







 该博客介绍了如何在Eclipse环境中创建一个Hadoop项目,添加所需的JAR包,编写并理解WordCount Java应用程序。程序通过MapReduce实现词频统计,最后打包并运行在Hadoop平台上。
该博客介绍了如何在Eclipse环境中创建一个Hadoop项目,添加所需的JAR包,编写并理解WordCount Java应用程序。程序通过MapReduce实现词频统计,最后打包并运行在Hadoop平台上。
打开eclipse平台
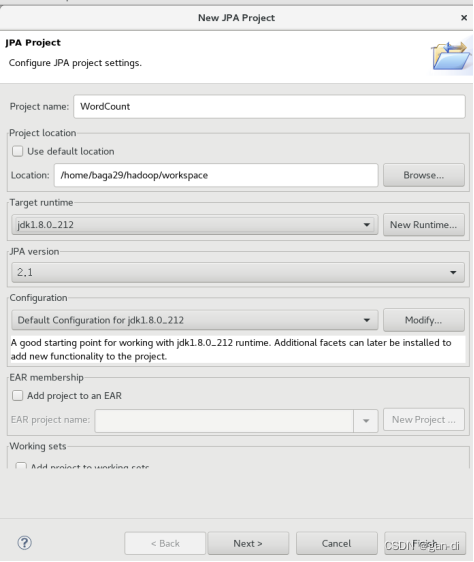
在eclipse中创建项目

点击finish。
为项目添加需要用到的JAR包
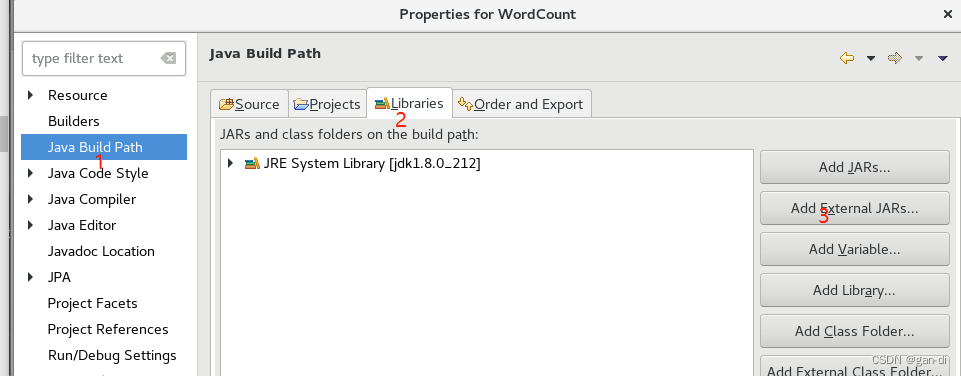
(1)“/opt/module/hadoop-3.2.2/share/hadoop/common/”目录下的hadoop-common-3.2.2.jar和haoop-nfs-3.2.2.jar;
(2)“ /opt/module/hadoop-3.2.2/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/opt/module/hadoop-3.2.2/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib、lib-examples和sources目录
(4)“/opt/module/hadoop-3.2.2/share/hadoop/mapreduce/lib”目录下的所有JAR包。
下面演示(1)的添加:
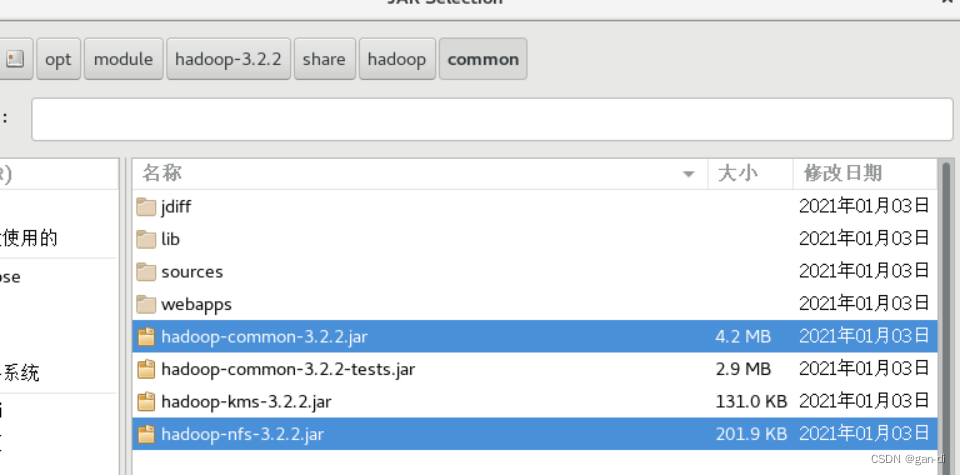
然后点击界面右下角的“确定”按钮,就可以把这两个JAR包增加到当前Java工程中依次添加即可。
最后添加如下,点击OK。
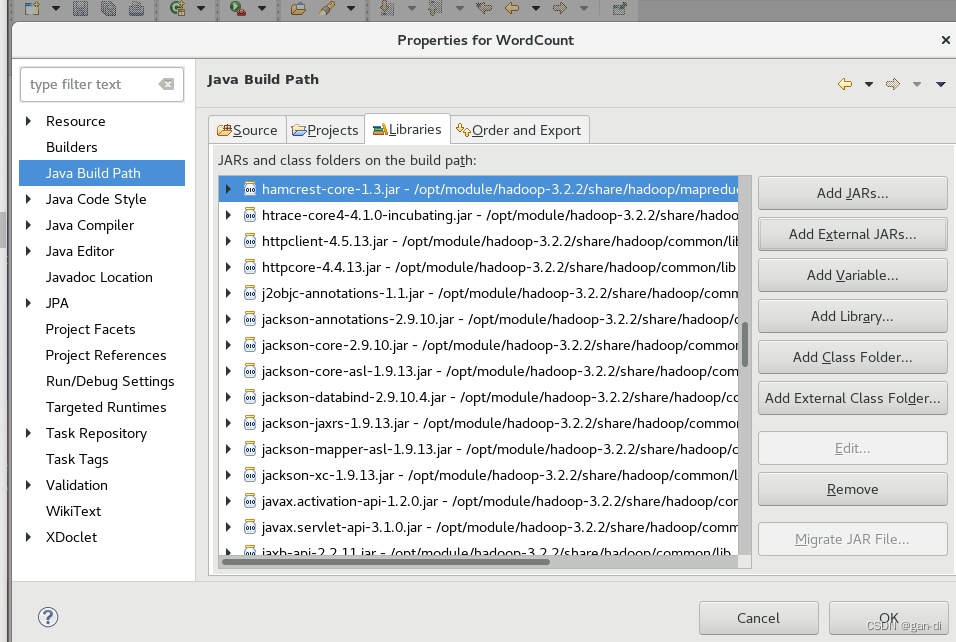
编写Java应用程序
选择Class。
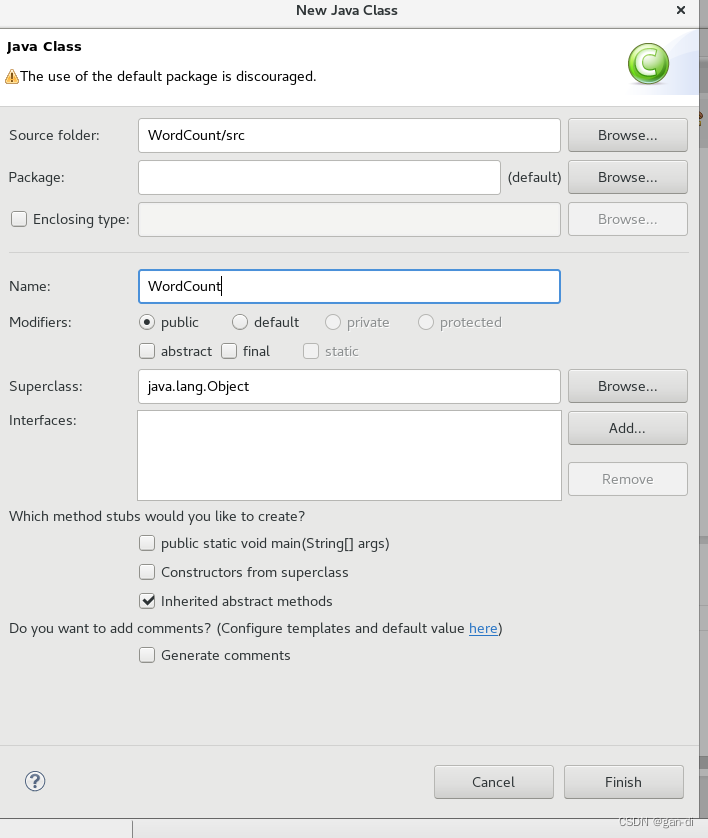
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
//Loading hadoop Configuration
