 高效参数微调PEFT详解
高效参数微调PEFT详解









参数高效微调全称为Parameter-Efficient Fine-Tuning(PEFT)。这是一个对于在各自领域中应用大模型至关重要的概念。
想象一个已经完成了通识教育、掌握了海量知识的资深学者(这便是预训练好的大模型)。现在,你想让他去胜任一个非常具体的新领域,比如“分析18世纪法国的法律文书”。
传统方法(完全微调 Full Fine-tuning):你需要让他重新学习相关的所有知识,这个过程会改变他大脑中原有的绝大部分知识结构。这成本极高、耗时极长,而且你每让他学一个新专业,就等于要“克隆”一个全新的他。
PEFT方法(高效微调):我们不改变他原有的知识结构。相反,我们只为他配备一套小巧的、可插拔的“专业工具包”或“专用笔记”。当需要分析法国法律文书时,他就启用这套工具;当需要分析宋代诗词时,他就换上另一套。他本人(核心模型参数)保持不变,只是学会了如何使用这些新工具。
图中的所有方法,都是设计不同形式的“专业工具包”或“专用笔记”的技术。它们共同的目标是:在不改动或极少改动大模型本体(那数以十亿计的参数)的前提下,让模型适应新的、特定的任务,从而极大地降低训练成本和存储需求。
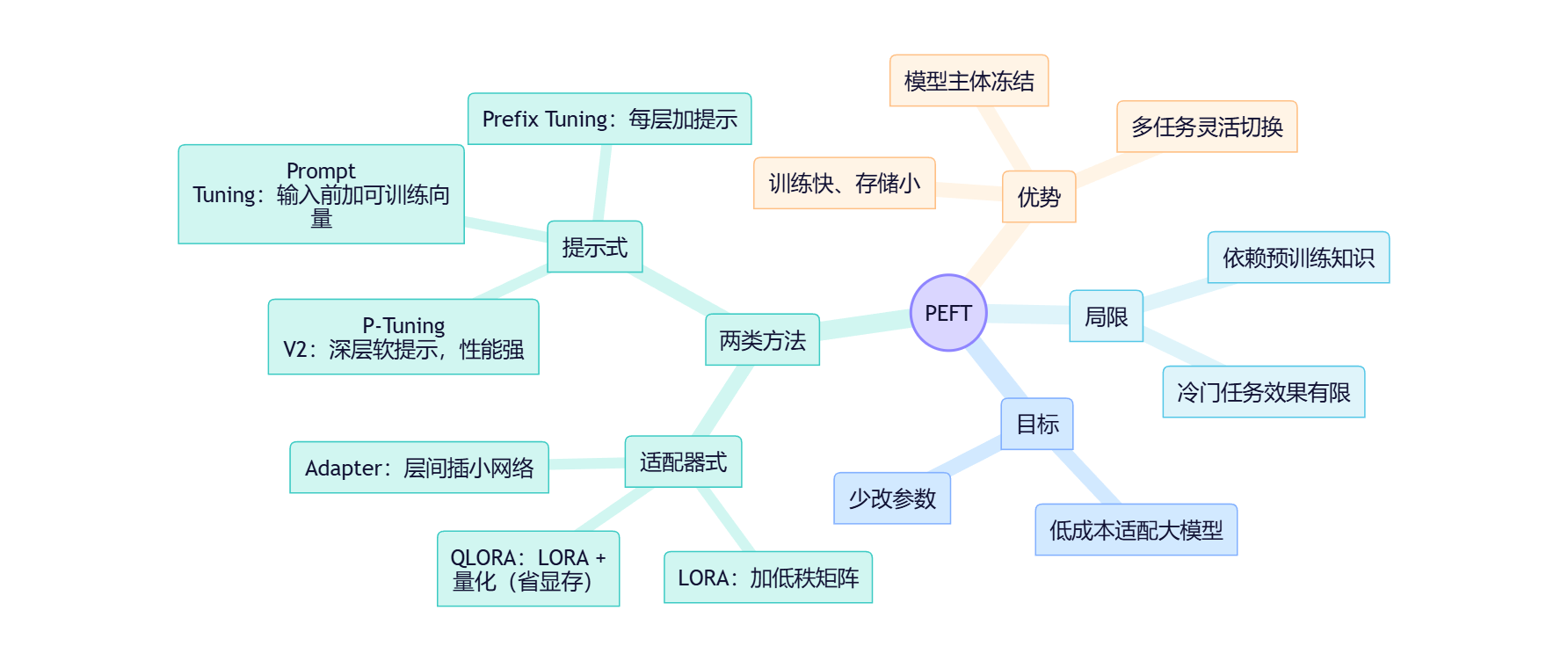
参数微调的策略
这些技术可以大致分为两大类:
- 适配器式方法(Adapter-based Methods):在模型内部结构中植入新的、小型的可训练模块。如图中的 LORA, QLORA, Adapter Tuning。
- 提示式方法(Prompt-based Methods):不改变模型结构,而是学习一种最优的“指令”来引导模型的行为。如图中的 Prompt Tuning, Prefix Tuning, P-Tuning。
第一类:适配器式方法 (Surgical Intervention within the Model)
① LORA (Low-Rank Adaptation / 低秩适配)
LORA一种通过向模型中注入成对的、微小的“低秩”矩阵来模拟微调效果的技术。
当模型进行完全微调时,其内部巨大的权重矩阵会发生细微但全面的变化。LORA的洞见在于,这种“变化”本身可以被一个极其简化的方式来近似。它将这个庞大的“变化矩阵”分解为两个非常“瘦”的小矩阵的乘积。在训练时,巨大的原始模型权重被冻结(Frozen),我们只训练这两个新添加的小矩阵。
想象你需要微调一张高清壁纸的色彩。完全微调是像素级地修改整张图片。LORA则是在原图之上覆盖一个透明的“调色图层”,我们只调整这个图层,而不是原图本身。这个“调色图层”就是LORA注入的低秩矩阵,它以极小的代价实现了对全局色彩的调整。
这种方法极大地减少了需要训练的参数数量(通常不到原始模型的0.1%)。这意味着你可以为成百上千个不同任务,各自训练一个仅有几兆(MB)大小的LORA模块,而不是为每个任务都存储一个几十吉(GB)的完整模型。这实现了模型的“大规模个性化定制”。
② QLORA (Quantized LORA / 量化LORA)
QLORA是LORA的极致优化版本,它通过量化(Quantization)技术,使得在更低硬件配置(如消费级显卡)上微调巨型模型成为可能。
QLORA做了两件事:
- 量化:将模型中被冻结的、巨大的原始权重从高精度(如32位浮点数)压缩到极低精度(如4位整数)。这就像把一张色彩极其丰富的照片,用有限的几种颜色(比如16色)来近似表示,从而大幅减小其占用的内存。
- 应用LORA:在这个被“压缩”了的模型基础上,再应用标准的LORA技术进行微调。
这种方法颠覆性地降低了微调的硬件门槛。它使得过去只有大型研究机构才能承担的、对超大模型的微调工作,进入了普通开发者甚至研究生的个人电脑。
