洗
data.fillna(data.mean(), inplace=True)
# 特征提取
data['rooms_per_household'] = data['total_rooms'] / data['households']
data['population_per_household'] = data['population'] / data['households']
# 特征选择
X = data[['median_income', 'total_rooms', 'housing_median_age', 'rooms_per_household', 'population_per_household']]
y = data['median_house_value']
# 特征转换
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差(MSE):{mse}")
print(f"R²分数:{r2}")
4.2 案例二:文本分类
数据集介绍
文本分类案例通常使用的是电影评论数据集(IMDB Dataset)或新闻分类数据集(20 Newsgroups Dataset)。这些数据集包含文本数据和对应的类别标签,目标是将文本分类到预定义的类别中。
特征工程过程
-
数据清洗:
- 去除文本中的标点符号、数字和特殊字符。
- 将文本转换为小写。
-
特征提取:
- 使用TF-IDF、Word2Vec或BERT等方法提取文本特征。
-
特征选择:
- 使用卡方检验、互信息等方法选择与目标变量(类别)相关的特征。
-
特征转换:
- 标准化:将特征值转换为均值为0,标准差为1的分布。
- 归一化:将特征值缩放到[0,1]区间。
模型训练与评估
-
模型选择:
- 选择合适的模型,如逻辑回归、支持向量机(SVM)、随机森林等。
- 使用交叉验证评估模型的性能。
-
模型训练:
- 使用训练数据集训练模型。
-
模型评估:
- 使用测试数据集评估模型的性能,常用的评估指标包括准确率、召回率、F1分数等。
示例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集
data = pd.read_csv('imdb_reviews.csv')
# 特征工程
# 数据清洗
data['review'] = data['review'].str.replace('[^a-zA-Z]', ' ').str.lower()
# 特征提取
vectorizer = TfidfVectorizer(max_features=5000)
X = vectorizer.fit_transform(data['review'])
# 特征选择
# 使用卡方检验选择特征
# 这里假设已经选择了前1000个特征
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, data['sentiment'], test_size=0.2, random_state=42)
# 模型训练
model = LogisticRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"准确率:{accuracy}")
print(f"分类报告:\n{report}")
七·结语
特征工程是机器学习中的一项关键技能,它能够显著提升模型的性能和泛化能力。通过本文的介绍,我们深入了解了特征工程的目标、主要步骤以及在实际案例中的应用。希望这些内容能够激发你在自己的项目中尝试和应用特征工程,从而提升你的模型表现。


















 2253
2253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











