







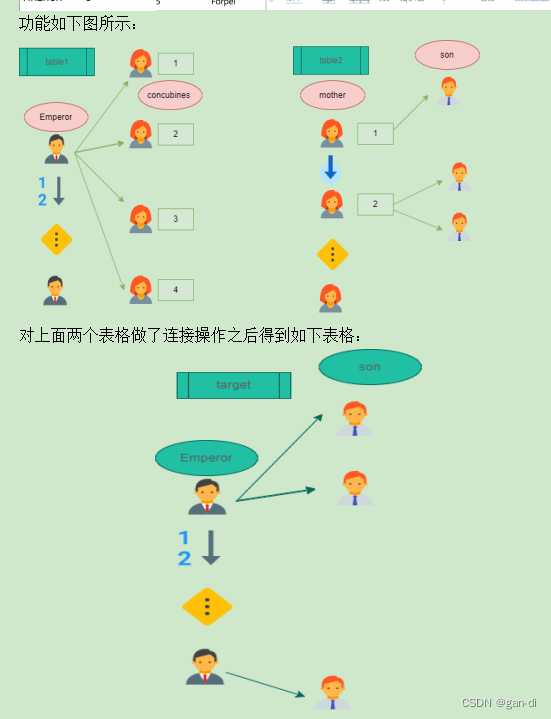
前面的基本操作参考同专栏其他文章
1.import java.io.IOException;
2.import java.util.*;
3.import org.apache.hadoop.conf.Configuration;
4.import org.apache.hadoop.fs.Path;
5.import org.apache.hadoop.io.Text;
6.import org.apache.hadoop.fs.FileSystem;
7.import org.apache.hadoop.mapreduce.Job;
8.import org.apache.hadoop.mapreduce.Mapper;
9.import org.apache.hadoop.mapreduce.Reducer;
10.import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
11.import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
12.
13.public class Multitable {
14.public static int time = 0;
15./** 在map中先区分输入行属于左表还是右表,然后对两列值进行分割,
16.* 保存连接列在key值,剩余列和左右表标志在value中,最后输出
17.*/
18.public static class Map extends Mapper<Object, Text, Text, Text> {
19.// 实现map函数
20.public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
21.String line = value.toString();// 每行文件
22.String relationtype = new String();// 左右表标识
23.// 输入文件首行,不处理
24.if (line.contains("Emperor") == true || line.contains("concubines") == true)
25.{ return; }
26.// 输入的一行预处理文本
27.StringTokenizer itr = new StringTokenizer(line);
28.String mapkey = new String();
29.String mapvalue = new String();
30.int i = 0;
31.while (itr.hasMoreTokens()) {
32.// 先读取一个单词
33.String token = itr.nextToken();
34.// 判断该地址ID就把存到"values[0]"
35.if (token.charAt(0) >= '0' && token.charAt(0) <= '9') {
36.mapkey = token;
37.if (i > 0) {relationtype = "1"; }
38.else {relationtype = "2"; }
39.continue;
40.}
41.//
42.mapvalue += token + " "; i++;
43.}
44.// 输出左右表
45.context.write(new Text(mapkey), new Text(relationtype + "+"+ mapvalue));
46.}
47.}
48./** reduce解析map输出,将value中数据按照左右表分别保存,
49.* 然后求出笛卡尔积,并输出。
50.*/
51.public static class Reduce extends Reducer<Text, Text, Text, Text> {
52.// 实现reduce函数
53.public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 输出表头
54.if (0 == time) { context.write(new Text("Emperor"), new Text("son")); time++; }
55.int factorynum = 0; String[] factory = new String[10];
56.int addressnum = 0; String[] address = new String[10];
57.Iterator ite = values.iterator();
58.while (ite.hasNext()) {
59.String record = ite.next().toString();
60.int len = record.length();
61.int i = 2;
62.if (0 == len) { continue; }
63.// 取得左右表标识
64.char relationtype = record.charAt(0); // 左表
65.if ('1' == relationtype) { factory[factorynum] = record.substring(i); factorynum++; }
66.// 右表
67.if ('2' == relationtype) { address[addressnum] = record.substring(i); addressnum++; } }// 求笛卡尔积
68.if (0 != factorynum && 0 != addressnum) {
69.for (int m = 0; m < factorynum; m++) {
70.for (int n = 0; n < addressnum; n++) {
71.// 输出结果
72.context.write(new Text(factory[m]), new Text(address[n]));
73.}
74.}
75.}
76.}
77.}
78.public static void main(String[] args) throws Exception {
79.if (args.length != 2) {
80.System.err.println("Usage: Multiple Table Join <in> <out>");
81.System.exit(2); }
82.
83.Configuration conf = new Configuration();
84.FileSystem hdfs = FileSystem.get(conf);
85.hdfs.delete(new Path(args[1]),true);
86.
87.Job job = Job.getInstance(conf);
88.job.setJarByClass(Multitable.class);
89.// 设置Map和Reduce处理类
90.job.setMapperClass(Map.class);
91.job.setReducerClass(Reduce.class);
92.// 设置输出类型
93.job.setOutputKeyClass(Text.class);
94.job.setOutputValueClass(Text.class);
95.// 设置输入和输出目录
96.FileInputFormat.addInputPath(job, new Path(args[0]));
97.FileOutputFormat.setOutputPath(job, new Path(args[1]));
98.System.exit(job.waitForCompletion(true) ? 0 : 1); }
99.}


















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











