








Self-attention(Transfomer)
基于台大李宏毅老师的课程
文章目录
导读
Self-attention是最近很火的一种新的技术,传统的我们的神经网络输入都是一个vector,但如果我们想要多个vector作为输入该怎么办呢,我们想要一个a sequence of vector作为输入应该怎么做呢?这种需求是存在的,例如,一段声音信号就可以被处理为一串vector,或者一句文本,都可以作为a sequence of vector的信息了。
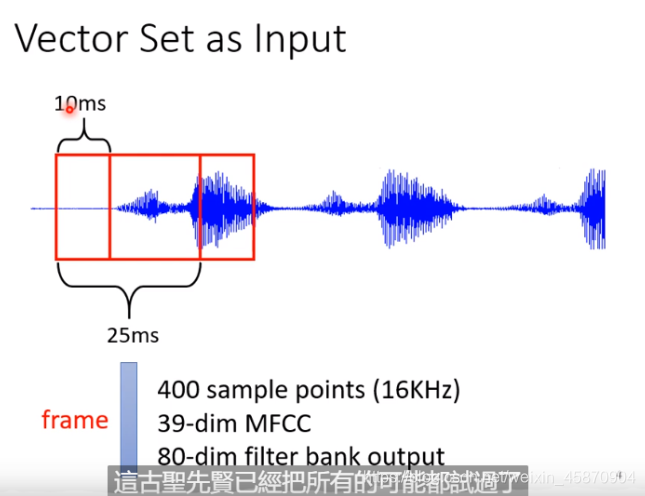
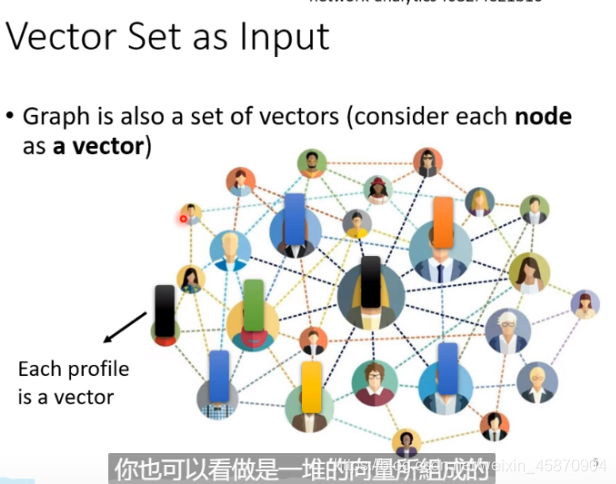
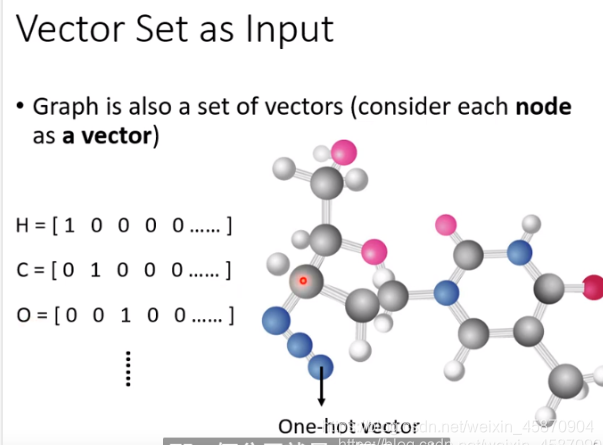
那么,我们该怎么做呢?
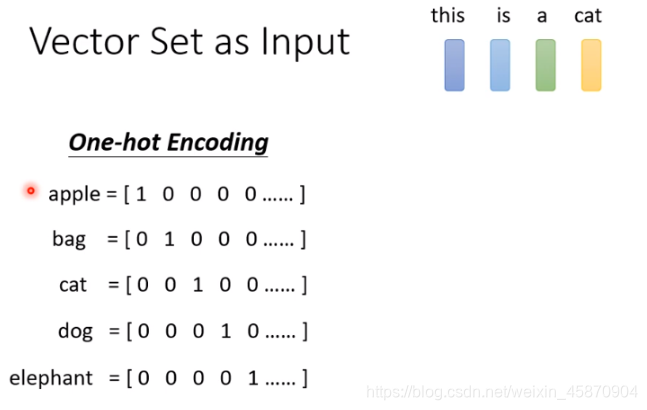
一个常见的想法是使用one-hot encoding,比如如果有10万个单词,我们就使用十万个基于one-hot encoding机制的向量去表征,显然,这种做法是很荒谬的。这样的向量表示,不能体现各个词之间有任何关系。
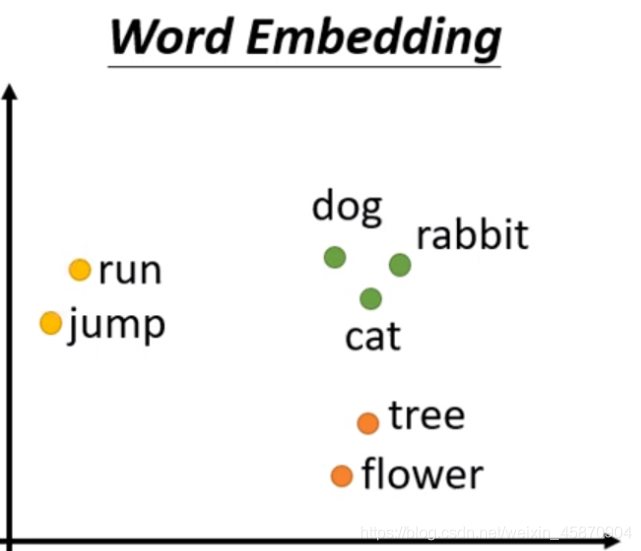
当然,目前存在一种word embedding这种方法:
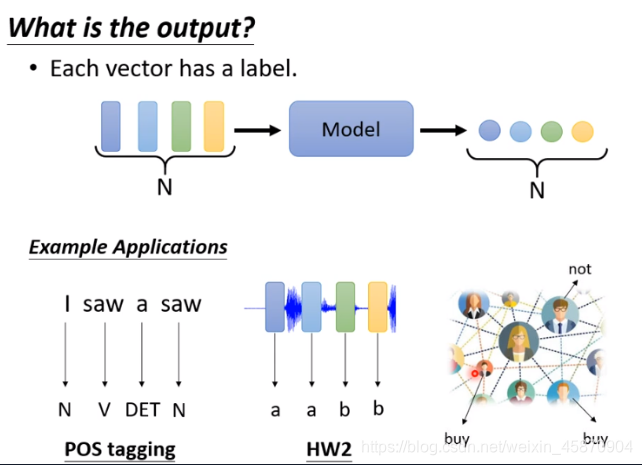
下面,我们来看几种常见的对应多个向量输入的IO机制:
1.
