








一个拥有数千亿参数的大语言模型,不仅训练成本高昂,其推理(即实际运行)过程也像一头消耗巨大的巨兽:它需要顶级的计算芯片、占用庞大的内存,并产生相当的能耗。这构成了其应用的主要瓶颈,将许多潜在用户和设备排除在外。模型压缩与优化的核心目标,正是在尽可能保持模型性能的前提下,降低其对计算资源的需求,使其更轻量、更快速、更易于部署。
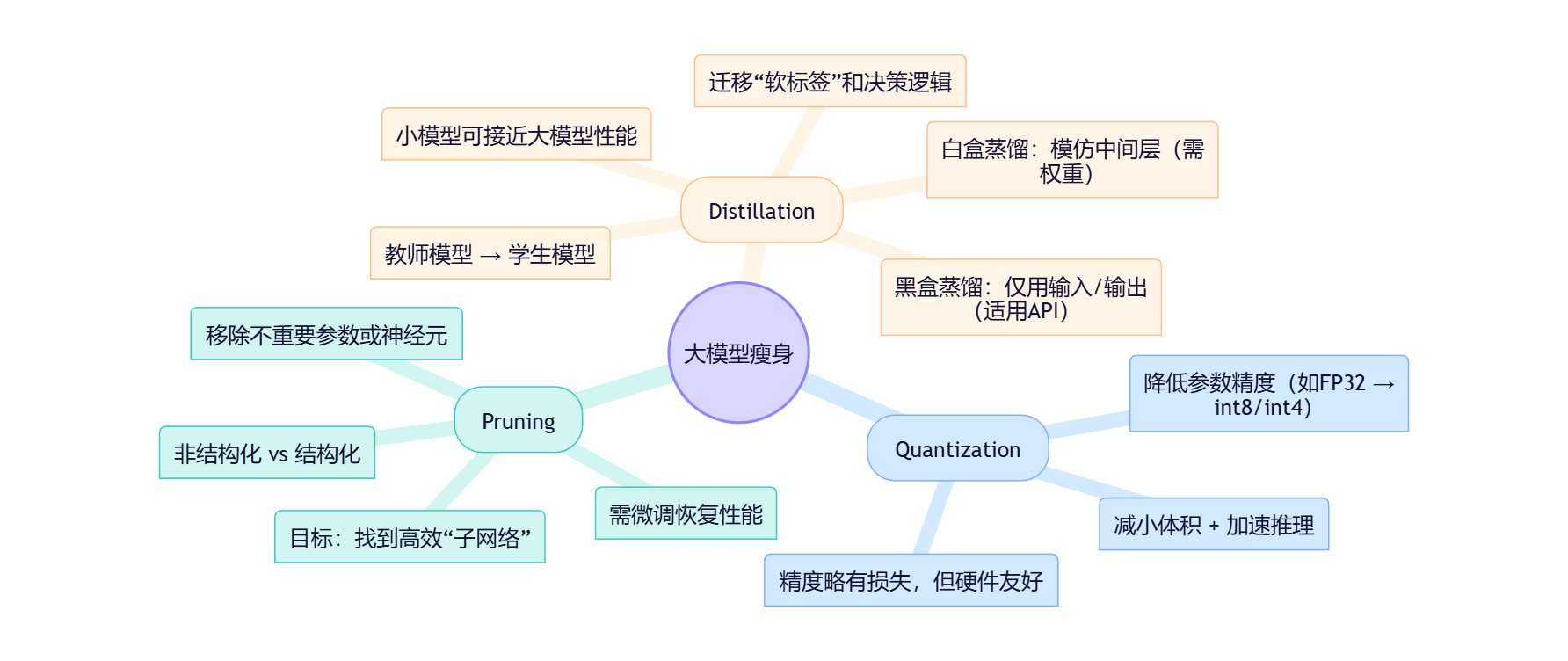
今天,我们将探讨三种主流的模型效率提升方法:量化(Quantization)、剪枝(Pruning)和知识蒸馏(Knowledge Distillation)。我们将它们视为三种不同的优化哲学,并从机理和功能意义上进行剖析。
下面,我们将分别检视三种实现这一目标的策略。
一、量化 (Quantization):降低参数的“分辨率”
1. 定义:它是什么?
