








论大语言模型的定向能力提升
在大语言模型的应用过程中,我们通常期待其完成特定的功能。在将一个通才型的大语言模型(Generalist LLM)转变为特定领域的“专家”时,我们并非只有一种路径。不同的方法论,如同在学术研究中选择定性、定量或混合研究方法,各自对应着不同的干预深度、资源投入和预期目标。
以下,我们将系统性地剖析五种核心技术:提示词工程(Prompt Engineering)、上下文工程 (Context Engineering)、检索增强生成(RAG),以及两种主要的微调(Fine-tuning)策略——全参数监督微调(SFT)与参数高效微调(PEFT, 以LoRA为例)。我们将它们理解为一个从“外部引导”到“内部改造”的连续谱。
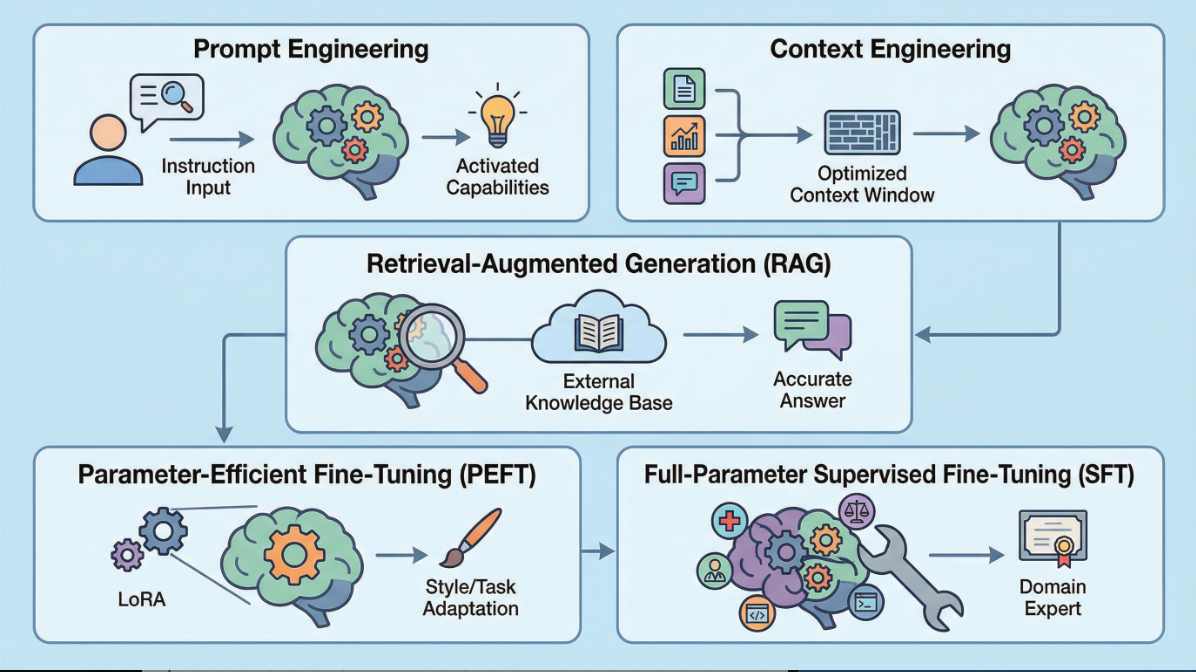
一、提示词工程 (Prompt Engineering):优化对话框架
这是最轻量级、也是最基础的干预方式。它不改变模型本身,而是通过精心设计与模型的“对话方式”(即提示词 Prompt),来引导模型更好地理解任务、激活其内部已有的相关知识,并以特定格式生成所需内容。
提示词工程是一门通过设计、优化输入文本(Prompt)来精确引导大语言模型输出的艺术与科学。它作用于模型的输入端,而非模型本身。
您提供给模型的不仅仅是一个简单的问题,而是一个结构化的“任务简报”。这份简报可以包含:
- 角色扮演 (Role-Playing): “你是一位专攻法律解释学的法理学家……”
- 背景信息 (Context Providing) “在以下的讨论中,我们将依据《联合国海洋法公约》第76条的规定……”
- 思维链 (Chain-of-Thought, CoT) 要求模型“分步思考”,先分析问题、再列举论据、最后得出结论。
- 样本示例 (Few-shot Learning): 给出1-2个高质量的“问题-答案”范例,让模型模仿其格式和逻辑深度。
这是实现模型能力“即时调用”的最高效方式,成本极低,人人可用。它能显著提升在单次对话中输出的质量和相关性。
它的上限是模型已有的知识和能力。如果模型的基础训练数据中从未包含某个领域的深度知识(例如一个非常冷门的考古学分支),那么再精妙的提示词也无法“创造”出这些知识。它是在激活”,而非“注入”。
二、上下文工程 (Context Engineering):精准驾驭模型的"注意力边界"
在前述的提示词工程、RAG之外,还有一个极易被忽视但对实际应用至关重要的技术维度——上下文工程 (Context Engineering)。如果说提示词工程是在优化"如何提问",那么上下文工程则是在优化"提供多少、提供什么样的背景信息",以及"如何组织这些信息的呈现顺序和结构"。
上下文工程 (Context Engineering)是一种通过精心设计和优化输入到大语言模型的上下文信息(Context Information)的内容、结构、长度和格式,来最大化模型理解准确性和输出质量的系统性方法论。
上下文工程的核心挑战在于处理一个根本性的张力:上下文窗口 (Context Window) 的有限性与信息需求的无限性之间的矛盾。
上下文窗口 (Context Window)是模型在单次推理中能够"阅读"和"记忆"的最大词元 (Token) 数量。这是一个硬性的技术限制。
面对上下文窗口的限制,上下文工程发展出了一系列精细化的优化策略:
- 信息分层与优先级排序 (Information Stratification & Prioritization):并非所有的上下文信息对完成任务的贡献都是等价的。上下文工程要求研究者对输入信息进行认知分层。
- 语义压缩与摘要技术 (Semantic Compression & Summarization):当原始材料(如一篇50页的判决书)的token数远超上下文窗口时,一个有效的方法是:用模型自身对长文档进行多层级摘要。
- 上下文内检索与动态注入 (In-Context Retrieval & Dynamic Injection):这是RAG技术的进阶应用。与其一次性将大量检索结果全部塞入上下文窗口,更精细的做法是:先找出最相关的文档集合。再在这些文档中进行二次检索,提取与用户问题语义最接近的段落。根据上下文窗口的剩余空间,动态调整注入的段落数量和长度。
- 上下文结构化与格式工程 (Context Structuring & Format Engineering):研究表明,即使是相同的信息,以不同的组织方式呈现给模型,其理解效果也会显著不同。上下文工程强调:用明确的标记(如 `### 问题 ###`、`### 背景资料 ###`、`### 要求 ###`)来结构化不同类型的信息,帮助模型的注意力机制更精准地定位关键内容。
- 滑动窗口与对话记忆管理 (Sliding Window & Dialogue Memory Management):在多轮对话场景中,随着对话轮次增加,完整的历史记录会迅速耗尽上下文窗口。上下文工程采用选择性记忆策略。
通过上下文工程,您可以在相同的上下文窗口限制下,向模型"传达"数倍于原始容量的有效信息。这对处理复杂、信息密集型任务(如法律案例分析、学术文献综述)至关重要,还能显著降低每次调用的成本——通过减少冗余信息、优化格式来节省token消耗。
然而,高度优化的上下文工程系统往往包含多个环节(检索、排序、压缩、格式化),每个环节都可能引入新的错误或偏差。系统的复杂度会显著增加调试难度和维护成本。
上下文工程中的许多技术(如多层级摘要、语义检索)本身就依赖于LLM的理解和生成能力。这形成了一种循环依赖:我们需要用模型来优化模型的输入。如果基础模型本身在某方面能力不足,再精妙的上下文工程也难以弥补。
三、检索增强生成 (Retrieval-Augmented Generation, RAG):外挂一个专属知识库
如果说提示词工程是优化提问技巧,上下文工程是提高信息密度,RAG则是在提问的同时,递给模型一本“开卷考试”的参考书。它将模型的内部知识与一个外部的、可信的知识库动态结合起来。
检索增强生成 (RAG) 是一种将信息检索(Retrieval)系统与语言模型生成(Generation)能力相结合的架构。它允许模型在回答问题前,先从一个特定的、最新的外部数据库中检索相关信息,并基于这些信息来组织答案。
整个过程分为两步:
检索 (Retrieval): 当用户提出问题时(如“请分析某案件中‘合理注意’的判定标准”),系统不会立刻将问题抛给LLM。相反,它会先将这个问题转换成一个查询向量,在您指定的私有知识库(如一个包含数千份判决书的数据库)中进行语义搜索,找出最相关的几段文本。
增强生成 (Augmented Generation): 系统将上一步检索到的原始文本片段,与用户的原始问题一起,整合成一个更为丰富的提示词,然后发送给LLM。这个提示词的内在逻辑是:“请根据以下我提供的资料:[引用的判决书A段落]、[引用的B法律条文],来回答这个问题:‘……’”