输入和输出是一样数量的label,最经典的应用有词性分类。
推荐系统与一段语音的音标标注也是这种类型的应用
2.整个sequence输入的输出只有一个label。
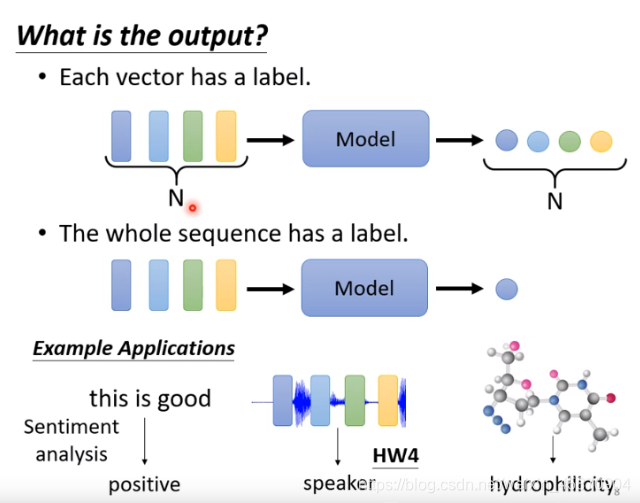
常见的应用有一段文本的情绪识别,一段语音的说话者辨识,一个结构图是什么分子。
3.第三种就是由机器自己决定输出多少的任务。例如翻译-真正的语音辨识。
也就是sequence to sequence
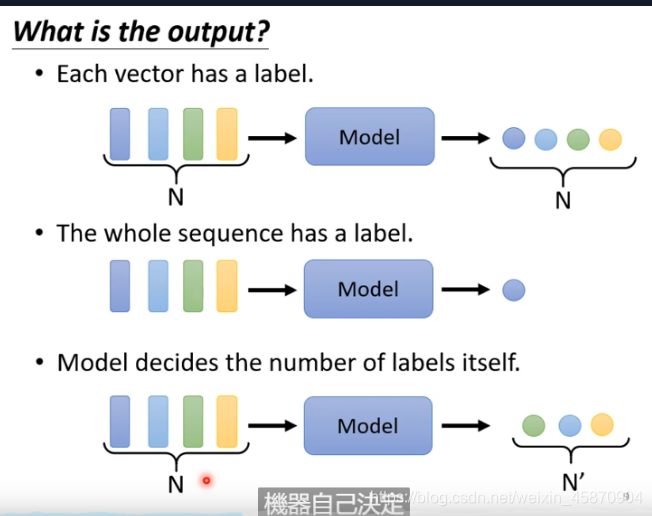
好了,接下来我们来看看序列的标注(sequence labeling)

我们当然不能说每个向量单独作为一个输入放到一个神经网络里面,因为这个sequence是有语义联系关系的。为了解决这个问题,我们把几个向量联系起来。
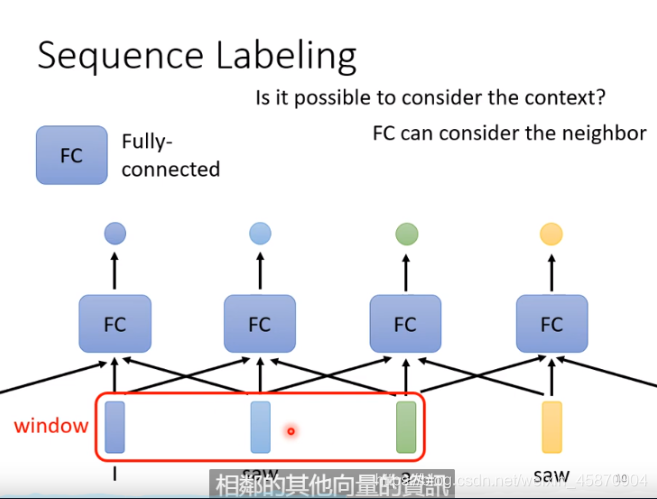
我们开一个sequence-window,把整这个sequence-window里面的向量都联系起来作为输入给全连接层
但是如果我们把sequence-window开的很大,这就容易出现很多问题
- 要看训练资料(湾湾喜欢这么翻译)中的sequence的长度,我们要让window覆盖其中最长的才行
- 由于输入很大,那么整个模型就需要很多参数,这意味着计算量很大且很容易出现overfitting
好勒,导读结束了,为了解决这个问题,那我们现在终于来到了这一部分的重点-self attention。
Self-attention
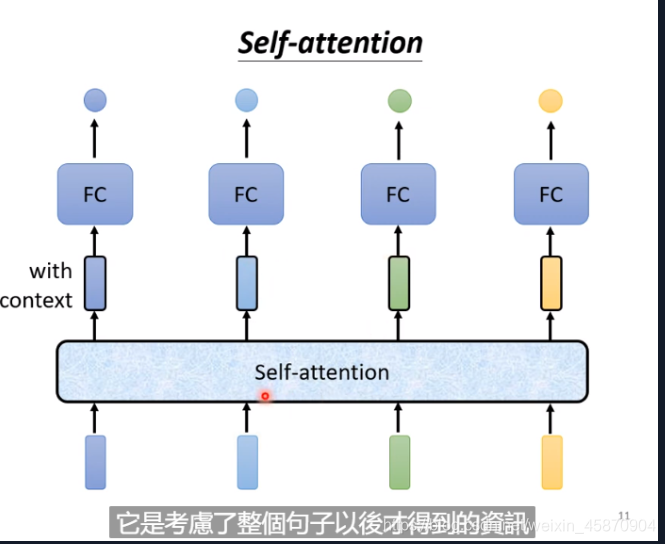
其考虑了整个一串向量后得到的输出,再丢进fully connected network(Dense层)
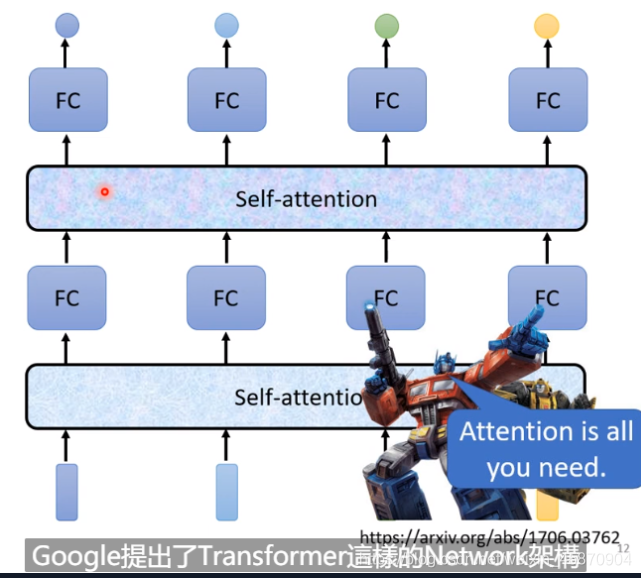
很吊的一篇论文 《attention is all you need!》
论文链接:attention is all you need!
