






0. 这篇文章干了啥?
近年来,如神经辐射场(Neural Radiance Fields, NeRF)和3D高斯溅射(3D Gaussian Splatting)等新型视图合成技术,彻底改变了合成场景和现实世界场景的重构方式。这些技术仅通过训练几十张已知相机姿态的图像,就能从新颖的视角提供高质量的场景渲染。它们的表示方式成为执行标准计算机视觉任务(如目标检测或分割)的2D和3D领域之间的中间域,为各种应用铺平了道路。例如,拥有NeRF模型并直接对其应用下游识别技术,相比于跨单张图片进行相同分析,可以更容易地进行检查和评估。
车辆检查任务近年来因其能为汽车行业和服务提供商带来的好处而备受关注。其目的是从一系列图像开始,生成特定车辆实例从不同角度的高质量渲染图。这正是NeRF模型在其最广泛的形式下试图实现的目标,尽管它侧重于车辆实例。在没有专家现场检查的情况下,促进对它们的细致检查对于汽车制造商确定最终外部缺陷、保险公司估算事故后损失和维修成本或汽车租赁公司进行责任评估自动化来说都极为便利。
然而,将标准的新颖视图合成方法应用于车辆重构凸显了以下局限性:(i) 最近的NeRF和高斯溅射方法仍然依赖于经典的运动结构(Structure-from-Motion, SfM)管道(如COLMAP)来估计相机参数,有时甚至超过了实际下游优化的时间和资源要求;(ii) 据我们所知,没有专门的数据集可用于全面的现实世界车辆重构,评估仍然局限于合成场景。此外,车辆是计算机视觉文献中经过深入研究和建模的对象类别(例如,大规模无界场景识别和自动驾驶),这导致了一系列成熟的工作和先验知识,也可以用于车辆检查。
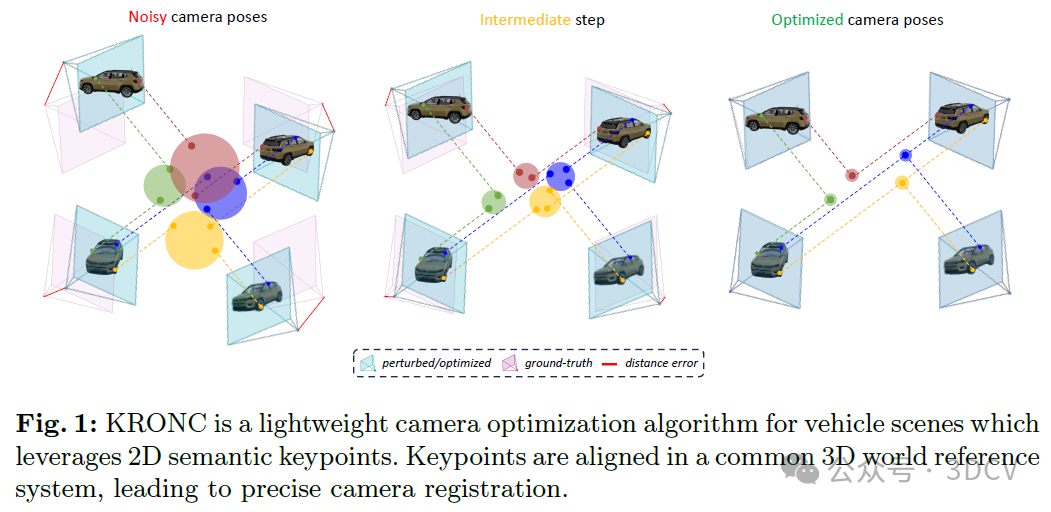
基于这些观察,本文提出了一种高效的相机帧注册算法,能够打破对繁重COLMAP式预处理的依赖。此外,我们还发布了一个新的现实世界车辆场景基准数据集(KRONC-dataset),旨在促进车辆检查中的新颖视图合成。为避免使用SfM,近期工作提出了通过联合重建神经场和注册相机帧来进行束调整NeRF(Bundle-Adjusting NeRF)。它们的优点是以将相机对齐集成到神经场优化中的代价获得的,但这并不像按顺序执行这两个步骤那样直接。我们表明,通过将这两个步骤分开,并利用比原始RGB像素轻得多的替代方案(即2D关键点)进行相机优化,可以在车辆重构中获得可比的性能,同时使计算开销可忽略不计。我们的方案结合了束调整的高效性和独立SfM包的灵活性,使其适用于不限于NeRF的每种下游新颖视图合成技术。如图1所示,我们的KRONC算法将来自多个视图的语义一致的关键点投影到共同的3D世界参考系统中,并将它们拉近。这样做是为了找出合理的相机配置和关键点的有意义深度。与增量SfM和依赖成对图像对应关系的方法不同,KRONC进行全局对齐,根据所有视点之间共享的语义关键点优化绝对相机位置(而无需任何匹配算法)。
