






0. 论文信息
标题:Dust to Tower: Coarse-to-Fine Photo-Realistic Scene Reconstruction from Sparse Uncalibrated Images
作者:Xudong Cai, Yongcai Wang, Zhaoxin Fan, Deng Haoran, Shuo Wang, Wanting Li, Deying Li, Lun Luo, Minhang Wang, Jintao Xu
机构:Renmin University of China,、Beijing Advanced Innovation Center for Future Blockchain and Privacy Computing、Beihang University、HAOMO.AI
原文链接:https://arxiv.org/abs/2412.19518
代码链接:soon
1. 导读
在实际应用中,非常需要从稀疏视图、未标定的图像中重建出逼真的场景。虽然已经取得了一些成功,但是现有的方法或者是稀疏视图的,但是需要精确的相机参数(即,内在的和外在的),或者是无SfM的,但是需要密集捕获的图像。为了结合这两种方法的优点,同时解决它们各自的缺点,我们提出了Dust to Tower (D2T),这是一种精确有效的由粗到细的框架,可以从稀疏和未校准的图像同时优化3DGS和图像姿态。我们的主要思想是首先有效地构建一个粗略的模型,然后在新的视点使用扭曲和修复的图像对其进行细化。为了做到这一点,我们首先引入了一个粗略构造模块(CCM ),它利用快速多视图立体模型来初始化3D高斯分布(3DGS)并恢复初始相机姿态。为了在新的视点上改进3D模型,我们提出了置信度感知深度对准(CADA)模块,通过将它们的置信度部分与单深度模型的估计深度对准来改进粗略的深度图。然后,提出了扭曲图像引导的修补(WIGI)模块,以通过细化的深度图将训练图像扭曲到新的视点,并应用修补来填补由视角方向改变引起的扭曲图像中的“洞”,提供高质量的监督以进一步优化3D模型和相机姿态。大量的实验和消融研究证明了D2T及其设计选择的有效性,在保持高效率的同时,在新视图合成和姿态估计两个任务中实现了最先进的性能。代码将公开提供。