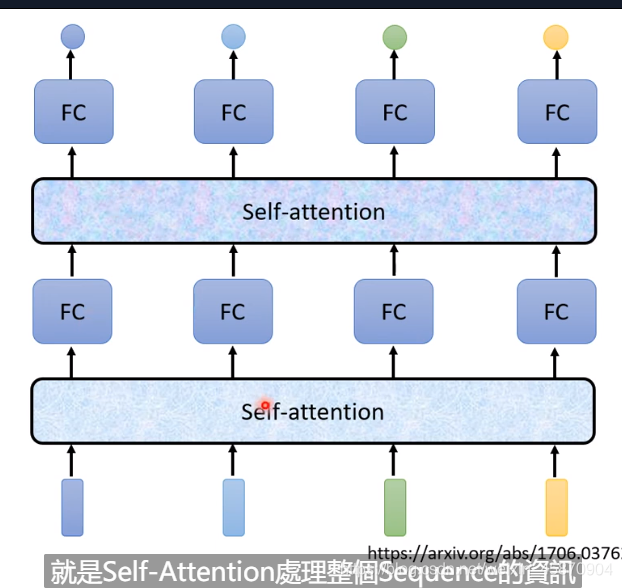
Self-attention层可以是放在输入层之后,也可以是在中间的hidden layer
当然一个network里面可以存在多个attention layer:
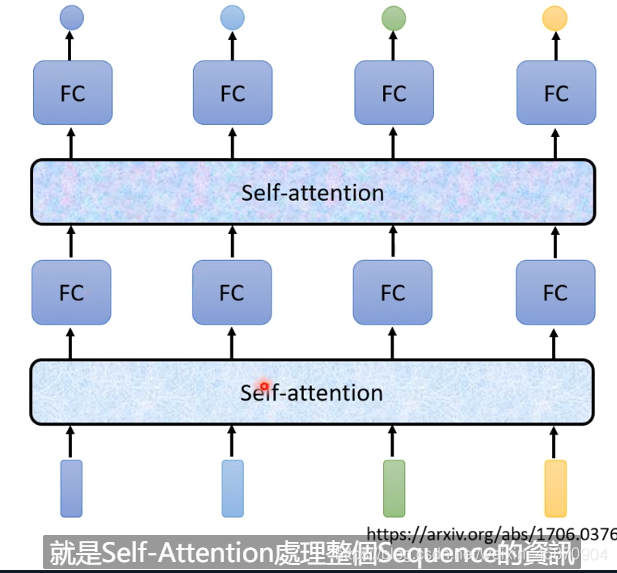

每一个b都是考虑了所有的a才产生的
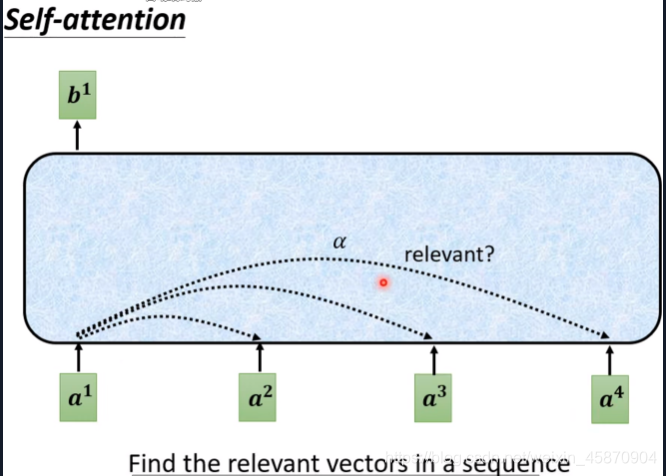
找出一个sequence中哪些向量与它相关是我们要解决的问题!
Self-attention的计算过程
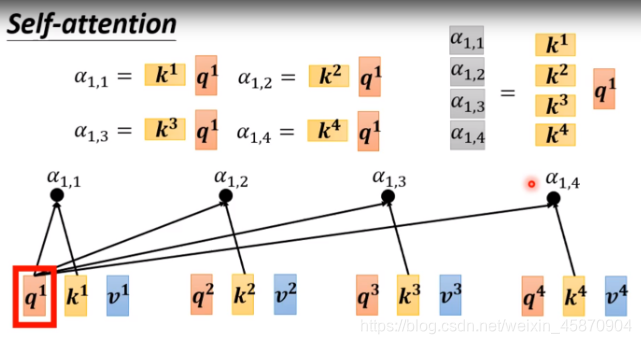
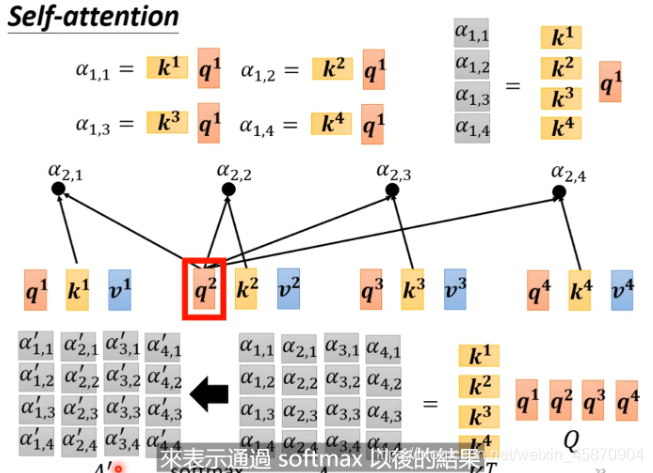
计算α(相关因子):
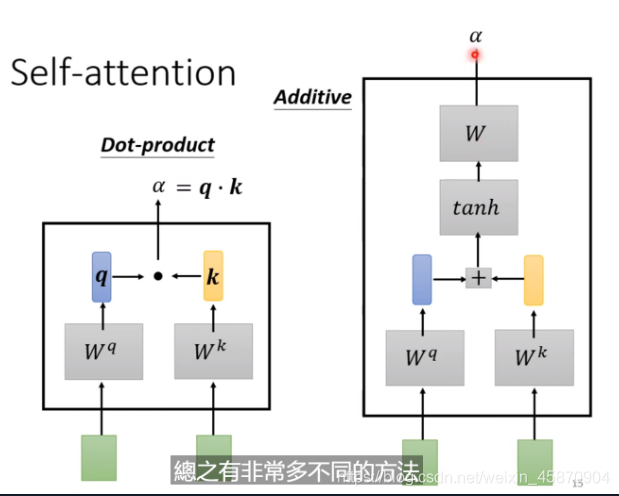
一般使用 Dot-product-用在transformer的方法
两
个
输
入
向
量
与
w
q
(
矩
阵
)
相
乘
后
得
到
一
个
向
量
,
两
个
向
量
在
做
一
个
D
o
t
−
p
r
o
d
u
c
t
,
(
做
一
个
e
l
e
m
e
n
t
−
w
i
s