极大地缓解了模型的幻觉(Hallucination)和知识截断(Knowledge Cut-off)问题。答案的准确性和时效性被锚定在了那个可信的外部知识库上,非常适合需要高度事实准确性的领域(如法律、医疗、金融)。
RAG本质上没有改变模型的“性格”或“文风”。它只是让模型获得了查阅资料的能力,但模型如何理解和组织这些资料的风格和内在逻辑,仍然取决于其原始训练。它解决了“知道什么”的问题,但未深度改变“如何表达”的问题。
四、模型微调 (Fine-tuning):重塑模型的内在参数
微调是对模型进行的最深度的改造。它不再是外部引导,而是通过额外的、有针对性的训练,直接修改模型内部数十亿计的参数,从而在根本上改变模型的行为模式或知识结构。这好比让那位通识学者进入一个专门领域的博士项目,通过深度学习,其认知结构发生了真实改变。
微调主要分为两种主流路径:全参数监督微调(SFT)和参数高效微调(PEFT)。
4.1 监督微调 (Supervised Fine-Tuning, SFT)
监督微调(SFT)是在预训练之后,使用带有明确“监督信号”(即标签或标准答案)的数据集,对模型进行第二阶段训练,以塑造其特定能力与知识焦点的核心过程。
我们可以将SFT主要分为两大策略,它们服务于不同但互补的目标:
策略一:领域自适应微调 (Domain-Adaptive Fine-tuning)
这是让模型“沉浸式学习”特定领域知识的过程。
- 目标:知识注入 (Knowledge Infusion)。 让模型从一个“通用领域的高中生”,成长为特定领域(如法律、医疗)的“研究生”,使其深度学习该领域的术语、语料风格和内在知识体系。
- “教材”格式: 海量的、高质量的领域内纯文本。例如,数百万页的法律条文、判决书、学术期刊或医学教科书。
- 学习方式: 模型通过“下一个词预测”的方式通读这些材料,不断优化其内部参数,使其语言模型本身就更契合该领域的表达方式。它在学习“是什么”(What it is)。
策略二:指令微调 (Instruction Tuning)
这是教模型“如何听懂并执行任务”的过程。
- 目标:行为对齐 (Behavior Alignment)。 让那个“研究生”学会如何运用所学知识来解决实际问题,比如回答提问、审查合同、总结报告。它在学习“怎么做”(How to do)。
- “教材”格式: 高质量、人工标注的“指令-回答”数据集。这正是您描述的核心部分,例如:{ 指令: "请用后结构主义的视角,解读卡夫卡的《城堡》", 回答: "[一段高质量的、符合学术规范的文学评论]" }。
- 学习方式: 模型学习如何将给定的“指令”映射到理想的“回答”上。在学习这些范例时,它会不断调整参数,使其生成的回答越来越贴近这个“教材”所定义的风格、格式和任务解决路径。
SFT是塑造模型最终能力与个性的核心阶段,两大策略共同实现了:
- 领域知识的深度融合 (Deep Knowledge Fusion): 主要由领域自适应微调贡献。它让知识深度内化,而非停留在外部检索的表面,使模型在专业对话中听起来更像“自己人”。
- 复杂能力习得 (Complex Skill Acquisition): 主要由指令微调贡献。通过专门的指令数据集,可以强化模型在数学推理、代码生成或扮演特定角色(Agent)等方面的能力。
- 风格化与人格化 (Style/Persona Adoption): 主要由指令微调贡献。让模型学会以《甄嬛传》的口吻、或以一位严谨的经济学家的口吻进行交流。
