






1. 导读
最近的VO方法通过使用深度网络来预测视频帧之间的光流,显著提高了性能。然而,现有的方法仍然受到噪声和不一致的流匹配的影响,使得难以处理具有挑战性的场景和长序列估计。为了克服这些挑战,我们引入了时空视觉里程计(STVO),这是一种新的深度网络架构,可以有效地利用固有的时空线索来增强多帧流匹配的准确性和一致性。通过更精确和一致的流匹配,STVO可以通过束调整(BA)实现更好的姿态估计。具体来说,STVO引入了两个创新组件:1)时间传播模块,该模块利用多帧信息来跨相邻帧提取和传播时间线索,从而保持时间一致性;2)空间激活模块,其利用来自深度图的几何先验来增强空间一致性,同时过滤掉过多的噪声和不正确的匹配。我们的STVO在TUM-RGBD、EuRoc MAV、ETH3D和KITTI里程计基准测试中实现了一流的性能。值得注意的是,与以前的最佳方法相比,它在ETH3D基准上提高了77.8%,在KITTI里程计基准上提高了38.9%。
标题:Leveraging Consistent Spatio-Temporal Correspondence for Robust Visual Odometry
作者:Zhaoxing Zhang, Junda Cheng, Gangwei Xu, Xiaoxiang Wang, Can Zhang, Xin Yang
