






线性分类笔记
一、线性分类器简介
我们将要实现一种更强大的方法来解决图像分类问题,该方法可以自然地延伸到神经网络和卷积神经网络上。这种方法主要有两部分组成:
①评分函数(score function),它是原始图像数据到类别分值的映射;
②损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。
二、线性评分函数(score function)
⑴ 含义
这个函数将图像的像素值映射为各个分类类别的得分,得分高低代表图像属于该类别的可能性高低。
⑵ 线性映射
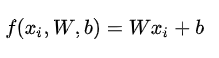
在该公式中,参数W被称为权重(weights),b被称为偏差向量(bias vector)。假设每个图像数据都被拉长为一个长度为D的列向量,大小为[D x 1]。其中大小为[K x D]的矩阵W和大小为[K x 1]列向量b为该函数的参数(parameters)
注意:
①一个单独的矩阵乘法Wxi就可以高效地并行评估10个不同的分类器(每个分类器针对一个分类),其中每个类的分类器就是W的一个行向量。
②我们认为输入数据(xi ,yi)是给定且不可改变的,但参数W和b是可控制改变的。我们的目标就是通过设置这些参数,使得计算出来的分类分值情况和训练集中图像数据的真实类别标签相符。
③该方法的一个优势是训练数据是用来学习到参数W和b的,一旦训练完成,训练数据就可以丢弃,留下学习到的参数即可。
④只需要做一个矩阵乘法和一个矩阵加法就能对一个测试数据分类,这比k-NN中将测试图像和所有训练数据做比较的方法快多了。
一个将图像映射到分类分值的例子:为了便于可视化,假设图像只有4个像素(都是黑白像素,这里不考虑RGB通道),有3个分类(红色代表猫,绿色代表狗,蓝色代表船,注意,这里的红、绿和蓝3种颜色仅代表分类,和RGB通道没有关系),首先将图像像素拉伸为一个列向量,与W进行矩阵乘,然后得到各个分类的分值。可以看出这个W一点也不好,猫分类的分值非常低,从上图来看,算法倒是觉得这个图像是一只狗。

将图像看做高维度的点:既然图像被伸展成为了一个高维度的列向量,那么我们可以把图像看做这个高维度空间中的一个点。整个数据集就是一个点的集合,每个点都带有1个分类标签。
既然定义每个分类类别的分值是权重和图像的矩阵乘,那么每个分类类别的分数就是这个空间中的一个线性函数的函数值。我们没办法可视化高维空间中的线性函数,但假设把这些维度挤压到二维,那么就可以看看这些分类器在做什么了:
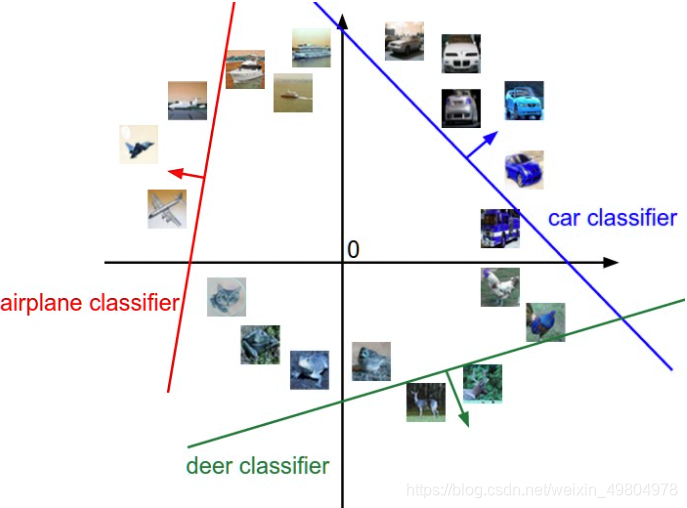
图像空间的示意图。其中每个图像是一个点,有3个分类器。以红色的汽车分类器为例,红线表示空间中汽车分类分数为0的点的集合,红色的箭头表示分值上升的方向。所有红线右边的点的分数值均为正,且线性升高。红线左边的点分值为负,且线性降低。
W的每一行都是一个分类类别的分类器。对于这些数字的几何解释是:如果改变其中一行的数字,会看见分类器在空间中对应的直线开始向着不同方向旋转。而偏差b,则允许分类器对应的直线平移。需要注意的是,如果没有偏差,无论权重如何,在xi=0时分类分值始终为0。这样所有分类器的线都不得不穿过原点。
将线性分类器看做模板匹配:关于权重W的另一个解释是它的每一行对应着一个分类的模板(有时候也叫作原型)。一张图像对应不同分类的得分,是通过使用内积(也叫点积)来比较图像和模板,然后找到和哪个模板最相似。从这个角度来看,线性分类器就是在利用学习到的模板,针对图像做模板匹配。从另一个角度来看,可以认为还是在高效地使用k-NN,不同的是我们没有使用所有的训练集的图像来比较,而是每个类别只用了一张图片(这张图片是我们学习到的,而不是训练集中的某一张),而且我们会使用(负)内积来计算向量间的距离,而不是使用L1或者L2距离。

