







 文章介绍了在R语言中使用tidyr的gather和spread函数以及reshape2的melt和dcast函数进行数据的宽转长和长转宽操作。通过示例展示了转换过程,并对比了大样本量下的运算速度,发现在宽转长时melt更快,而在长转宽时spread更高效。
文章介绍了在R语言中使用tidyr的gather和spread函数以及reshape2的melt和dcast函数进行数据的宽转长和长转宽操作。通过示例展示了转换过程,并对比了大样本量下的运算速度,发现在宽转长时melt更快,而在长转宽时spread更高效。
长宽数据
在日常数据分析过程中,经常会对数据进行长宽转换处理,所谓长宽数据转换就是将数据表中的列变量进行聚合和分裂操作。宽转长:多个列聚合为一列,同时生成value值,这种操作主要是为了方便ggplot2绘图;长转宽:单个列分裂为多个列,同时生成variable变量,这种操作通常是为了导入spss进行统计分析。通常用来执行转换操作的软件包有两种,一种是tidyr包中的gather和sperad函数,一种是reshape2包中的melt和dcast函数,下面就让我们来对这两种方式进行测试比较。
宽转长
转换前数据
(例:宽数据,数据表中存在多个列变量)
转换过程
#############################长宽数据相互转换##############
rm(list = ls())
###生成测试数据###
test<-matrix(c(1201001:1201100,paste0("name",seq(1:100)),round(runif(900,80,100))),100,11,dimnames = list(c(),c("学号","姓名","数学","语文","英语","物理","化学","生物","历史","地理","政治")))%>%data.frame()
###分别载入两个软件包###
library(tidyr)
library(reshape2)
###gather函数与melt函数在宽数据转长数据处理中的应用比较####
###测试结果###
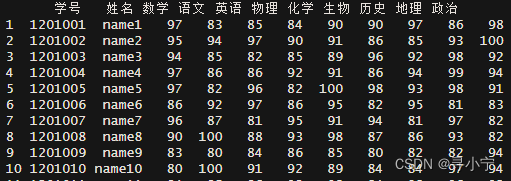
gather(test,科目,分数,names(test)[3:11])%>%head()
melt(test,id=c("学号","姓名"),variable.name = "科目",value.name = "分数")%>%head()
转换后数据
可以看出转换后各个列变量聚合到了“科目”变量下,同时将value值赋到了“分数”变量下;两个函数运算结果无差别,下面尝试用大样本量测试运算速度。
运算速度比较
###大样本测试运算速度###
test<-matrix(c(12010001:12018000,paste0("name",seq(1:8000)),round(runif(72000,80,100))),8000,11,dimnames = list(c(),c("学号","姓名","数学","语文","英语","物理","化学","生物","历史","地理","政治")))%>%data.frame()
gather(test,科目,分数,names(test)[3:11])%>%system.time()
melt(test,id=c("学号","姓名"),variable.name = "科目",value.name = "分数")%>%system.time()
可以看出在进行大样本量宽转长数据处理时melt函数用时更少

长转宽
转换前后数据同“宽转长”相反,图片不再展示
转换过程及输出结果
###spread函数与dcast函数在长数据转宽数据处理中的应用比较#####
test<-matrix(c(12010001:12018000,paste0("name",seq(1:8000)),round(runif(72000,80,100))),8000,11,dimnames = list(c(),c("学号","姓名","数学","语文","英语","物理","化学","生物","历史","地理","政治")))%>%data.frame()
py<-melt(test,id=c("学号","姓名"),variable.name = "科目",value.name = "分数")
###测试结果###
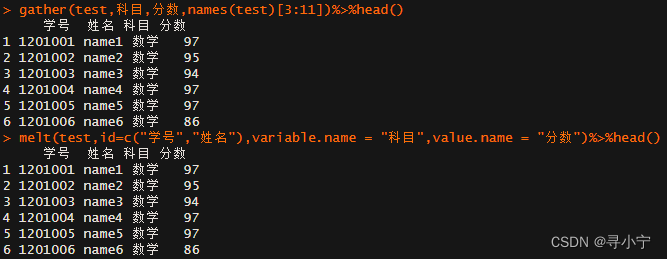
spread(py,科目,value=分数)%>%head()
dcast(py,学号+姓名~科目)%>%head()
###大样本测试运算速度###
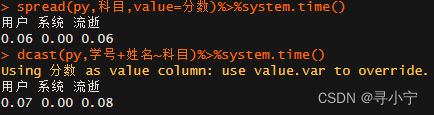
spread(py,科目,value=分数)%>%system.time()
dcast(py,学号+姓名~科目)%>%system.time()
可以看出在进行大样本量长转宽数据处理时spread函数用时更少
综上在进行长宽数据转换时可根据自身需要选取相应的函数
https://gitee.com/zhjx19/tidyverse120

















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