③ Adapter Tuning (适配器微调)
一种在Transformer模型的各个层之间,插入微小、独立的可训练神经网络模块(称为“适配器”)的技术。
在Transformer的每一个块(Block)中,数据流在经过核心的“注意力层”和“前馈网络层”后,会被导向一个新插入的、小型的“适配器模块”。原始模型的权重完全冻结,只有这些像“旁路”一样的新模块参与训练,学习特定任务的知识。
这是PEFT思想的早期开拓者之一。它实现了新知识与旧知识在物理结构上的分离,概念清晰。训练好的适配器模块可以轻松地被加载或卸载,实现了模型功能的即插即用。
第二类:提示式方法 (Guiding the Model with Learned Instructions)
这类方法的核心思想是:与其改变模型,不如学习如何向模型提问。但这里的“问题”不是人类语言,而是一种模型能直接理解的、由数字构成的“软提示”(Soft Prompt)。
⑤ Prompt Tuning (提示微调)
Prompt Tuning 在用户输入的文本前,添加一小段可训练的、连续的数字向量(即“软提示”)作为前缀,用以引导模型生成特定任务的输出。
当用户输入“Translate to French: Hello”,模型会先将其转换为数字向量。Prompt Tuning则是在这串向量的最前面,再拼接上另一小段专门通过训练学习到的“任务指令向量”。这段指令向量的作用,就是把整个模型的内部状态“调整”到执行“英译法”任务的最佳模式。我们只训练这段指令向量,模型本身保持不变。
就比如,你面对一位能听懂任何指令的天才(LLM)。你可以用繁琐的语言描述你的任务,也可以学习一种能瞬间让他领会的“心灵感应”指令(软提示)。Prompt Tuning就是学习这种最高效的“心灵感应”指令。
这种方法比LORA等方法更极端,它完全不触及模型内部的任何权重,仅仅在输入端进行“注入”。这使得需要存储的“专业工具”变得更小(通常只有几百KB),部署极为灵活。
⑥ Prefix Tuning (前缀微调)
这种方法Prompt Tuning的拓展,它不仅在输入层添加可训练的前缀,而是在Transformer的每一层都添加一段特定的、可训练的前缀向量。
如果说Prompt Tuning是在一开始给出一个总指令,那么Prefix Tuning则是在模型进行每一步“思考”(即每一层计算)时,都在旁边不断地“提醒”它当前的任务是什么。这种持续的引导,使得模型对任务的专注度和执行效果更好,尤其是在生成式任务上。
相比Prompt Tuning,它提供了更精细、更强大的控制力,通常性能也更好,但需要训练和存储的参数也略多一些。
⑦ P-Tuning (Prompt-Tuning v1)
P-Tuning是一种通过一个小型神经网络(通常是LSTM)来生成“软提示”(Soft Prompt)的技术,旨在比直接学习软提示(如Prompt Tuning)更稳定、更有效。
在Prompt Tuning中,我们直接优化那些被添加到输入中的“软提示”向量本身。P-Tuning认为,这些向量之间应该具有一定的内在关联,而非孤立的数字。因此,它引入了一个小型的提示编码器(Prompt Encoder),通常是一个LSTM模型。这个编码器的任务是生成一整串有内部结构的、更“自然”的软提示向量,然后将其插入到输入中。
Prompt Tuning是直接寻找最优的“魔法咒语”本身(学习具体的数字)。P-Tuning则是打造一个“咒语生成器”(学习一个小模型),让这个生成器来产生最优的咒语。