以CIFAR-10为例:可以看到马的模板看起来似乎是两个头的马,这是因为训练集中的马的图像中马头朝向各有左右造成的,线性分类器将这两种情况融合到一起了。类似的,汽车的模板看起来也是将几个不同的模型融合到了一个模板中,并以此来分辨不同方向不同颜色的汽车。这个模板上的车是红色的,这是因为CIFAR-10中训练集的车大多是红色的。线性分类器对于不同颜色的车的分类能力是很弱的,但是后面可以看到神经网络是可以完成这一任务的,神经网络可以在它的隐藏层中实现中间神经元来探测不同种类的车(比如绿色车头向左,蓝色车头向前等),而下一层的神经元通过计算不同的汽车探测器的权重和,将这些合并为一个更精确的汽车分类分值。
图像数据预处理:在上面的例子中,所有图像都是使用的原始像素值(从0到255)。在机器学习中,对于输入的特征做归一化(normalization)处理是常见的套路。而在图像分类的例子中,图像上的每个像素可以看做一个特征。在实践中,对每个特征减去平均值来中心化数据是非常重要的。在这些图片的例子中,该步骤意味着根据训练集中所有的图像计算出一个平均图像值,然后每个图像都减去这个平均值,这样图像的像素值就大约分布在[-127, 127]之间了。下一个常见步骤是,让所有数值分布的区间变为[-1, 1]。零均值的中心化是很重要的,等我们理解了梯度下降后再来详细解释。
⑶ 偏差和权重的合并技巧
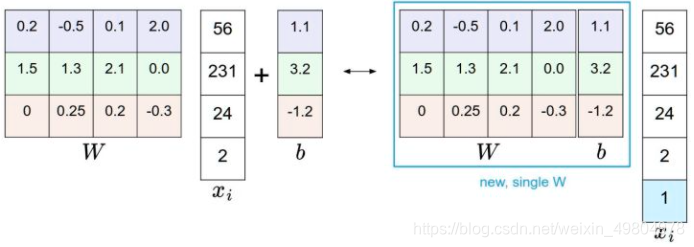
分开处理这权重参数与偏差参数有点笨拙,一般常用的方法是把两个参数放到同一个矩阵中,同时xi向量就要增加一个维度,这个维度的数值是常量1,这就是默认的偏差维度。这样新的公式就简化成下面这样:
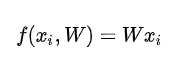
以CIFAR-10为例,说明偏差技巧的示意图。左边是先做矩阵乘法然后做加法,右边是将所有输入向量的维度增加1个含常量1的维度,并且在权重矩阵中增加一个偏差列,最后做一个矩阵乘法即可。左右是等价的。通过右边这样做,我们就只需要学习一个权重矩阵,而不用去学习两个分别装着权重和偏差的矩阵了。
三、损失函数(loss function)
⑴ 目的
损失函数有时也叫代价函数Cost Function或目标函数Objective,用来衡量我们对结果的不满意程度。直观地讲,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
⑵ 分类
多类支持向量机损失 Multiclass Support Vector Machine Loss
第i个数据的多类SVM的损失函数定义如下:
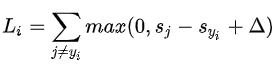
举例:假设有3个分类,并且得到了分值s=[13,-7,11]。其中第一个类别是正确类别,即yi=0。同时假设△是10(后面会详细介绍该超参数)。上面的公式是将所有不正确分类加起来,得到两个部分:
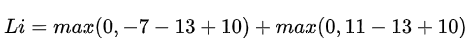
第一个部分结果是0,这是因为[-7-13+10]得到的是负数,经过max(0,-)函数处理后得到0。这一对类别分数和标签的损失值是0,这是因为正确分类的得分13与错误分类的得分-7的差为20,高于边界值10。而SVM只关心差距至少要大于10,更大的差值还是算作损失值为0。第二个部分计算[11-13+10]得到8。虽然正确分类的得分比不正确分类的得分要高(13>11),但是比10的边界值还是小了,分差只有2,这就是为什么损失值等于8。简而言之,SVM的损失函数想要正确分类类别yi的分数比不正确类别分数高,而且至少要高△。如果不满足这点,就开始计算损失值。
面对线性评分函数(f(xi,W)=W xi),可以将损失函数的公式稍微改写一下:(其中wj是权重W的第j行,被变形为列向量)
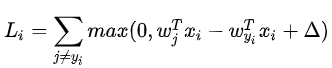
补充:
关于0的阀值max(0,-)函数,它常被称为折叶损失(hinge loss)。有时候会听到人们使用平方折叶损失SVM(即L2-SVM),它使用的是max(0,-)²,将更强烈地惩罚过界的边界值。不使用平方是更标准的版本,但是在某些数据集中,平方折叶损失会工作得更好。可以通过交叉验证来决定到底使用哪个。
正则化:我们希望能向某些特定的权重W添加一些偏好,对其他权重则不添加,以此来消除模糊性。方法是向损失函数增加一个正则化惩罚(regularization penalty)R(W)部分。最常用的正则化惩罚是L2范式,L2范式通过对所有参数进行逐元素的平方惩罚来抑制大数值的权重:
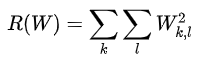
该表达式中,将W中所有元素平方后求和。注意正则化函数不是数据的函数,仅基于权重。包含正则化惩罚后,就能够给出完整的多类SVM损失函数了,它由两个部分组成:数据损失(data loss),即所有样例的的平均损失Li,以及正则化损失(regularization loss)。完整公式如下所示:
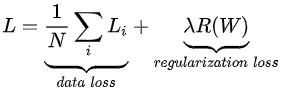
将其展开完整公式为:(其中N是训练集的数据量)
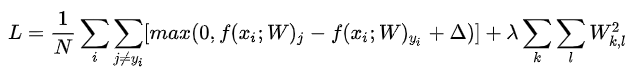
现在正则化惩罚添加到了损失函数里面,并用超参数λ来计算其权重,该超参数无法简单确定,需要通过交叉验证来获取。引入正则化惩罚还带来很多良好的性质,比如引入L2惩罚后,SVM就有了最大边界(max margin),而且对大数值权重进行惩罚可以提升其泛化能力,这就意味着没有哪个维度能够独自对于整体分值有过大的影响。
△超参数在绝大多数情况下设为△=1.0都是安全的。超参数△和λ看起来是两个不同的超参数,但实际上他们一起控制同一个权衡:即损失函数中的数据损失和正则化损失之间的权衡。权重W的大小对于分类分值有直接影响,将W值缩小,分类分值之间的差异也变小,反之亦然。因此,不同分类分值之间的边界的具体值(比如△=1或△=100)从某些角度来看是没意义的,因为权重自己就可以控制差异变大和缩小。也就是说,真正的权衡是我们允许权重能够变大到何种程度(通过正则化强度λ来控制)。
②Softmax分类器
在Softmax分类器中,函数映射f(xi;W)=W xi 保持不变,但将这些评分值视为每个分类的未归一化的对数概率,并且将折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss)。公式如下:
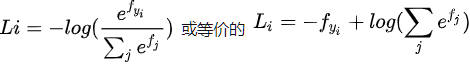