e
后
求
和
)
两个输入向量 与 w^q(矩阵)相乘后得到一个向量,两个向量在做一个Dot-product,(做一个element-wise后求和)
两个输入向量与wq(矩阵)相乘后得到一个向量,两个向量在做一个Dot−product,(做一个element−wise后求和)
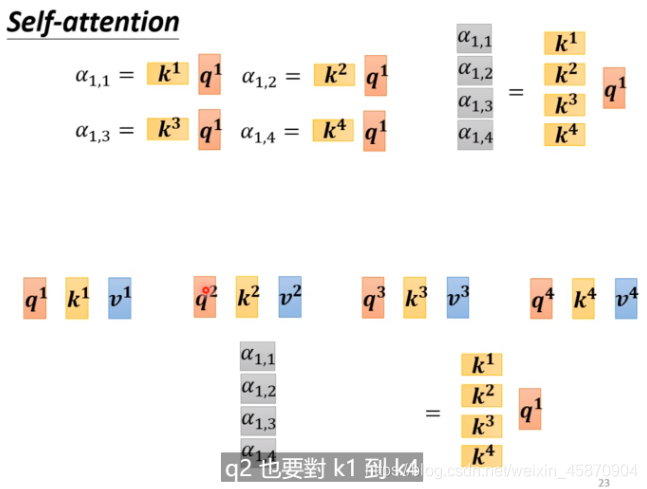
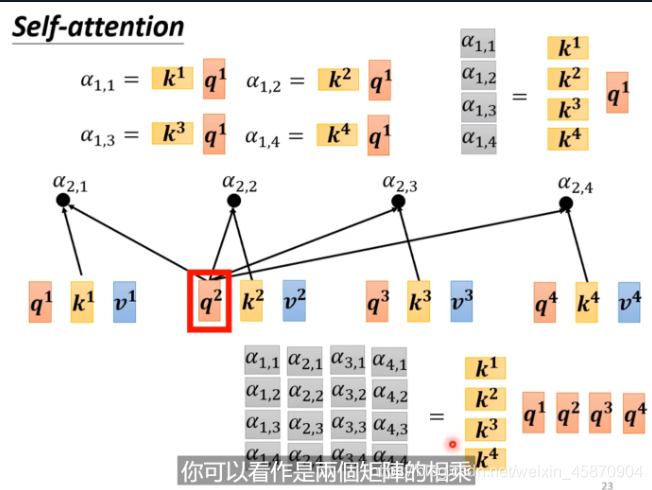
当然,我们需要分别计算一个向量与sequence里面其他所有向量的α,然后再做一个normalization(这里使用的是softmax)-需要注意的是,计算自己与自己的相关因子也很重要,你可以通过实验来验证这一点。:
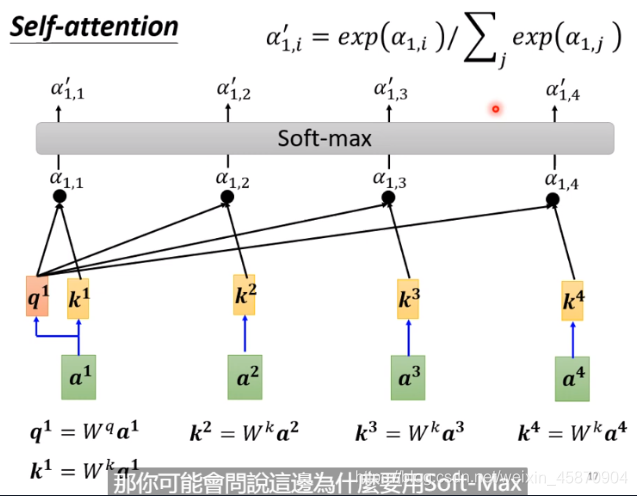

soft-max只是最常用的,用其他也行,什么Relu甚至会有很好的结果
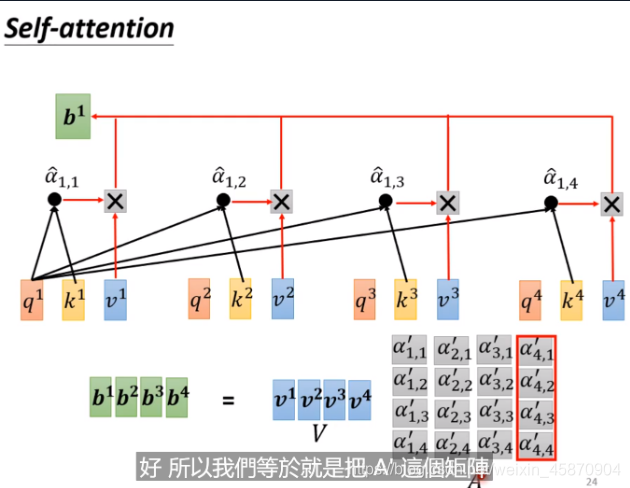
接下来,我们来计算b:
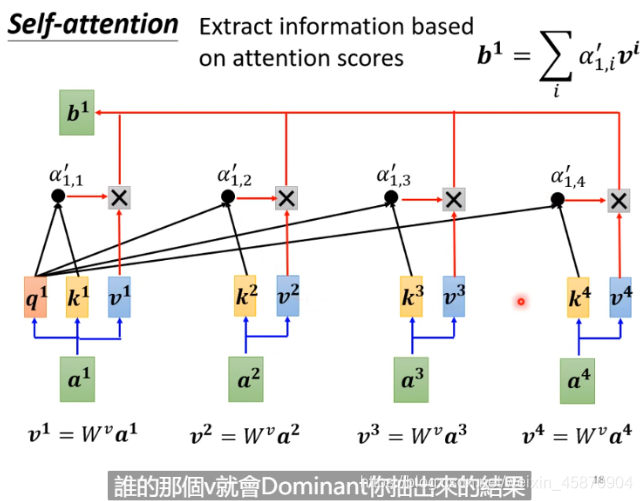