量化(Quantization)是一种通过降低模型参数(Parameters)数值精度的技术,来减小模型体积和加速计算的过程。它本质上是一种信息压缩,但作用于模型的数字表示而非内容。
2. 机理阐释:它如何工作?
在数字世界中,一个数字的“精度”取决于我们用多少比特(bits)来存储它。标准的神经网络通常使用32位浮点数(FP32)来存储其参数,这提供了非常高的精度。
量化的核心操作是,将这些高精度的浮点数,映射到位数更少的整数(如8位整数 int8,甚至是4位整数 int4)。可以将其类比为将一个连续的光谱(如彩虹)简化为一组离散的色块(如红、橙、黄、绿…)。
比如,一段从-1.0到1.0的浮点数范围,可以被映射到-128到127的8位整数范围。原来的0.75可能就变成了整数96。
这种转换带来了两个直接的好处。首先,模型文件的体积大幅减小(例如,从32位降到8位,理论上体积可降为原先的1/4)。其次,现代计算硬件(CPU/GPU)处理整数运算的速度远快于浮点数运算,从而显著提升了模型的推理速度。
3. 功能意义与局限:它带来了什么?
量化是当前最普遍、最有效的模型优化手段之一。它直接降低了模型的“硬件门槛”,使得原本只能在昂贵服务器上运行的大模型,有机会部署在个人电脑、智能手机乃至物联网设备上。它是实现“边缘计算”(Edge Computing)AI应用的关键技术。
然而,量化的代价是精度损失。正如将高分辨率照片压缩过度会出现画质劣化一样,将参数从高精度转为低精度,必然会引入微小的误差。这种误差累积起来,可能会导致模型在某些精细任务上的性能下降。因此,量化的挑战在于找到一种最佳的映射方案,在最大化压缩率的同时,最小化对模型性能的损害。
二、剪枝 (Pruning):裁撤冗余的“神经连接”
1. 定义:它是什么?
剪枝(Pruning)是一种通过识别并移除神经网络中“非必要”的参数或结构,来降低模型复杂度和规模的技术。它如同园艺师修剪植物,剪掉多余的枝叶,以期让主干更健壮。
2. 机理阐释:它如何工作?
一个训练好的大模型中,数以亿计的参数并非同等重要。许多参数的绝对值非常接近于零,这意味着它们对模型的最终输出贡献甚微。剪枝的核心思想就是“重要性评估”。
算法会根据特定标准(例如,参数的绝对值大小)来评估网络中每个连接或神经元的重要性,并将被判定为“不重要”的部分移除(通常是将其值永久设为零)。这个过程可以是:
非结构化剪枝:移除单个的、散落的参数,会形成一个“稀疏”(Sparse)但结构不规则的网络。
结构化剪枝:移除整个的神经元或网络层块,得到的模型更规整,对硬件加速更友好。
剪枝后,模型通常需要一个“微调”(Fine-tuning)的过程,让剩余的参数重新适应,以恢复因移除部分连接而损失的性能。
3. 功能意义与局限:它带来了什么?
功能意义:剪枝的目标是创造一个更小、更高效的“子网络”。一个经过良好剪枝的模型,能够在参数数量远少于原始模型的情况下,达到相近的性能。这背后隐含着一个重要的理论假设:大模型的成功不仅在于其庞大的规模,更在于庞大规模为“找到”一个有效的“子网络”创造了可能性。其重要意义在于,它启发我们思考大模型中真正起作用的核心结构是什么,为设计更精简、更高效的原生网络架构提供了理论依据。
内在局限:剪枝的过程本身可能计算成本很高,因为确定哪些参数“不重要”需要复杂的分析。此外,过度剪枝会像过度修剪植物一样,损害模型的性能,甚至导致其无法正常工作。如何界定“重要性”以及在多大程度上进行剪枝,是该领域持续研究的核心问题。
三、知识蒸馏 (Knowledge Distillation):从博学者到专才的知识迁移
1. 定义:它是什么?