这是对早期软提示思想的一个重要改进。通过引入一个模型来生成提示,P-Tuning试图解决软提示在优化过程中可能不稳定或陷入局部最优的问题。它验证了“可学习的提示”这一方向的潜力,为后续更成熟的方法铺平了道路。
⑧ P-Tuning V2
P-Tuning的全面升级版,它吸收了Prefix Tuning的思想,将软提示应用到模型的每一层,从而在性能上基本匹敌甚至超越完全微调。
P-Tuning V2将P-Tuning(或Prompt Tuning)的“软提示”概念与Prefix Tuning的“逐层注入”策略相结合。它不再仅仅是在最开始的输入层添加提示,而是在Transformer模型的深层网络中(包括Encoder和Decoder的每一层)都加入了可训练的提示向量。
P-Tuning V2是一个集大成者。它证明了,仅仅通过在模型深层注入任务特定的“软提示”,就可以达到与改动模型全部参数(完全微调)相媲美的效果。它兼具了Prompt Tuning的非侵入性优点和LORA等方法的高性能,成为了参数高效微调领域一个非常强大且通用的基准方法。
意义和局限性分析
在PEFT技术出现之前,让大模型服务于一个专门的学术领域(如分析司法判决文书的偏见),需要极高的算力和财力支持,是少数顶尖机构的专利。QLORA、LORA等技术将这一门槛急剧拉低。这意味着个体研究者或小型研究团队,如今有能力将最前沿的AI模型定制化地应用于自己的研究课题。这不再是遥不可及的未来,而是手边可及的工具。
这些技术并非没有局限。无论是LORA还是Prompt Tuning,它们都基于一个核心假设:通用大模型已经蕴含了解决特定任务所需的“潜力”或“先验知识”,微调只是将其“激发”或“引导”出来。如果一个任务所需知识在模型的预训练数据中完全不存在(例如,分析一个从未公开过的、极度冷门的古代手稿),那么任何PEFT方法都可能收效甚微。
结论
对于非计算机科学背景的研究者,你不需要掌握这些技术的实现细节,但必须把握其核心概念:它们是一套“四两拨千斤”的方法论。它们让我们能以极小的代价,“撬动”并“引导”巨大的预训练模型,使其精确地服务于我们多样化且高度专业化的研究需求。这不仅是技术的进步,更是研究方法论上的一次深刻赋能。
术语表 (Glossary)
- 参数高效微调 (PEFT): 一系列旨在以最小的计算和存储成本来适配大模型到新任务的技术的总称。
- 完全微调 (Full Fine-tuning): 调整模型所有参数以适应新任务的传统方法,成本高昂。
- 冻结 (Frozen): 在训练过程中,保持某部分模型参数不变。PEFT方法的核心就是冻结绝大部分原始参数。
- LORA (低秩适配): 通过在模型中注入微小的、可训练的“低秩矩阵”来高效微调的技术。
- 量化 (Quantization): 降低模型参数的数字精度(如从32位降到4位),以大幅减少模型内存占用的技术。
- QLORA: 将量化技术与LORA结合,极大降低了微调硬件门槛的技术。
- Adapter Tuning (适配器微调): 在模型层与层之间插入小型“适配器”神经网络模块进行微调的方法。
- 软提示 (Soft Prompt): 一段可训练的、由数字构成的向量,用于在输入端引导模型行为,而非人类可读的文本提示。
- Prompt Tuning (提示微调): 仅在模型输入层添加“软提示”进行微调的方法。
- Prefix Tuning (前缀微调): 在模型的每一层都添加“软提示”(前缀)进行微调的方法。
- P-Tuning / P-Tuning V2: Prompt Tuning的演进版本,V2通过在模型深层注入提示,实现了极高的性能。


















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











