




注意力是一个有助于提高神经机器翻译应用程序性能的概念。在这篇文章中,我们将看看Transformer,一个使用注意力来提高这些模型训练速度的模型。Transformer在特定任务中优于谷歌神经机器翻译模型。最大的好处来自于Transformer如何使自己适合并行化。
在这篇文章中,我们将尝试简化一些内容,并逐一介绍概念,希望能够让没有深入了解主题的人更容易理解。
A High-Level Look
让我们首先将模型视为一个单一的黑盒。在机器翻译应用程序中,它将以一种语言获取句子,并以另一种语言输出其翻译。

打开它,我们看到一个编码组件,一个解码组件,以及它们之间的连接。
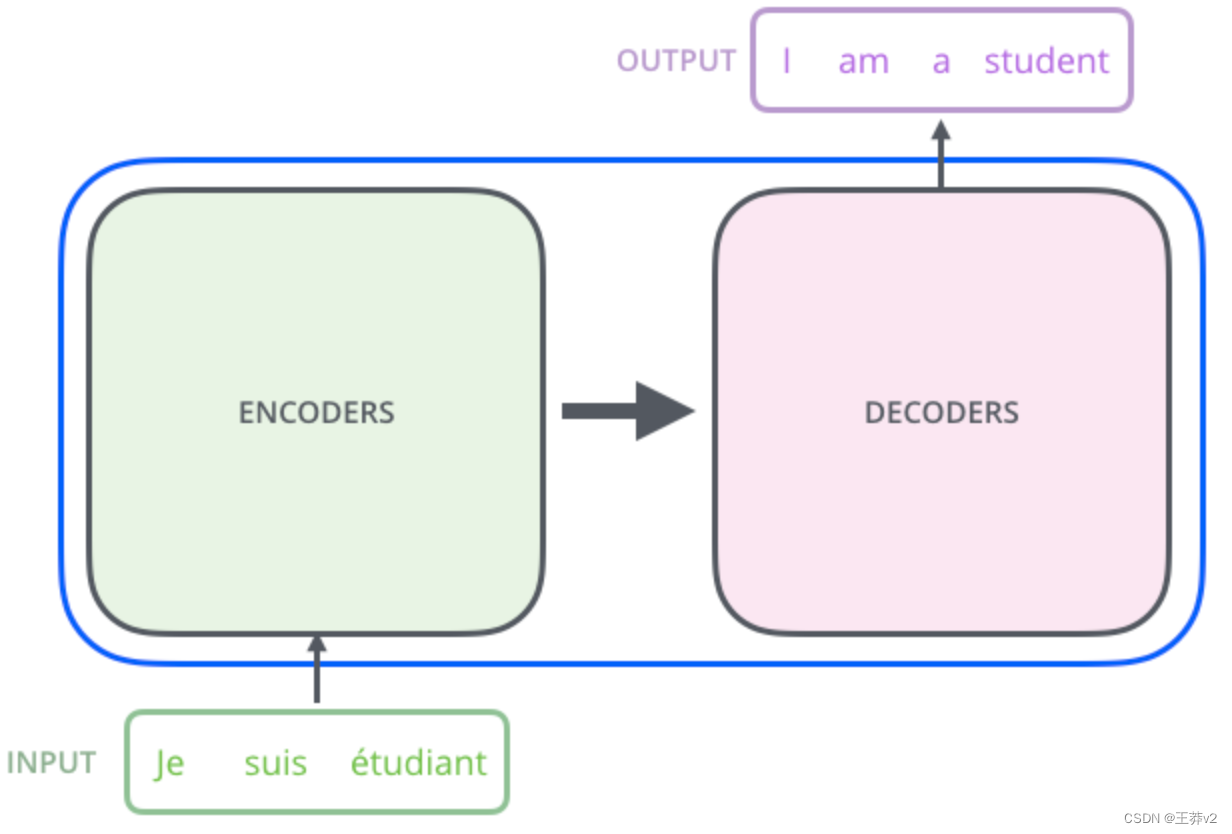
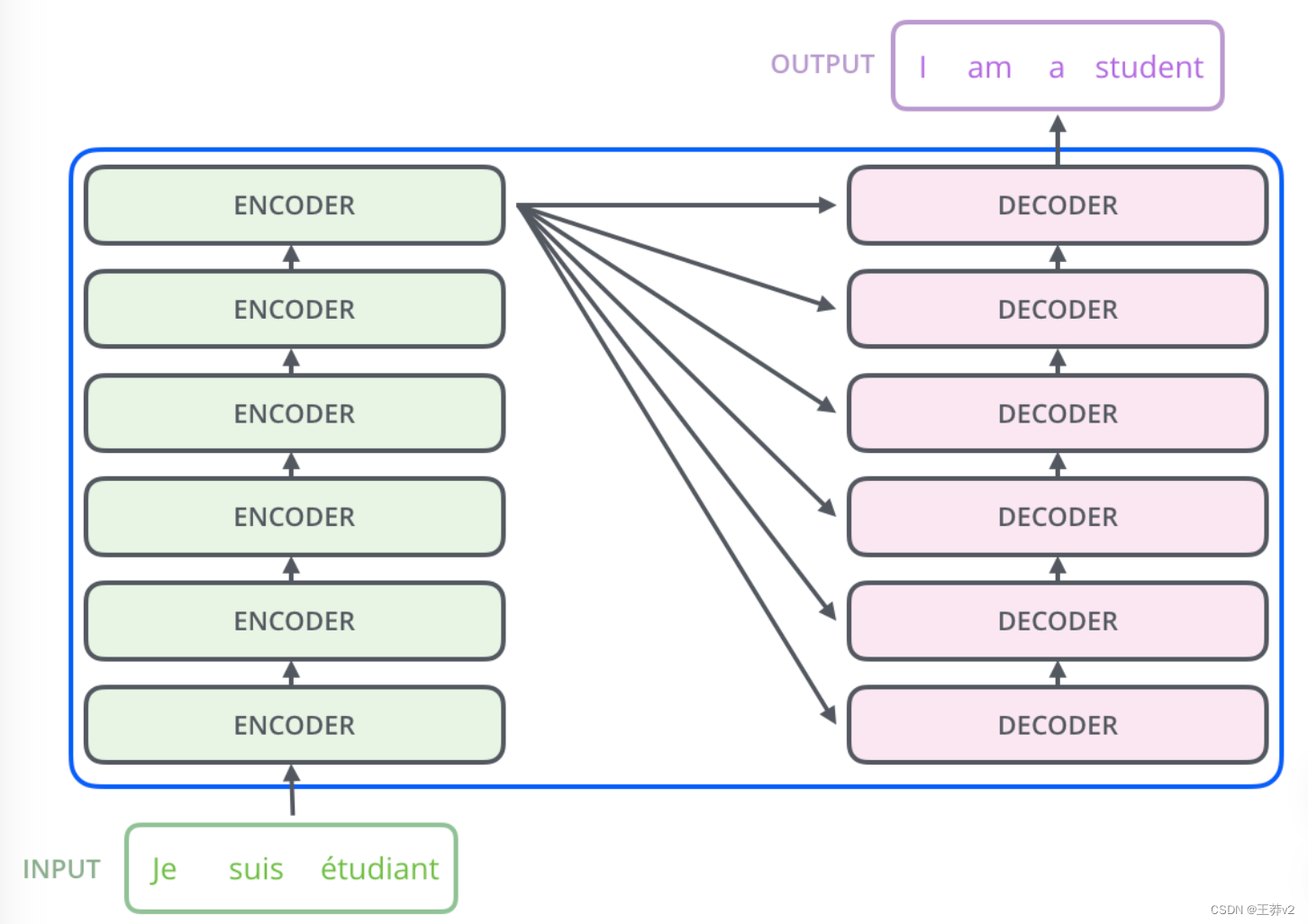