机构:Huazhong University of Science and Technology、Huazhong University of Science and Technology
原文链接:https://arxiv.org/abs/2412.16923
2. 引言
视觉里程计(VO)是通过分析来自视觉传感器的数据来估算机器人位置和姿态的关键技术。经典视觉里程计方法利用优化技术,或通过最小化像素强度的光度误差,或通过最小化对应点的重投影误差,来估计轨迹。然而,由于匹配能力有限,经典方法经常遇到鲁棒性问题,尤其是在图像缺乏明显特征点或光度一致性假设不成立的情况下。
在过去十年中,人们开始转向使用端到端深度学习方法,这些方法将视觉输入直接映射到姿态。端到端深度学习方法可以实现更稳定的匹配,但神经网络往往难以直接从高维特征预测6自由度姿态。因此,与具有强大几何约束的经典优化后端相比,其准确性通常较低。
为解决这些局限性,混合视觉里程计框架应运而生,该框架结合了经典方法与深度学习技术的优势。这些框架首先利用神经网络预测流对应,然后通过几何优化使用这些对应进行姿态估计。通过将深度学习的强大匹配能力与经典几何约束相结合,混合视觉里程计框架显著减少了过拟合,提高了鲁棒性和准确性。然而,由于对应估计对混合视觉里程计系统的鲁棒性至关重要,现有混合方法中持续存在的噪声和不一致流匹配问题导致性能显著下降,尤其是在具有挑战性的场景中。此外,视觉里程计系统通常会出现累积轨迹漂移,这些问题会加剧漂移,导致在长序列中估计越来越不准确。