知识蒸馏(Knowledge Distillation)是一种训练范式,其核心思想是让一个规模较大、性能强大的“教师模型”(Teacher Model)去“教导”一个规模较小、结构更简单的“学生模型”(Student Model)。目标不是让学生模型死记硬背教师的答案,而是学习教师模型的“思维方式”和决策逻辑,从而在较小的体量下,实现远超其自身独立训练所能达到的性能。
2. 机理阐释:它如何工作?
首先,我们需要处理一个看似矛盾的问题:根据“规模法则”(Scaling Law),模型规模越大,性能通常越好。那么,让小模型去模仿大模型,其性能上限岂不是被大模型锁死了?知识蒸馏的精妙之处在于,它迁移的不仅仅是“正确答案”这一硬标签,更是大模型在做出决策时的“犹豫”、“确信”和“权衡”,即其输出的完整概率分布。
想象一下,教师模型在判断一张图片时,不仅告诉学生“这是猫”,还提供了更丰富的信息:“我有90%的把握这是猫,但它也有5%的特征像小老虎,2%像浣熊。” 这种更软、更丰富的信息,能帮助学生模型更好地理解类别之间的细微差异和泛化关系。
根据学生模型能获取教师模型的何种信息,知识蒸馏主要分为两大类:
A. 黑盒蒸馏 (Black-box Distillation)
这是一种“非侵入式”的教学。学生模型无法窥探教师模型的内部结构,只能像普通用户一样,向教师模型提问,并观察其最终输出。
机理:通过让教师模型对大量(无标签)数据进行预测,生成成千上万的“输入-输出”对(例如,一句提问和教师模型的回答)。然后,这个由教师模型创造的、蕴含其“知识”的合成数据集,被用来监督和训练(微调)学生模型。一个具体的例子是,使用像DeepSeek-R1这样强大的模型生成高质量的中文对话数据,再用这些数据去训练一个更小的模型,以期它能模仿DeepSeek-R1的语言风格与能力。
优劣势:这种方法的优点在于实现简单且适用性极广。我们不需要拥有教师模型的权重或源码,即便是通过API接口提供的商业闭源模型(如GPT-4、Claude),也能作为教师。这使得它在现实中被广泛采用。然而,其缺点也同样明显:效率低下,需要海量合成数据才能达到理想效果,且无法避免地会继承教师模型的偏见或幻觉,学生模型也无法学习教师模型更深层次的内部表征。
B. 白盒蒸馏 (White-box Distillation)
这是一种“侵入式”的教学,学生模型可以访问教师模型的内部参数、中间层输出等“思考过程”。这允许更直接、更高效的知识迁移。
机理:白盒蒸馏的策略更为多样,其核心是让学生模型在不同层面上模仿教师模型:
基于输出的蒸馏 (Knowledge-based):这是最经典的方式,即前文提到的,让学生模型学习教师模型最终输出的完整概率分布(Logits)。
基于特征的蒸馏 (Feature-based):让学生模型的中间层输出,去拟合教师模型对应中间层的特征图(Feature Maps)。这相当于不只看最终论文,还要模仿老师的草稿和提纲,学习其在信息处理的中间阶段是如何提炼和表达特征的。
基于关系的蒸馏 (Relation-based):这种方式更为抽象,它不要求学生直接模仿教师的某个具体数值,而是学习其对“关系”的理解。例如,教师模型认为输入A和输入B是相似的,而与输入C是疏远的,那么学生模型也应该学到这种样本间的“关系网”。或者,学习教师模型不同特征之间的关联模式(如Gram矩阵),掌握其内部知识的“结构”。
现实选择:黑盒的普及
尽管白盒蒸馏在理论上效率更高、传递的信息更丰富,但在实践中,黑盒蒸馏却因其无与伦比的灵活性和易用性而大行其道。在无法获取模型权重(特别是面对商业闭源模型)的情况下,黑盒蒸馏是唯一可行的方案。
3. 功能意义与内在局限:它带来了什么?