抽取重要的资讯。每一个a去乘*一个新的矩阵Wv,再与a‘1.1相乘相加得到b1,如果某一个a’1.x值很大(两个向量的关系性很强),最终的求和就可能会接近这个值,这个值其就可能会支配b1这个结果。-这也是其work的一个重要原因和直觉
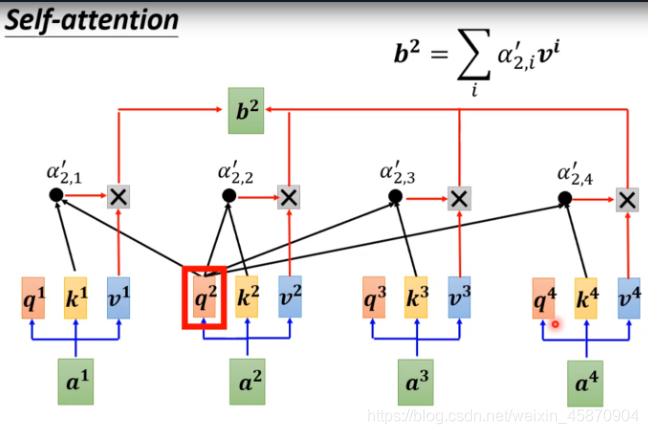
以上就是从整个sequence得到b1的完整计算过程。
注意,整个计算过程是parallel的,后面会讲到,其与RNN有很大不同。
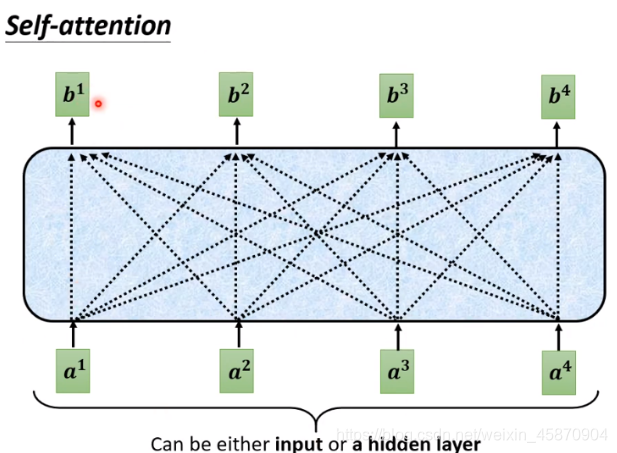
计算过程的向量化(query key value)
就是一个向量堆叠成矩阵进行矩阵运算的过程,不多讲
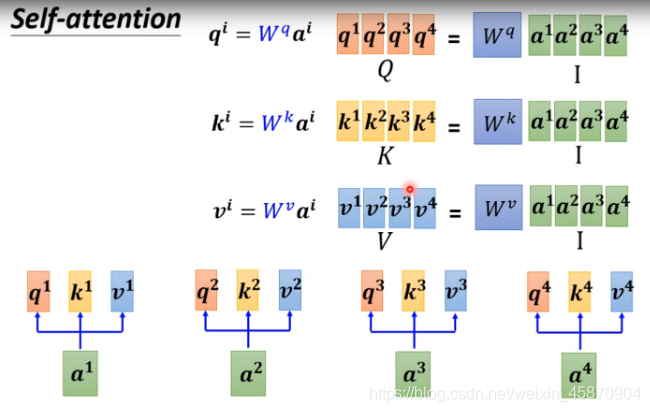
最后,我们直接得到了一个矩阵(1*4)B(Output)-最后做的是一个weighted sum(加权求和)
需要学习的参数
(
W
q
,
W
k
,
W
v
)
−
即
W
矩
阵
(W^q,W^k,W^v)-即W矩阵
(Wq,Wk,Wv)−即W矩阵
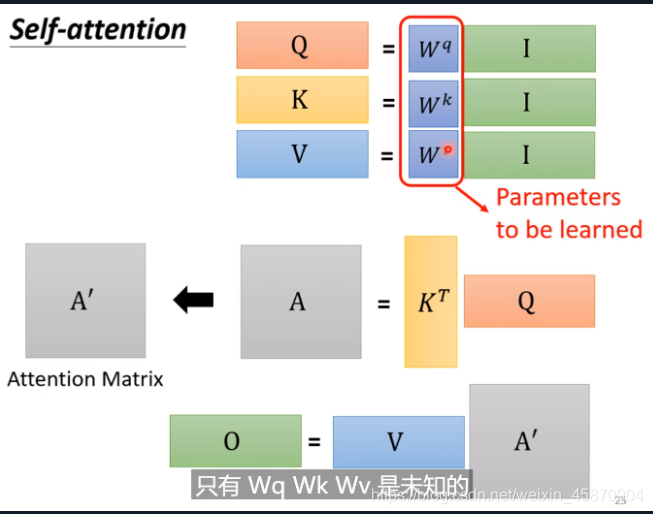
和神经网络里面的矩阵参数是类似的。
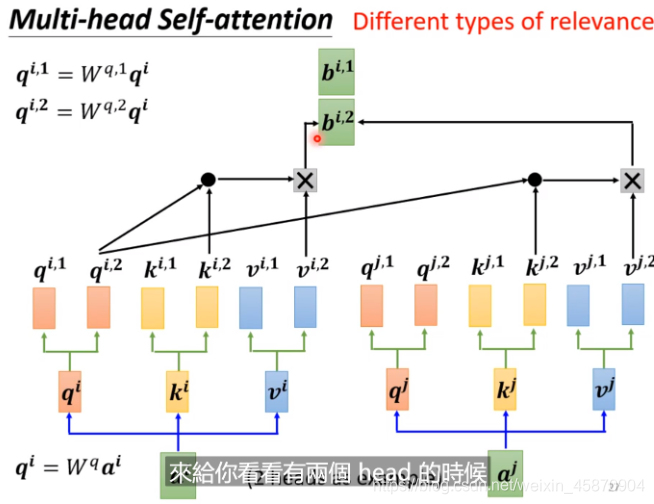
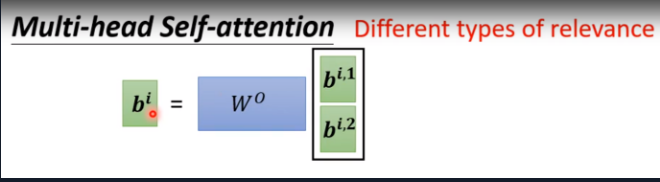