现有混合方法仅依赖两帧之间的信息来获得对应。然而,仅从两帧估计的流容易受到噪声和不一致性的影响,尤其是在具有挑战性的区域。这些方法忽略了视觉里程计系统能够在局部窗口内联合估计多帧姿态的潜力,这也可以用于多帧联合光流估计。通过最优地整合时空线索,这种方法可以显著提高光流的准确性和鲁棒性。在空间和时域中获得更一致的流匹配后,视觉里程计可以通过捆集调整(BA)步骤实现更好的姿态估计。这一见解基于两个关键观察结果,如图2所示。首先,多帧之间存在时间一致性,相邻帧具有相似的运动趋势,并受到流一致性的约束。其次,每帧都表现出空间一致性,即同一对象上的不同点保持高度一致的运动模式。
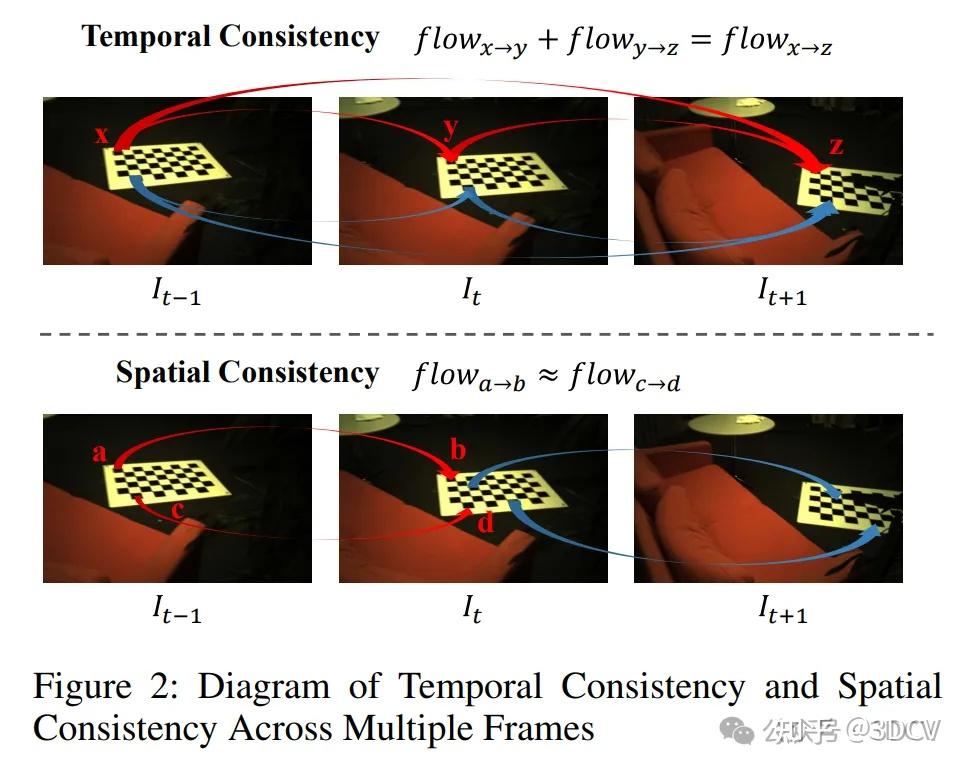
基于这些观察结果,我们引入了时空视觉里程计(STVO),这是一种新的深度网络架构,通过整合时空线索来优化多帧光流匹配。首先,我们引入了一个时间传播模块,该模块利用多帧信息来提取和传播相邻帧之间的时间线索。时间传播模块为每个源帧维护一个运动状态,并使用当前预测的光流迭代地将运动状态扭曲到所有相邻帧中,从而准确反映运动动态。最后,从相邻帧获得的时间信息被传播回源帧,并更新用于下一次迭代的运动状态。其次,我们引入了空间激活模块。该模块创新性地利用深度信息和几何先验来增强流估计中的空间一致性。它利用深度图提供的几何信息创建空间注意力矩阵,该矩阵采用基于注意力的方法来建模空间线索。然后,空间注意力矩阵被用于激活粗略上下文和相关特征,从而实现全面的空间理解,并过滤掉噪声和错误匹配。