在合成车辆场景中,我们的结果显示,在向真实姿态添加相同相机噪声并尝试恢复一致布局的情况下,我们的性能优于最先进的束调整方法。在KRONC-dataset中的真实场景中,我们使用移动设备捕捉车辆,围绕车辆进行完整的360°逆时针旋转,这是大型对象重构中捕捉场景的标准方式。在这种设置下,最先进的束调整解决方案难以收敛。通过简单地沿着手工制作的圆形轨迹粗略初始化相机姿态,我们的基于关键点的注册方法即使在输入图像数量减少75%的情况下,也能找到良好的相机布局,而COLMAP的性能则迅速下降。
下面一起来阅读一下这项工作~
1. 论文信息
标题:KRONC: Keypoint-based Robust Camera Optimization for 3D Car Reconstruction
作者:Davide Di Nucci, Alessandro Simoni, Matteo Tomei, Luca Ciuffreda, Roberto Vezzani, Rita Cucchiara
机构:University of Modena and Reggio Emilia、Prometeia
原文链接:https://arxiv.org/abs/2409.05407
代码链接:soon
2. 摘要
从一组图像开始的物体或场景的三维表示多年来一直是广泛讨论的话题,并且在基于NeRF的方法传播之后获得了额外的关注。然而,一个被低估的先决条件是相机姿态的知识,或者更具体地说,是外部校准参数的估计。虽然优秀的通用运动结构方法可用作预处理步骤,但是它们的计算负荷很高,并且它们需要大量的帧来保证视图之间的充分重叠。本文介绍了KRONC,一种新的方法,旨在通过利用关于对象的先验知识来推断视图姿态,并通过语义关键点来重建其表示。由于专注于车辆场景,KRONC能够估计视图的位置,作为针对关键点反向投影收敛到奇点的光线优化问题的解决方案。为了验证该方法,收集了真实世界汽车场景的特定数据集。实验证实了KRONC能够从非常粗略的初始化开始生成对相机姿态的出色估计。结果与从运动得到结构的方法相当,大大节省了计算量。代码和数据将公开。
3. 效果展示
4. 主要贡献
我们的贡献包括:
我们发布了KRONC-dataset,这是一个专为车辆检查背景下的新颖视图合成而设计的现实世界高质量汽车场景数据集。
我们引入了一种高效的基于关键点的相机注册(KRONC)算法,该算法在神经辐射场优化之前执行,保持两个独立步骤,与从嘈杂相机进行束调整NeRF相比,具有更高的灵活性。
在真实场景中,我们利用相机沿圆形轨迹移动捕捉场景的典型行为,以比COLMAP快一个数量级的速度恢复合理的姿态配置。
5. 基本原理是啥?