编码组件是一堆编码器(6个编码器堆叠在一起,数字6没有什么神奇的,你可以尝试其他的排列方式)。解码组件是一堆相同数量的解码器。
编码器在结构上都是相同的(但它们不共享权重)。每一层都被分解成两个子层
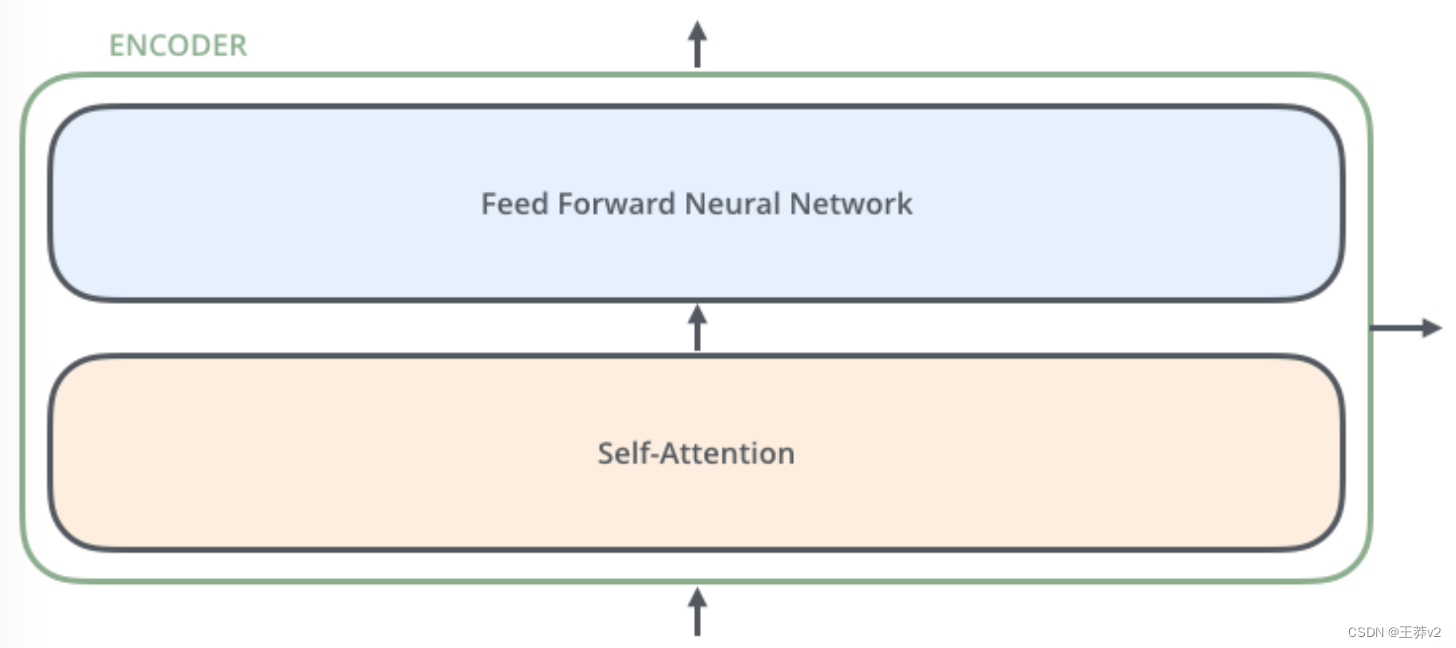
编码器的输入首先通过自注意层,这一层帮助编码器在编码特定单词时查看输入句子中的其他单词。我们将在后面的文章中详细介绍自我关注。
自注意层的输出被馈送
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8229
8229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