大量实验表明,我们的STVO在所有四个现实世界基准测试中均优于以往工作。具体而言,在具有挑战性的ETH3D数据集上,STVO相比之前的最佳方法提高了77.8%。此外,在长序列KITTI里程计基准测试中,它相比之前的最佳方法实现了38.9%的改进。
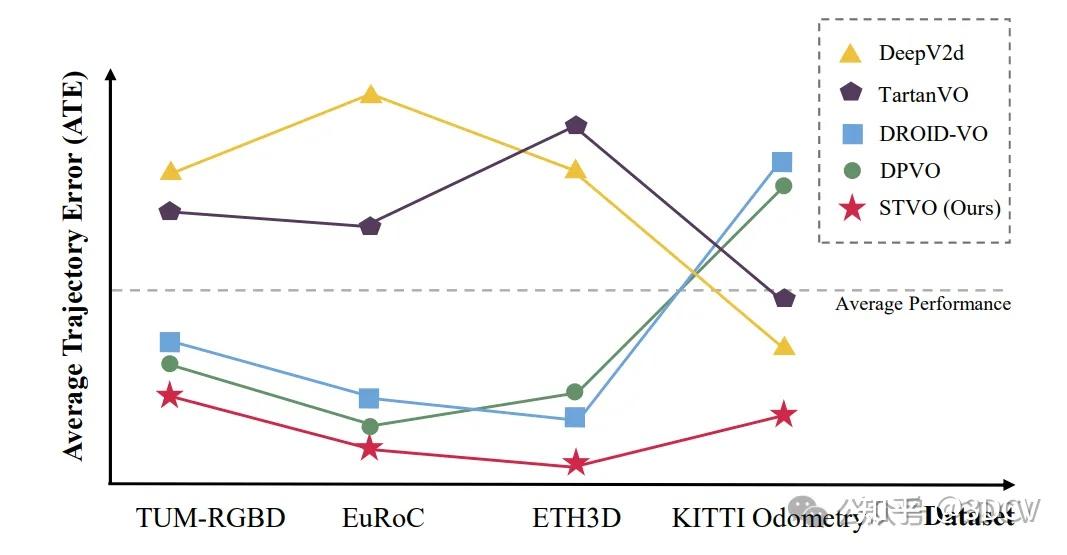
3. 效果展示
STVO与其他有影响力的测量方法的比较。我们的STVO以红星表示,在所有基准测试中都取得了最先进的性能。
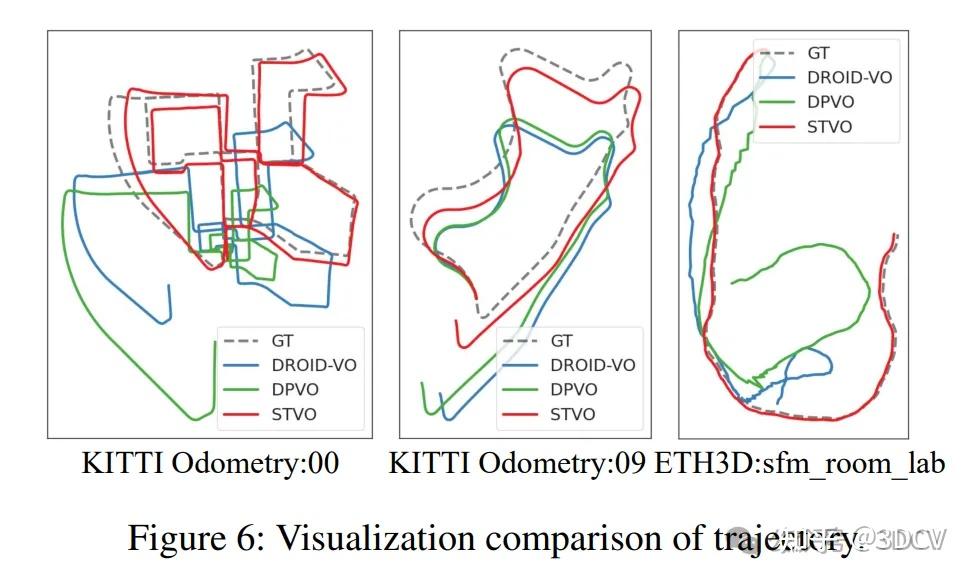
定位轨迹对比:
4. 主要贡献
我们的主要贡献如下:
• 据我们所知,我们首次强调了空间和时间一致性在视觉里程计匹配中的重要性。我们引入了时空视觉里程计(STVO),这是一种新的深度网络架构,利用时空线索来减轻具有挑战性场景和长序列估计中的性能下降。
• 我们提出了时间传播模块,该模块利用相邻帧之间的高度相关性来增强时间一致性。
• 我们提出了空间激活模块,该模块利用深度信息和几何先验来维持空间一致性,并过滤掉噪声和错误匹配。
• 我们的STVO在TUM-RGBD、EuRoC MAV、ETH3D和KITTI里程计四个基准测试中实现了最先进的准确性,同时在具有挑战性的条件下展现出卓越性能,并对长序列中的漂移表现出优异的抵抗性。
5. 方法
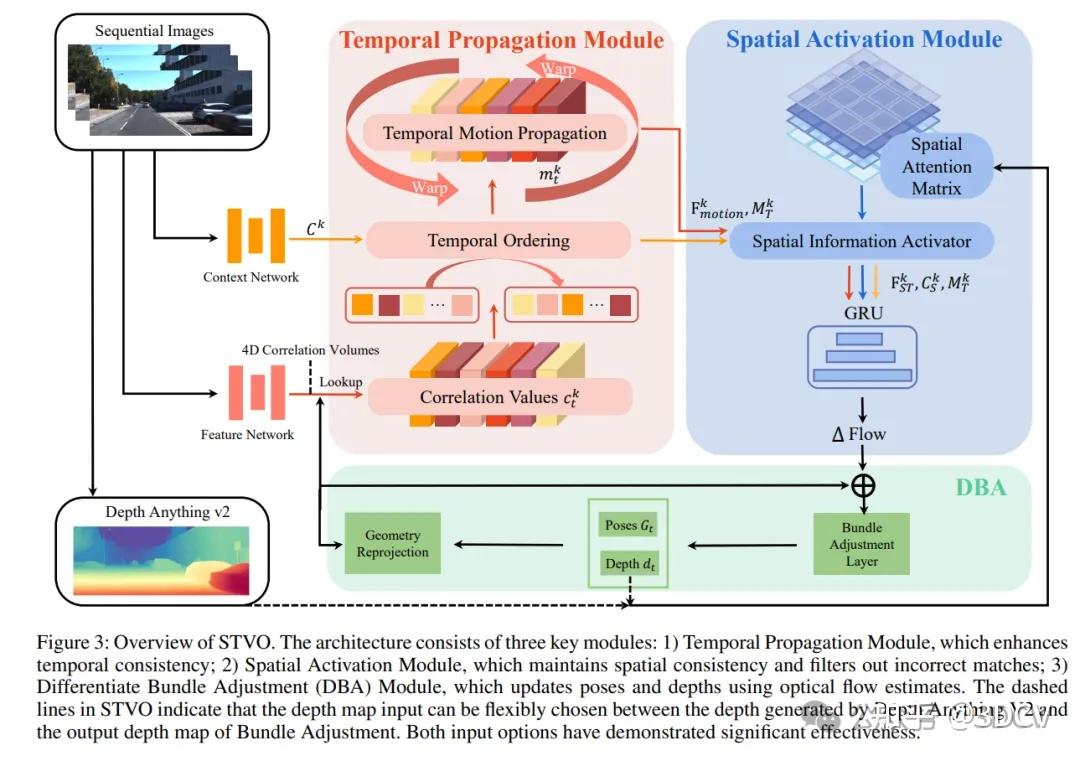
