






 本文深入探讨了机器学习中的线性回归和K-means聚类算法。对于线性回归,讲解了参数θ的数学表示、特征x的选择以及误差的理解。在K-means中,解释了确定簇数、质心计算和距离度量方法。文章还重点介绍了优化技巧,如矩阵求导和梯度下降,并强调了不同参数的独立优化。
本文深入探讨了机器学习中的线性回归和K-means聚类算法。对于线性回归,讲解了参数θ的数学表示、特征x的选择以及误差的理解。在K-means中,解释了确定簇数、质心计算和距离度量方法。文章还重点介绍了优化技巧,如矩阵求导和梯度下降,并强调了不同参数的独立优化。
线性回归
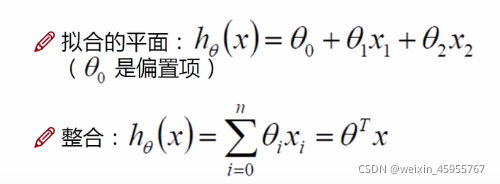
为什么叫h(x)
为什么用θ表示参数
θ是向量还是矩阵?
为什么用x表示特征
为什么X是一个来表示的向量
为什么在表格添加一列1 ?便于矩阵计算

为什么用表示误差?
K-means
基础概念:
1.要得到簇的个数,需要指定K值
2.质心:均值,即向量各维取平均即可
3.距离的度量:常用欧几里得距离和余弦相似度(先标准化)
4.优化目标: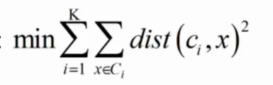 就是每个簇内每个样本点到簇中心的距离之和最小
就是每个簇内每个样本点到簇中心的距离之和最小

为什么叫h(x)
为什么用θ表示参数
θ是向量还是矩阵?
为什么用x表示特征
为什么X是一个来表示的向量
为什么在表格添加一列1 ?便于矩阵计算
为什么用表示误差?
K-means
基础概念:
1.要得到簇的个数,需要指定K值
2.质心:均值,即向量各维取平均即可
3.距离的度量:常用欧几里得距离和余弦相似度(先标准化)
4.优化目标: 就是每个簇内每个样本点到簇中心的距离之和最小
 1043
1253
1320
1914
1043
1253
1320
1914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