2. 效果展示
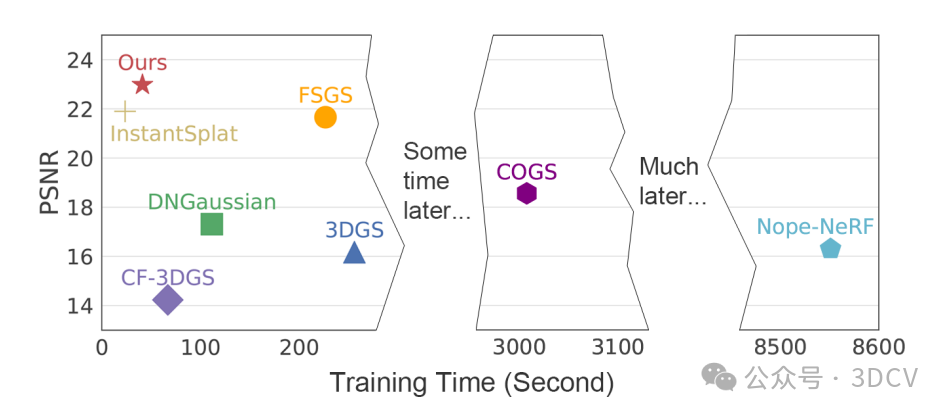
训练时间与PSNR之间的关系。我们展示了使用三种输入视图进行训练的时间和PSNR。与现有基线相比,我们的方法在效率-准确性权衡上达到了最优。
使用三个训练视图的新视图合成定性结果。我们的方法产生的渲染结果比其他方法更逼真,尤其是在遮挡区域。评估指标与地面真实值在图像的顶部和左侧绘制。

3. 方法
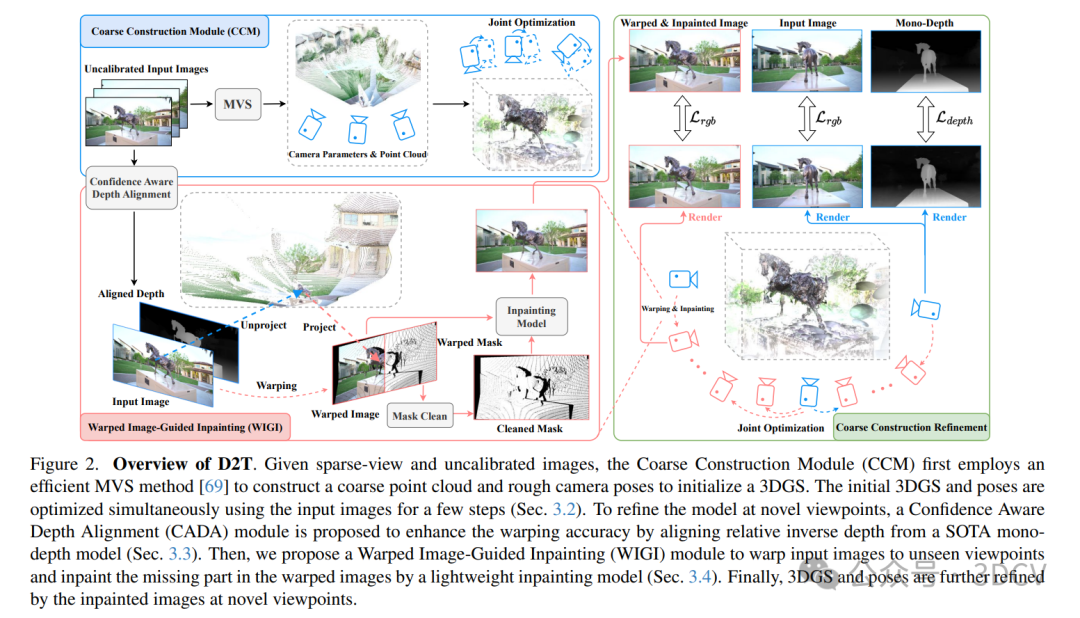
我们的核心贡献是高效地构建一个粗略模型,并使用由扭曲和补图范式生成的新视角图像对其进行细化。所提出的方法的概述如图2所示。首先,我们介绍了粗略构建模块。接下来,我们介绍了置信度感知深度对齐,它细化了粗略深度图以进行精确的扭曲。介绍了扭曲图像引导补图模块,该模块生成高质量的新视角图像,用于细化3D模型。最后,我们详细介绍了Poses和3DGS的联合优化。
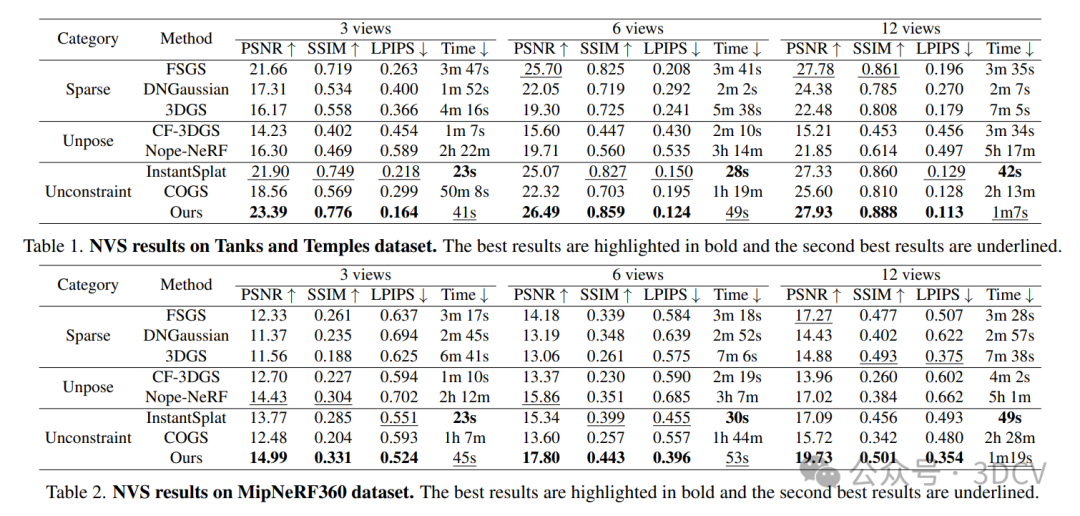
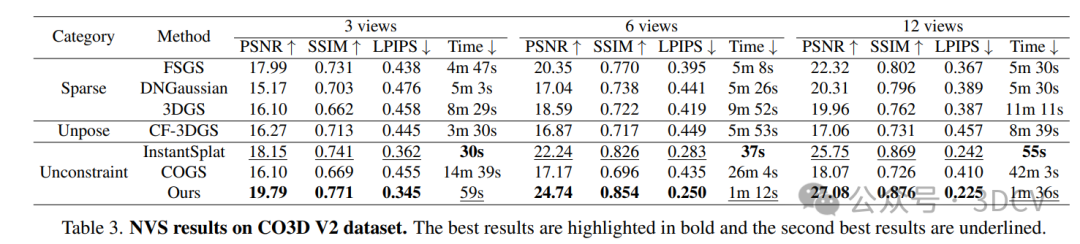
4. 实验结果
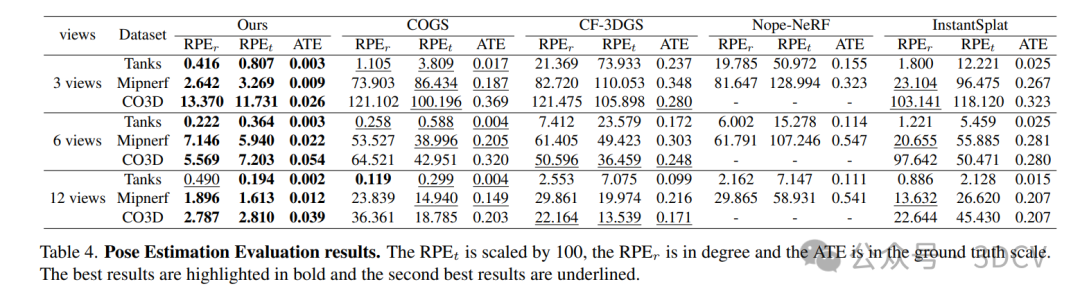
5. 总结 & 未来工作
在本文中,我们提出了D2T,这是一种新颖的由粗到精的框架,旨在利用稀疏且未校准的图像进行逼真场景重建。D2T从稀疏且未校准的图像出发,首先利用颜色一致性最大化(CCM)方法高效地构建出一个粗略的解决方案。为了优化新视角下的三维模型,我们提出了条件自适应变形(CADA)和权重指导图像修复(WIGI)方法,通过变形和图像修复来生成新视角下的图像。这两种方法已被证明在提升新视角下渲染质量方面既有效又高效。在三个数据集上的大量实验结果表明,D2T在新型视角合成(NVS)和姿态估计方面均取得了最先进的结果,且效率极高。然而,全局点云的对齐限制了D2T在利用数百张输入图像重建大规模场景方面的能力。在未来的研究中,我们将探索增量对齐范式。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