图3展示了我们的网络整体架构。STVO包括四个主要步骤:1)特征提取网络,提取用于计算光流代价体积并生成相关值的特征。2)时间传播模块,通过对相关值施加时间一致性约束,获得更鲁棒的匹配代价。3)空间激活模块,将空间一致性约束应用于相关值以导出最终匹配代价体积,然后通过GRU模块获得修正流。4)可微捆集调整(DBA)模块,DBA模块利用精细的光流来优化深度和姿态。优化后的深度和姿态随后用于几何重投影,为下一次迭代提供初始光流估计,从而创建一个正反馈循环。STVO的关键贡献在于两个主要组件:时间传播模块和空间激活模块,这两个组件可以相互补充以实现更稳定的光流,进一步增强正反馈循环的潜力,并提高姿态估计的准确性。
6. 实验结果
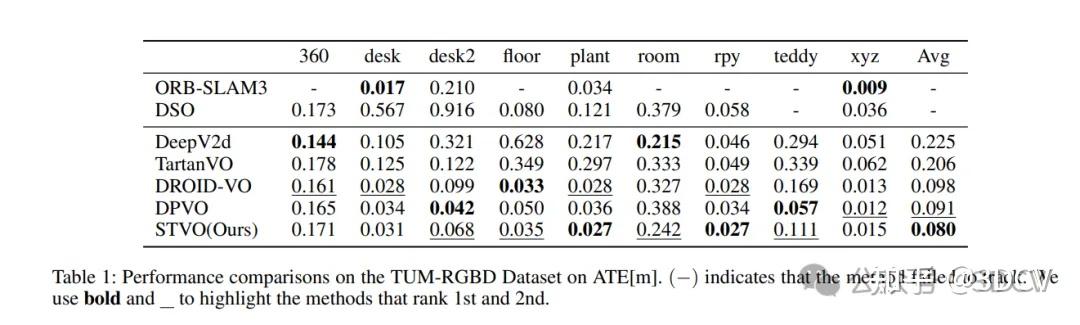
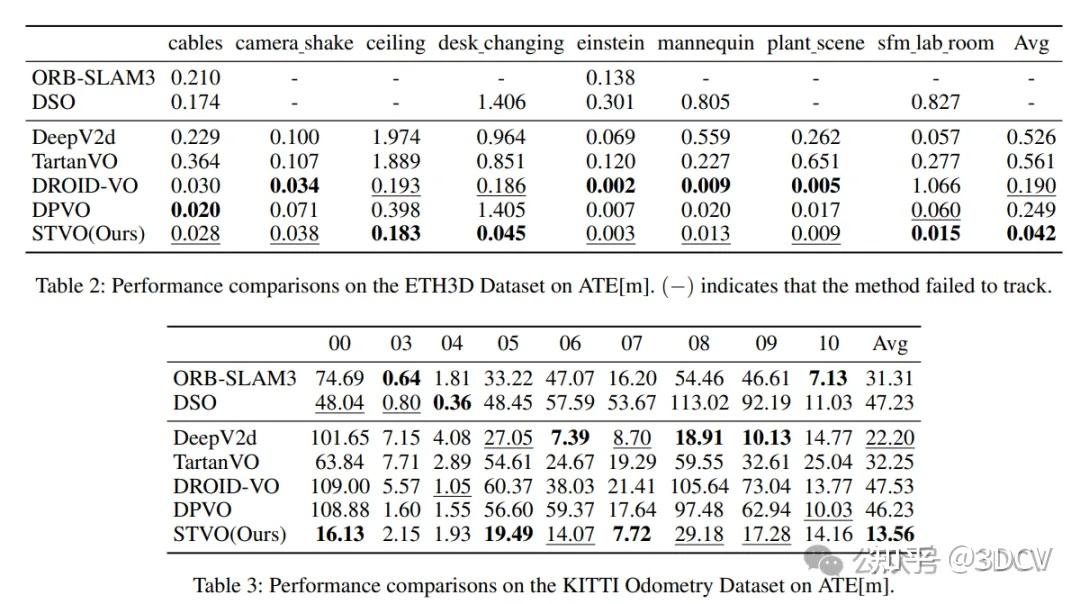
7. 总结
我们提出了STVO,这是一种新颖的深度视觉里程计架构,整合了时空线索,以增强多帧匹配中的时空一致性,有效地缓解了在具有挑战性的场景和长序列估计中的性能下降。STVO在TUM-RGBD、EUROCMAV、ETH3D和KITTlOdometry上优于所有先前的方法。STVO是第一个强调多帧流匹配中时空一致性在视觉里程计中的重要性。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