Multi-head self-attention (Different types of relevance)-不同的相关性
因为实际上不同向量的相关性是可以有多种定义方法的,所以出现了Multi-head self-attention
(不同的q代表不同的相关类型),ai乘以两个不同的矩阵得到qi,1 和 qi,2。
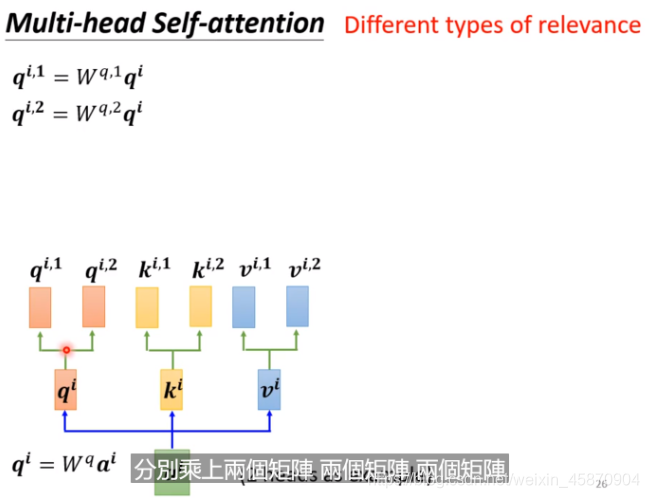
当然,在计算的时候,相同相关性定义的类型进行计算。
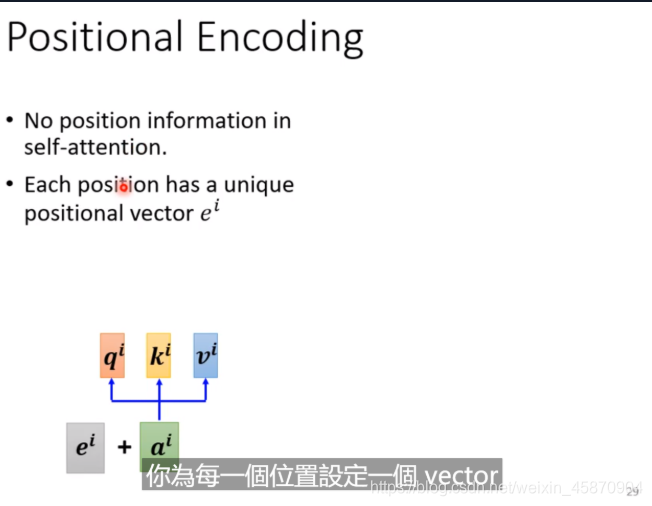
加入位置信息(比如pos-tagging 词性标记-分析)
加入向量间的位置信息是十分重要的,例如一段文本,名词当然最容易出现在句首。
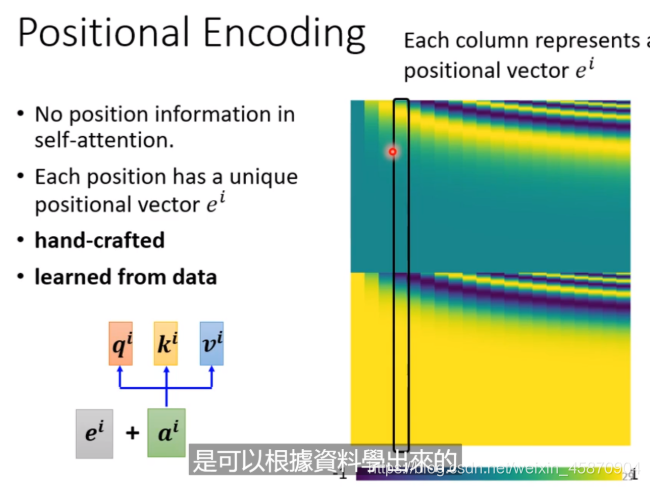
常见的两种位置信息编码的方法
1.人为设定
2.从data中学习
下面是论文中目前比较主流的四种方法:
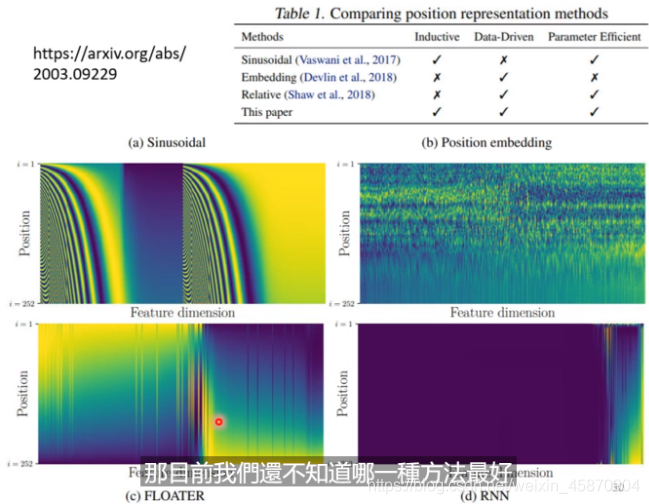
NLP应用(Bert)

Speech(应用)
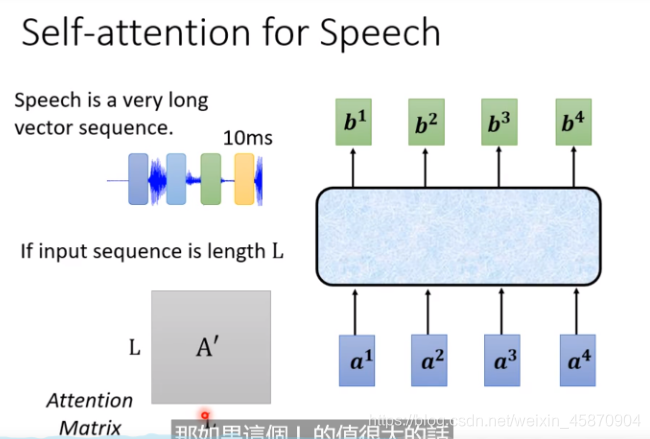
L太大,存储太大,计算量太大!