我们将讨论用于创建KRONC数据集的原始数据以及所采用的方法论。具体而言,鉴于现实环境中车辆检测相关数据的缺乏,我们详细阐述了手动收集汽车场景的具体步骤。
数据集采集
数据集是在三个不同的环境中使用不同设备收集的。对于前两个环境(Env1和Env2),我们使用了两款标准智能手机摄像头(OnePlus 7T和OnePlus Nord)进行场景拍摄。对于Env3,我们采用了一台DJI MINI 2 SE无人机进行拍照。Env1包含三个不同的场景,Env2和Env3分别包含两个额外场景,总共七个场景。每个场景代表从不同视角捕捉到的单一车辆。为了模拟实际使用场景中的用户行为,我们选择围绕车辆移动,沿着每辆车周围进行圆形路径拍摄,同时在整个注册过程中保持一致的距离。在每个视频中,都围绕车辆完成了一个完整的循环,使得最后一帧大致与第一帧相对应。每次拍摄都旨在将整个车身纳入相机的视野中。请注意,这代表了即使是从知名的3D重建服务中捕获大型有界对象的建议方式。
原始视频以30至60帧/秒(fps)的帧率拍摄,随后被下采样至5fps。为了使数据适用于SfM(Structure from Motion,从运动中恢复结构)管道和新颖视角合成处理,我们从视频中提取帧并再次进行子采样。为了完整性和未来公平比较,原始视频和选定的帧都可以在公共数据集中下载。
数据集元数据
为了利用车辆关键点进行相机外部参数优化,我们采用OpenPifPaf架自动标注了KRONC-数据集中每帧的语义关键点。具体而言,我们使用了经过训练以预测ApolloCar3D中定义的66个不同关键点的ShufflenetV2K16模型。此外,为了车辆检测的目的,我们提供了车辆实例分割掩码,以便能够丢弃不必要的背景像素。图像级掩码预测是通过在COCO全景数据集上训练的带有Swin Large骨干网的Mask2Former获得的。掩码将车辆与复杂的背景隔离开来,使得在存在挑战性环境条件下也能专注于车辆重建,但KRONC-数据集并未包含此类情况。推荐课程:Transformer如何在自动驾驶领域一统江湖!
最后,每个数据集都经过了严格的COLMAP处理,以估计精确的相机姿态。这些信息可以用作评估姿态估计方法的上限参考,突显了COLMAP的卓越精度,尤其是在图像量大的情况下。表1总结了KRONC-数据集中包含的场景、每个场景对应的图像数量以及每幅图像检测到的平均关键点数量。
KRONC算法的流程:

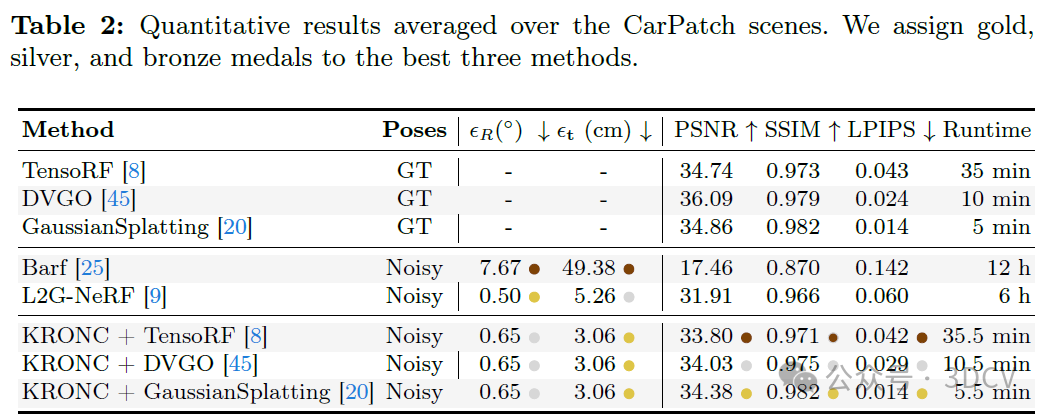
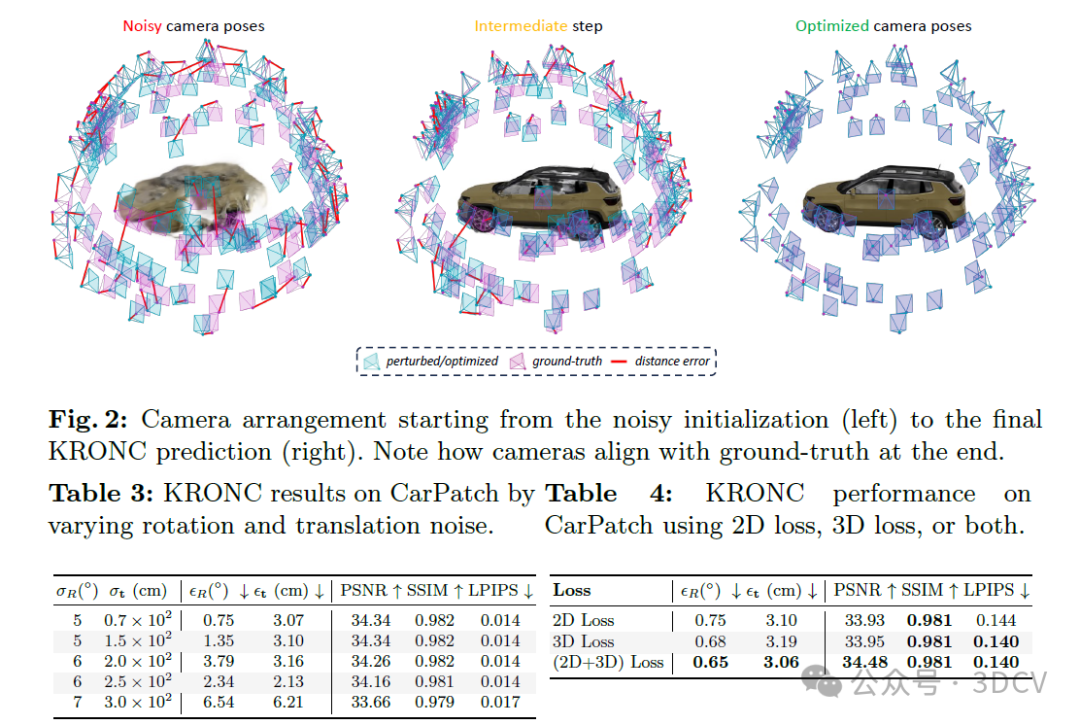
6. 实验结果
7. 总结 & 未来工作