然而,SFT也面临着严峻的挑战与权衡:
- 高昂的成本与“灾难性遗忘” (High Cost & Catastrophic Forgetting): 全参数微调需要巨大的计算资源。更关键的是,在模型专注学习新领域知识时,有可能忘记部分通用领域的旧知识,导致“偏科”。
- 对齐税 (Alignment Tax): 这是一个关键的权衡。当您过度地将模型“对齐”到某个特定任务或知识领域时(无论是通过领域自适应还是指令微调),都可能会损害其在其他通用任务上的性能。模型为了成为一个“专才”,牺牲了部分“通才”的能力。比如,过多的法律知识注入,可能会让模型在进行诗歌创作时也带上一种僵硬、刻板的语调。
- 高质量数据的双重依赖 (Dual Dependency on High-Quality Data): SFT的效果高度依赖数据质量。业界共识是,数据的质量远比数量重要。对于指令微调,一个包含1万条由专家撰写的高质量问答对的数据集,其效果远超10万条低质量数据。
- 对于领域自适应微调,数据的“干净”和“相关性”至关重要,混杂了大量无关或低质量文本的语料库甚至会起到反作用。构建这两种高质量数据集本身就是一项艰巨的工程。
4.2 参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT)以 LoRA 为例
为了克服全参数微调的高昂成本和灾难性遗忘等问题,研究界开发了PEFT方法。其核心思想是:在微调时,冻结(Freeze)预训练模型绝大部分的原始参数,只训练一小部分新增的或指定的参数。
参数高效微调(PEFT) 是一系列技术方法的总称,旨在以最小的参数修改和计算成本,将大模型适配到下游任务。LoRA (Low-Rank Adaptation) 是其中最成功和应用最广泛的一种技术。
LoRA的构思极为精妙。它基于一个线性代数观察:在微调过程中,模型权重矩阵的“变化量”本身,通常是“低秩(Low-Rank)”的。这在概念上意味着,将一个通用模型改造为特定领域模型的“本质性改变”,可以用远比原始参数少得多的信息来表达。
LoRA不直接修改原始的、庞大的权重矩阵(W),而是将它冻结。取而代之,它在旁边新增两个体量很小的“旁路”矩阵(A和B)。在微调时,我们只训练这两个小矩阵。在进行推理时,将这两个小矩阵相乘的结果,与原始的、被冻结的权重矩阵W相加。
想象一个庞大而经典的理论体系(原始模型)。全参数微调相当于试图重写整个理论体系,工程浩大且风险高。而LoRA则像是为这个理论体系撰写一篇精悍的、针对特定问题的“增补附录”或“适配性解释”。这个附录体量很小(A和B矩阵),但它与原始理论(W矩阵)结合时,却能精确地指导其在特定问题上的应用。你只需要训练这篇“附录”,而无需触动理论根基。
LoRA通常只训练模型0.1%甚至更少数量的参数,大大降低了对计算资源(GPU显存)的要求,使得在消费级硬件上微调大模型成为可能。
由于原始模型的绝大部分参数被冻结,其通用能力得以完好保留。
微调后得到的LoRA权重(小矩阵A和B)文件非常小(通常只有几百MB)。这意味着您可以为同一个基础模型训练多个不同的“专家适配器”——一个用于法律分析,一个用于诗歌创作,一个用于代码生成。使用时,根据任务需求“即插即用”,极大地提升了模型的灵活性和复用性。