功能意义:知识蒸馏的核心贡献在于,它为“模型专业化”提供了一条有效路径。我们可以利用一个庞大、全能的通用模型作为“知识母体”,通过蒸馏孵化出多个在特定任务(如法律文书分析、医疗问答)上表现出色、同时又轻量高效的专用模型。这极大地拓展了大模型能力的部署边界。
内在局限:学生模型的上限终究受限于教师模型。它是在“模仿”而非“超越”。教师模型的缺陷,无论是知识盲区、逻辑错误还是社会偏见,都会被无差别地传递给学生模型,甚至可能因为模型的简化而被放大。因此,知识蒸馏产出的模型,其可靠性完全依赖于教师模型的质量和一个严谨的蒸馏过程。
结论:在性能与效率之间寻求最优解
量化、剪枝与知识蒸馏,代表了三种不同层面的优化哲学:
量化是硬件层面的妥协,用数值精度的损失换取存储和计算速度的增益。
剪枝是结构层面的精简,通过裁撤冗余寻找那个“小而美”的核心网络。
知识蒸馏是知识层面的迁移,以一种“传道授业”的方式,让小模型继承大模型的智慧。
这三种技术并非相互排斥,在实践中常常结合使用。它们共同的目标是在AI能力与现实资源限制之间,构建一座桥梁。理解这些技术,意味着我们不仅能赞叹于大模型的强大能力,更能审慎地看待其应用的成本,并批判性地思考在追求效率的过程中,我们可能舍弃了什么。
术语表 (Glossary)
- 量化 (Quantization): 一种压缩模型的技术,通过降低存储模型参数(即权重)的数字精度(如从32位浮点数降为8位整数),来减小模型体积并加快计算速度。
- 剪枝 (Pruning): 一种模型压缩技术,通过移除神经网络中被认为是“不重要”或“冗余”的连接(参数)或神经元,来降低模型的复杂度和计算量。
- 知识蒸馏 (Knowledge Distillation): 一种模型训练方法,让一个小的“学生模型”通过学习一个大的“教师模型”的输出来进行训练,从而将大模型的“知识”迁移到小模型中。
- 教师模型 (Teacher Model): 在知识蒸馏中,指那个规模庞大、性能强大,其知识将被迁移出去的原始模型。
- 学生模型 (Student Model): 在知识蒸馏中,指那个规模较小、结构更简单,通过学习教师模型来提升自身性能的目标模型。
- 黑盒蒸馏 (Black-box Distillation): 一种知识蒸馏方式,学生模型只能访问教师模型的最终输入和输出,无法窥探其内部结构。适用于API模型等不开源的情况。
- 白盒蒸馏 (White-box Distillation): 一种知识蒸馏方式,学生模型可以访问教师模型的内部状态,如中间层的输出或参数,以进行更深层次的学习。
几个有意义的问题 (Some Meaningful Questions)
量化通过降低参数的“分辨率”来实现效率。在处理充满模糊性和细微差异的人文社科文本(如诗歌、法律解释)时,这种精度上的损失是否会使模型无法捕捉关键的语义“颗粒度”?我们是否为了速度,而牺牲了模型对复杂概念的表达能力?
知识蒸馏本质上是一种“代际传承”,教师模型将其对世界的“理解”(即统计模式)传递给学生。在这个过程中,是否存在“知识的失真”或“意识形态的克隆”?如果我们用一个主要由西方数据训练的通用大模型,去蒸馏出针对特定文化(如研究东亚历史)的专用小模型,那么这个学生模型在多大程度上是在提供真实的历史洞见,又在多大程度上是在用一个“西方视角”的滤镜来复述和重组东亚史料?
当我们通过知识蒸馏创建一个特定领域的“学生模型”(如法律AI助手)时,我们得到的究竟是一个真正的“专家”,还是一个在特定领域模仿得惟妙惟肖的“通才的压缩回声”?这种被“教”出来的专业性,与通过学习真实、一手领域数据所获得的专业性,其内在的逻辑自洽性和可靠性是否存在本质差异?
本文讨论的三种技术(量化、剪枝、蒸馏)都是为了应对AI高昂的资源成本。这是否意味着未来会形成一个“AI的数字鸿沟”:即资金雄厚的机构使用着未经压缩、性能完整的“旗舰模型”,而学术界、非营利组织和普通公众则普遍使用着经过妥协、可能存在性能损失或偏见放大的“效率优化模型”?这种因经济考量而导致的技术分层,会对知识的生产和获取公平性带来何种长期影响


















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