我们提出了一种新的数据集和一种最先进的算法,以促进车辆检测任务的研究和应用。KRONC数据集代表了第一个真实车辆高质量场景集合,而KRONC算法则专门使用二维关键点作为新视角合成预处理步骤来解决相机优化问题。KRONC几乎不增加额外计算量,即可有效恢复相机姿态,获得与合成场景中使用真实相机获得的重建结果相当的结果。同样,我们仅假设相机具有初始圆形轨迹,便已在KRONC数据集中的真实场景上进行了验证。尽管KRONC算法相较于运动结构恢复(SfM)和捆绑调整(bundle-adjusting)新视角合成方法具有优势,但它仍存在一定的局限性。当使用自动检测方法提取关键点时,该算法在现实世界场景中的表现高度依赖于预测关键点的质量。此外,它至少需要相机姿态的粗略初始化,否则无法从随机值开始收敛到好的解决方案。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
8、如何发表一篇顶会论文
3D视觉工坊提供35个顶会论文的课题如下:
如何发表一篇顶会!涉及3DGS、位姿估计、SLAM、三维点云、图像增强、3D目标检测等方向
1、基于环境信息的定位,重建与场景理解
2、轻是级高保真Gaussian Splatting
3、基于大模型与GS的 6D pose estimation
4、在挑战性遮挡环境下的GS-SLAM系统研究
5、基于零知识先验的实时语义地图构建SLAM系统
6、基于3DGS的实时语义地图构建
7、基于文字特征的城市环境SLAM
8、面向挑战性环境的SLAM系统研究
9、特殊激光传感器融合视觉的稠密SLAM系统
10、基于鲁棒描述子与特征匹配的特征点法SLAM
11、基于yolo-world的语义SL系统
12、基于自监督分割的挑战性环境高斯SLAM系统
13、面向动态场景的视觉SLAM系统研究
14、面向动态场景的GS-SLAM系统研究
15、集成物体级地图的GS-SLAM系统
16、挑战场景下2D-2D,2D-3D或3D-3D配准问题
17、未知物体同时重建与位姿估计问题类别级或开放词汇位姿估计问题
18、位姿估计中的域差距问题
19、可形变对象(软体)的实时三维重建与非刚性配准
20、机器人操作可形变对象建模与仿真
21、基于图像或点云3D目标检测、语义分割、轨迹预测.
22、医疗图像分割任务的模型结构设计
23、多帧融合的单目深度估计系统研究
24、复杂天气条件下的单目深度估计系统研究高精度的单目深度估计系统研究
25、基于大模型的单目深度估计系统研究
26、高精度的光流估计系统多传感器融合的单目深度估计系统研究
27、基于扩散模型的跨域鲁棒自动驾驶场景理解
28、水下图像复原/增强
30、Real-World图像去雾(无监督/物理驱动)
31、LDR图像/视频转HDR图像/视频
32、光场图像增强/复原/超分辨率
33、压缩后图像/视频的增强/复原
34、图像色彩增强(image retouching)
9、我们一起交流
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