然而,PEFT的性能上限通常略低于效果最好的全参数微调。在需要对模型进行极度深入、根本性改造的场景下(例如,赋予模型全新的复杂推理能力),仅修改一小部分参数可能力度不够。业界经验表明,对于风格适配、有限问答域优化或Agent协作这类更侧重“行为对齐”而非“知识注入”的任务,PEFT(如LoRA)的效果已经足够好且性价比极高。
结论
提升大语言模型特定任务能力的五种方法,构成了一个从"外部引导"到"内部改造"的完整谱系。提示词工程 (Prompt Engineering) 是最轻量的方式,通过精心设计输入指令来激活模型已有能力,成本为零但受限于模型的知识边界。上下文工程 (Context Engineering) 则专注于在有限的上下文窗口内优化信息的选择、压缩与组织,最大化输入的有效信息密度。检索增强生成 (RAG) 更进一步,为模型外挂一个可更新的知识库,让其在回答前先"查阅资料",从而缓解幻觉和知识截断问题,但模型本身的"个性"未变。当需要更深层次的改造时,参数高效微调 (PEFT) 以LoRA为代表,通过只训练极少量参数来适配特定任务,在保留通用能力的同时实现风格与行为的定制化。而全参数监督微调 (SFT) 则是最彻底的重塑,通过领域数据的深度训练让知识真正内化为模型权重,创造出垂直领域的专家模型,但代价是高昂的资源成本和潜在的灾难性遗忘风险。这五种方法并非互斥,而是可根据研究目标、资源条件和任务复杂度灵活组合,共同服务于将通用模型转化为特定领域研究助手的目标。
术语表 (Glossary)
- 提示词工程 (Prompt Engineering): 通过设计和优化给模型的输入指令(Prompt),来引导其产生更理想输出的技术。
- 检索增强生成 (Retrieval-Augmented Generation, RAG): 一种结合了外部数据库检索和模型文本生成的技术框架。模型在回答前会先“查资料”,以提高答案的事实准确性。
- 上下文工程 (Context Engineering): 通过精心设计输入到模型的背景信息的内容、结构和格式,来优化模型理解和输出质量的系统性方法。
- 上下文 (Context): 在技术层面,指模型在执行任务时所能访问的全部输入信息,包括用户问题、系统提示、历史对话、检索文档等的总和。
- 截断 (Truncation): 当输入文本超出模型的上下文窗口时,系统自动丢弃部分内容(通常是开头或结尾)的处理方式,可能导致关键信息丢失。
- 语义压缩 (Semantic Compression): 使用模型本身或专门算法,将长文本浓缩为保留核心语义的短文本的技术,目的是在有限的上下文窗口内容纳更多有效信息。
- 滑动窗口 (Sliding Window): 在多轮对话中,只保留最近若干轮次的完整对话记录,自动丢弃更早历史的记忆管理策略。
- 领域自适应微调 (Domain-Adaptive Fine-tuning): 监督微调的一种策略,侧重于让模型通过阅读大量领域文本来深度学习该领域的知识体系和表达风格("知道是什么")。
- 指令微调 (Instruction Tuning): 监督微调的另一种策略,侧重于通过"指令-回答"配对数据,训练模型理解任务需求并产生符合预期的输出行为("知道怎么做")。
- 冻结参数 (Frozen Parameters): 在参数高效微调(如LoRA)中,保持不被更新、维持原始预训练状态的模型参数,以保留通用能力和降低计算成本。
- 低秩 (Low-Rank): 线性代数概念,在LoRA中指用少量的参数(低维矩阵)来近似表达模型权重更新的"本质变化",是其高效性的数学基础。