改进:
Truncated(缩短-删减) self-attention
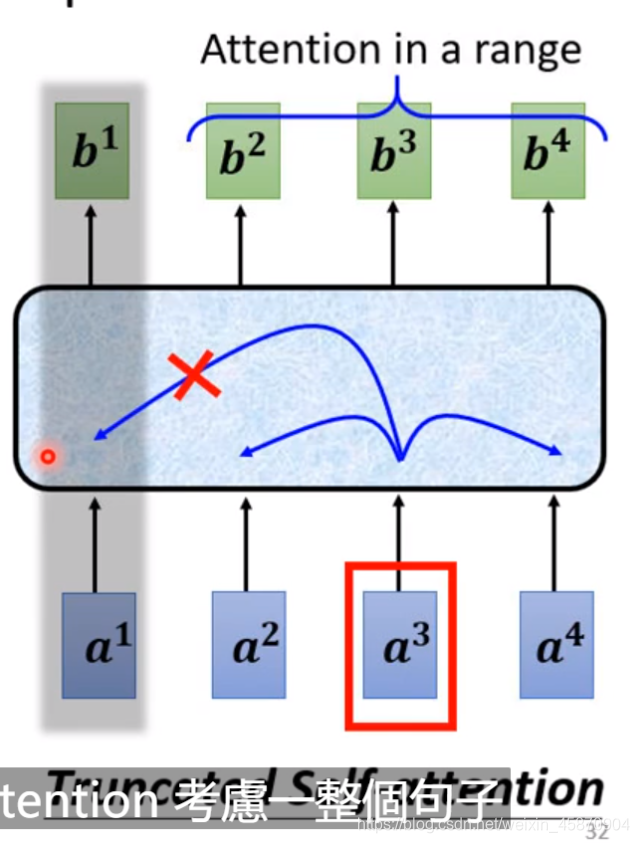
考虑周围的一个小范围就好,没必要考虑一句话的所有。
image(应用)
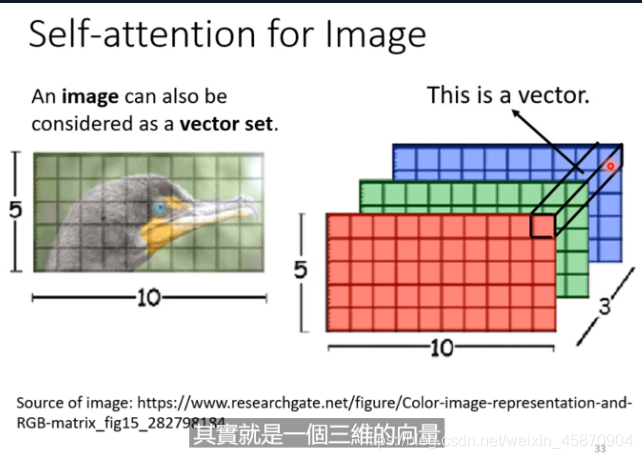
整个图片就是一个5*10的向量
一篇使用这种方法的论文:
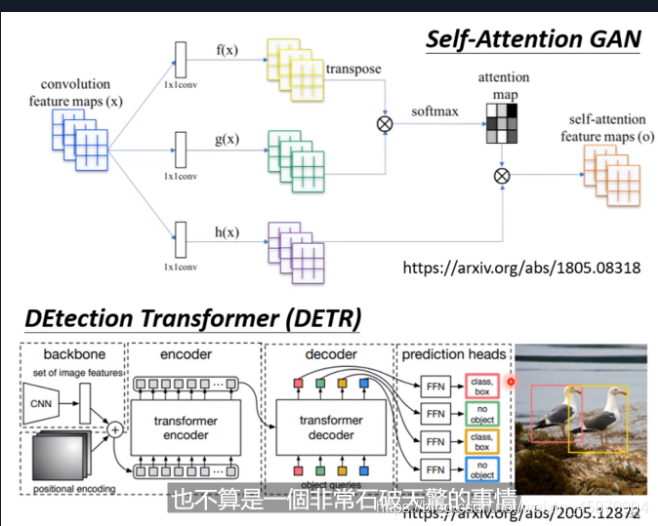
Self-attention VS CNN

使用self-attention后,receptive field就是学出来的,而不是我们人为划定的了。
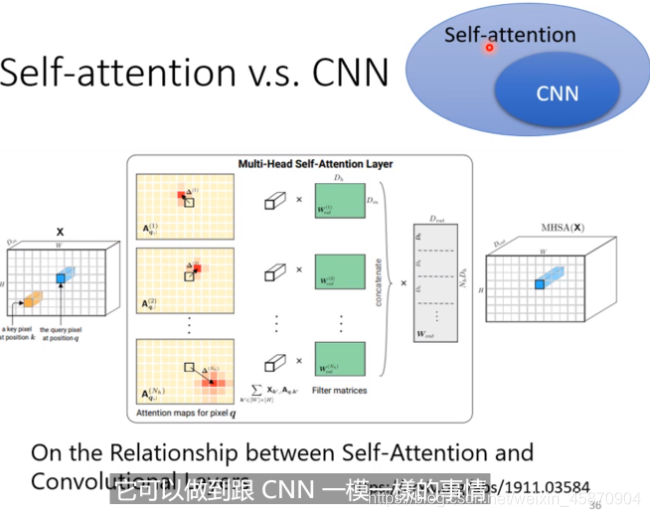
(一个paper)
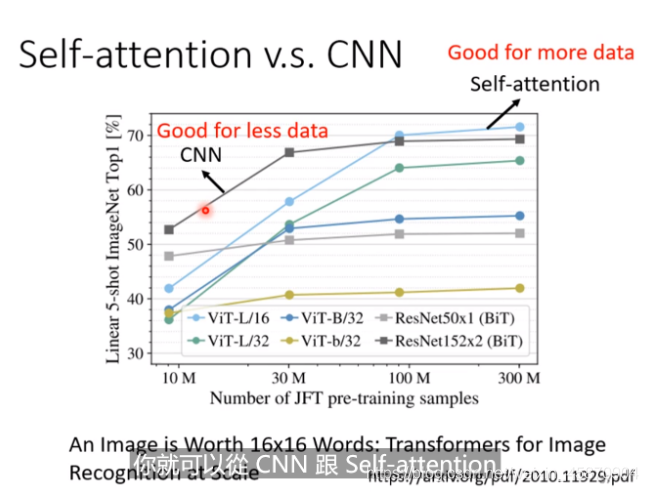
Self-atttion是更加灵活的flexible
比较flexible的model需要更多的data-如果数据不够就容易过拟合
conformer(cnn+self-attention) 基于卷积增强的Transfomer)
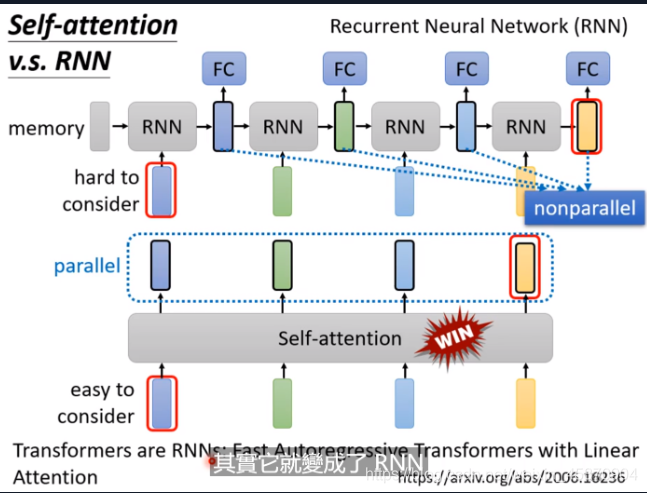
Self-attention VS RNN
RNN分单向和双向(bidirectional)