⑶SVM和Softmax的比较
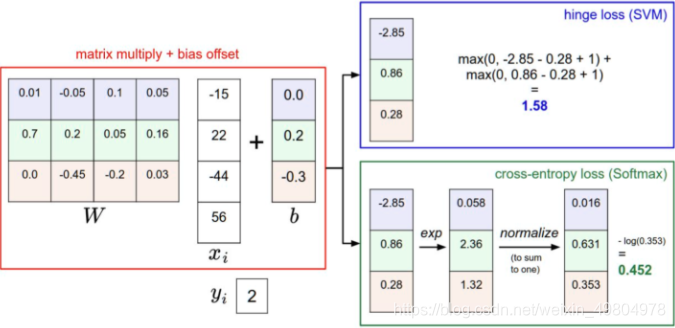
针对一个数据点,SVM和Softmax分类器的不同处理方式的例子:两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
在实际使用中,SVM和Softmax经常是相似的
①通常说来,两种分类器的表现差别很小,不同的人对于哪个分类器更好有不同的看法。相对于Softmax分类器,SVM更加“局部目标化(local objective)”,这既可以看做是一个特性,也可以看做是一个劣势。考虑一个评分是[10, -2, 3]的数据,其中第一个分类是正确的。那么一个SVM(△=1)会看到正确分类相较于不正确分类,已经得到了比边界值还要高的分数,它就会认为损失值是0。SVM对于数字个体的细节是不关心的:如果分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没设么不同,只要满足超过边界值等于1,那么损失值就等于0。
②对于softmax分类器,情况则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。换句话来说,softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。这可以被看做是SVM的一种特性。举例说来,一个汽车的分类器应该把他的大量精力放在如何分辨小轿车和大卡车上,而不应该纠结于如何与青蛙进行区分,因为区分青蛙得到的评分已经足够低了。
四、小结
①定义了从图像像素映射到不同类别的分类评分的评分函数。在本节中,评分函数是一个基于权重W和偏差b的线性函数。
②kNN分类器不同,参数方法的优势在于一旦通过训练学习到了参数,就可以将训练数据丢弃了。同时该方法对于新的测试数据的预测非常快,因为只需要与权重W进行一个矩阵乘法运算。
③介绍了偏差技巧,让我们能够将偏差向量和权重矩阵合二为一,然后就可以只跟踪一个矩阵。
④定义了损失函数(介绍了SVM和Softmax线性分类器最常用的2个损失函数)。损失函数能够衡量给出的参数集与训练集数据真实类别情况之间的一致性。在损失函数的定义中可以看到,对训练集数据做出良好预测与得到一个足够低的损失值这两件事是等价的。
(注:本读书笔记总结自 贺完结!CS231n官方笔记授权翻译总集发布)

















 2801
2801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