- 适配器 (Adapter): 在PEFT语境下,指附加在预训练模型上的、小规模的、可训练的模块(如LoRA权重),使同一基础模型可以通过切换不同适配器来执行不同任务。
- 思维链 (Chain-of-Thought, CoT): 提示词工程中的一种技术,通过要求模型"逐步思考"并展示推理过程,来提升其在复杂逻辑任务上的表现。
- 少样本学习 (Few-shot Learning): 在提示词中提供少量(通常1-5个)高质量的示例,让模型通过模仿这些范例来完成任务的学习方式,无需修改模型参数。
- 模型微调 (Fine-tuning): 在一个已经训练好的“基础模型”上,使用特定的、小规模的数据集进行第二轮训练,以使模型适应特定任务或领域。
- 监督微调 (Supervised Fine-Tuning, SFT): 一种微调方法,使用大量“指令-期望回答”的配对数据来训练模型,目的是让模型的输出行为与这些高质量范例对齐。
- 参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT): 一类微调技术的统称,其共同点是在训练时只更新模型极小部分的参数,以节约计算资源。
- LoRA (Low-Rank Adaptation): PEFT中最主流的一种技术。通过在模型原有的大权重旁边,增加并只训练两个小型的“旁路矩阵”来实现高效微调。
- 灾难性遗忘 (Catastrophic Forgetting): 神经网络在学习新知识时,完全忘记或破坏了之前学习过的旧知识的现象,在全参数微调中较为常见。
- 对齐税 (Alignment Tax): 为了让模型在某个特定任务上表现更好(即“对齐”),而导致其在其他通用能力上性能下降的现象,是一种专业化带来的“副作用”。
几个有意义的问题 (Some Meaningful Questions)
- 文中提到上下文工程依赖LLM来优化LLM的输入(如用模型生成摘要),这形成了一种自指性结构。在这种结构下,如果基础模型本身就带有某种系统性偏见(如对女性学者著作的理解偏差),那么由它生成的"优化后的上下文"是否会强化而非消解这种偏见?我们如何在方法论上打破这个循环?
- 如果一项社会学研究旨在使用LLM分析大量访谈文本的情感倾向,而另一项法学研究旨在使用LLM总结判例要点。前者更关注“如何分析”(风格、视角),后者更关注“分析什么”(事实)。这两种不同的研究目的,应如何导向在RAG、LoRA、SFT之间做出选择?错误的方法选择会给研究结论带来何种风险?
- RAG提供的知识是“外置的、可引用的”,而SFT内化的知识是“内在的、概率性的”。当两者给出的答案发生冲突时,我们应如何判断其可信度?这是否揭示了“机器知识”的两种不同本体论状态?
- 文中提到上下文工程依赖LLM来优化LLM的输入(如用模型生成摘要),这形成了一种自指性结构。在这种结构下,如果基础模型本身就带有某种系统性偏见(如对女性学者著作的理解偏差),那么由它生成的"优化后的上下文"是否会强化而非消解这种偏见?我们如何在方法论上打破这个循环?
- 通过LoRA,一个研究团队可以轻易地创造一个带有特定理论倾向(如“马克思主义视角”、“自由主义视角”)的分析模型。当使用这种“有立场”的工具来分析中性文本时,我们得到的究竟是文本的客观解读,还是工具自身偏见的投射?我们该如何向学术共同体声明并审视这种工具内建的立场?


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