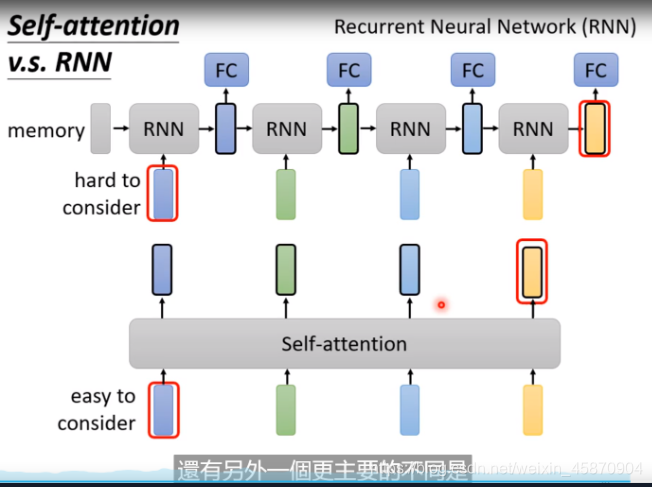
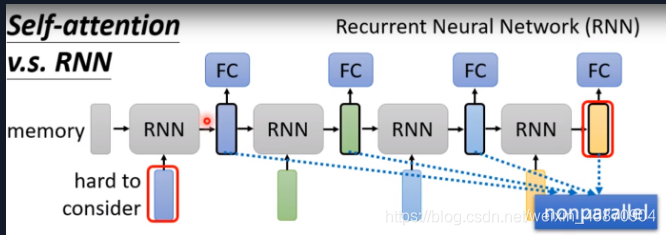
两个主要的区别:
- RNN不能做并行计算
- RNN很难考虑两个位置距离很远的信息的相关性
读paper:
Self-attention for Graph
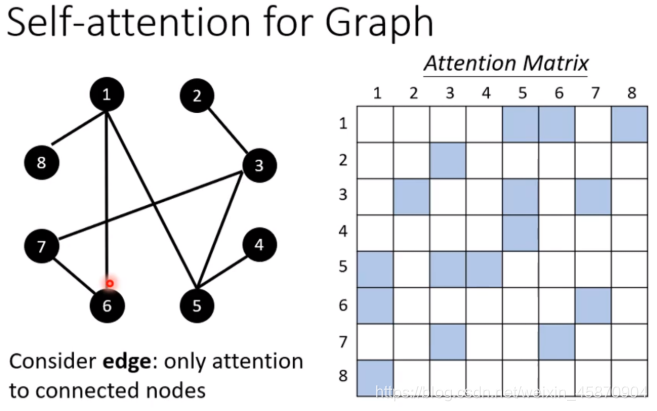
做attention计算的时候,只计算edge有相连的node就好
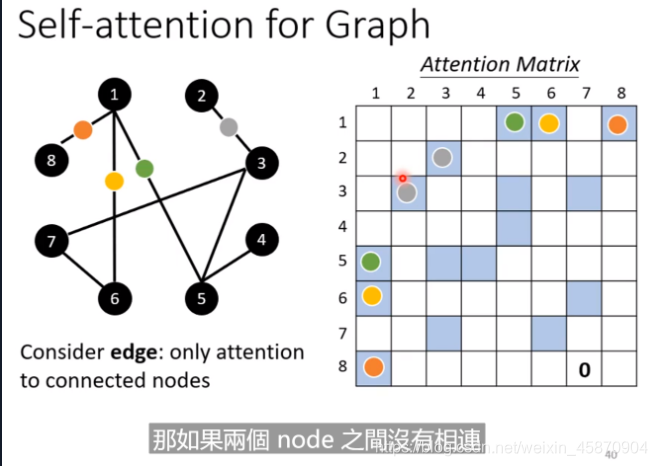
如果两个node之间都没有相连,那么考虑它们的相关性也没有啥意义。
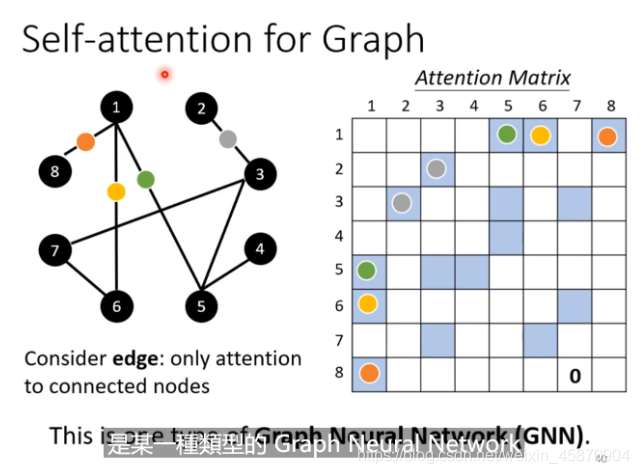
其实这种加入self-attention的图就是某一种类型的GNN。
展望:
少self-attention的计算量是值得研究的
广义的transformer指的就是transformer
XXformer都是各种的transformer变形模型的名字
读paper-各种self-attention的变形

















 4010
4010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









