






0. 论文信息
标题:DOC-Depth: A novel approach for dense depth ground truth generation
作者:Simon de Moreau, Mathias Corsia, Hassan Bouchiba, Yasser Almehio, Andrei Bursuc, Hafid El-Idrissi, Fabien Moutarde
机构:Mines Paris - PSL University、Valeo、Exwayz Research
原文链接:https://arxiv.org/abs/2502.02144
代码链接:https://github.com/SimondeMoreau/DOC-Depth
数据集链接:https://simondemoreau.github.io/DOC-Depth/#Dataset
1. 导读
精确的深度信息对于许多计算机视觉应用是必不可少的。然而,没有可用的数据集记录方法允许在大规模动态环境中进行完全密集的精确深度估计。在本文中,我们介绍了DOC-Depth,这是一种新颖、高效且易于部署的方法,用于从任何激光雷达传感器生成密集深度。在使用激光雷达里程计重建一致的密集3D环境后,我们借助DOC(我们最先进的动态对象分类方法)自动解决动态对象遮挡问题。此外,DOC-Depth是快速和可扩展的,允许在大小和时间方面创建无限的数据集。我们在KITTI数据集上展示了我们的方法的有效性,将其密度从16.1%提高到71.2%,并发布了这一新的全密度深度注释,以促进该领域的未来研究。我们还展示了在多种环境中使用各种激光雷达传感器的结果。
2. 效果展示
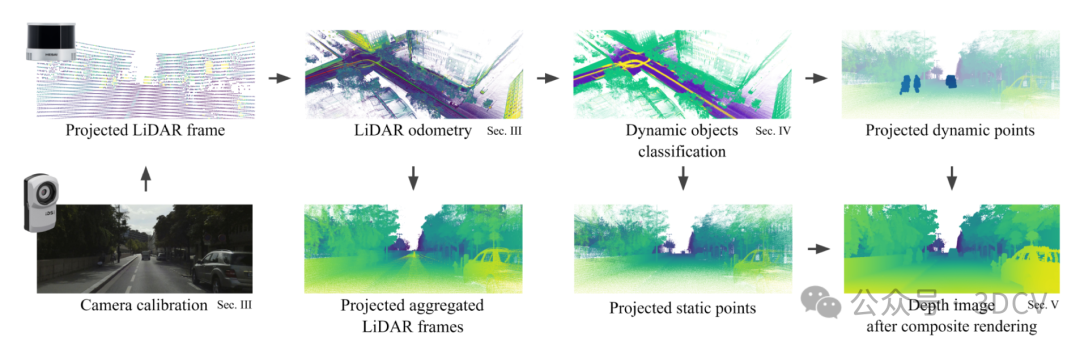
DOC-Depth为训练基于相机的深度估计系统生成密集和准确的深度地面真相。首先,我们汇总激光雷达帧以获取场景的3D密集表示。然后,由于DOC,我们分类动态点以使用特定渲染处理它们。最后,我们考虑点的距离和动态对象的遮挡,将3D重建投影到相机视点。
3. 主要贡献
我们的方法产生高质量、全密集的深度。由于采用了一种无学习、基于几何和与LiDAR无关的方法,它在各种LiDAR和环境中都能很好地推广。
我们提出了DOC,一种新颖、快速且可扩展的动态对象分类方法,其性能优于最先进的方法。
我们为KITTI深度完成发布了新的全密集注释[7和航速数据集[81.我们的方法易于部署,甚至与低成本低分辨率LiDAR兼容。这为可扩展生成大型深度估计数据集开辟了道路。
我们公开提供所有软件组件。
4. 实验结果
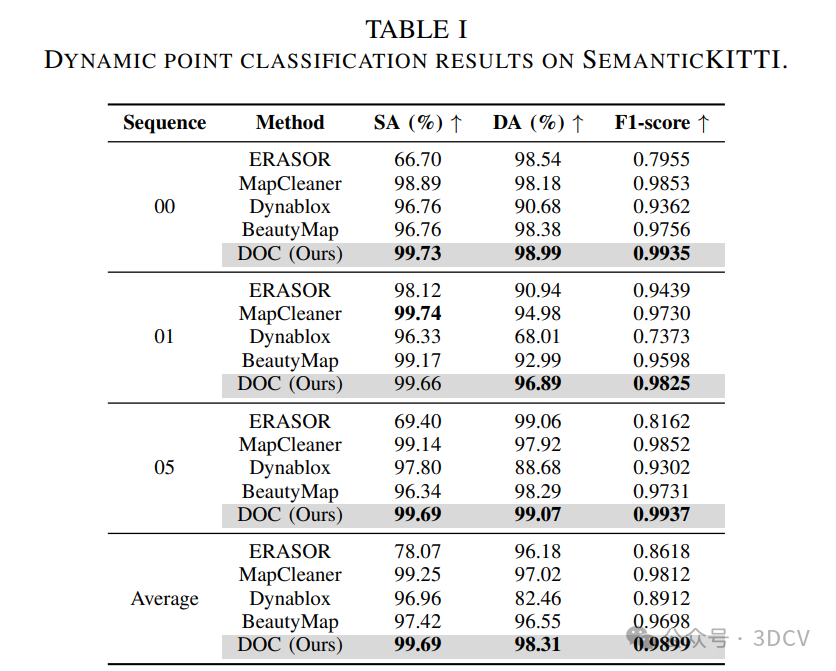
.KITTI深度补全和DOC-Depth之间的定性比较。我们的方法保留了所有场景结构,而KITTI由于SGM验证而缺乏无纹理的墙壁和薄物体。KITTI的地面不平整,有较大的间隙,移动物体被扫描聚合重复。相比之下,DOC-epth确保了准确的动态物体重建和整个深度范围内一致的几何形状。

5. 总结
我们引入了DOC-Depth,这是一种在无限动态环境中生成密集深度地面真值的新方法。由于DOC,我们提出的动态对象分类器,我们可以自动处理图像中的物体遮挡。我们在KITTI和内部捕获的4种不同激光雪达类型的数据集上展示了我们方法的有效性。通过使用各种传感器创建新数据集,我们展示了其泛化性和部署的便利性。我们发布了KITTI深度完成和测距数据集的完全密集注释,从而可以在深度估计和完成方面进行进一步探索。软件组件可供研究界使用。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