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
//Validates command line input parameters
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//Create a Job instance Job and name it "word count"
Job job = Job.getInstance(conf, "word count");
//set jar
job.setJarByClass(WordCount.class);
//set mapper
job.setMapperClass(WordCount.TokenizerMapper.class);
//set combiner
job.setCombinerClass(WordCount.IntSumReducer.class);
//set reduce
job.setReducerClass(WordCount.IntSumReducer.class);
//set outputkey
job.setOutputKeyClass(Text.class);
//set outputvalue
job.setOutputValueClass(IntWritable.class);
//add input Path
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
//add output Path
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
//Wait for the job to complete and exit
System.exit(job.waitForCompletion(true)?0:1);
}
//TokenizerMapper as the Map phase, you need to inherit Mapper and rewrite the Map () function
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//Use StringTokenizer as a tokenizer to split a value
StringTokenizer itr = new StringTokenizer(value.toString());
// end after traversing the participle
while(itr.hasMoreTokens()) {
//Set String to Text word
this.word.set(itr.nextToken());
//(Word,1), that is, (Text,IntWritable), is written to the context
//for use in the subsequent Reduce phase
context.write(this.word, one);
}
}
}
//IntSumReducer as the Reduce stage, need to inherit Reducer and rewrite Reduce () functions
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
//Each val in values in the output result of map phase is iterated, and the sum is accumulated
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
//Set sum to IntWritable result
this.result.set(sum);
//Output the result (key, result) via the write() method of the context, i.e. (Text,IntWritable)
context.write(key, this.result);
}
}
}
打包编译程序
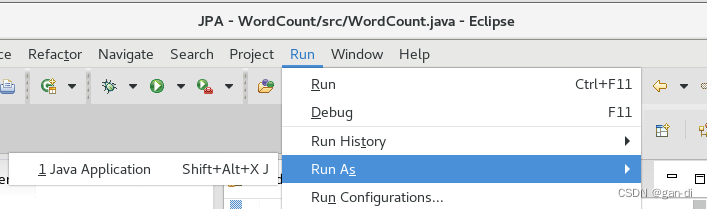
得到如下结果:
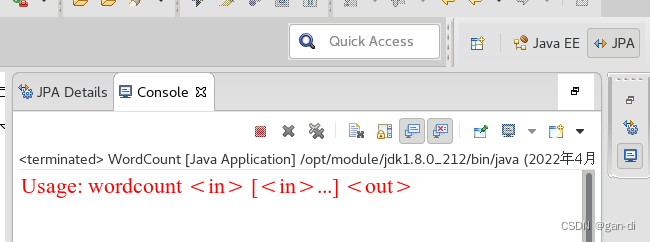
下面就可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。
点击next
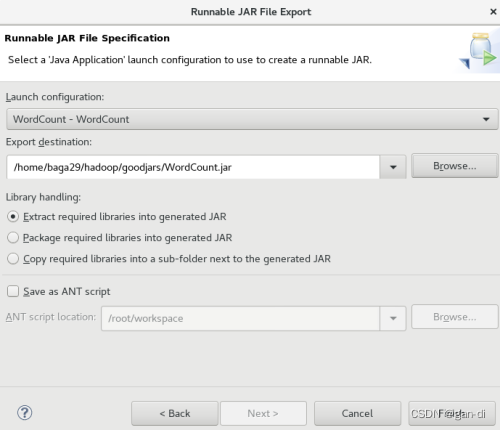
运行程序
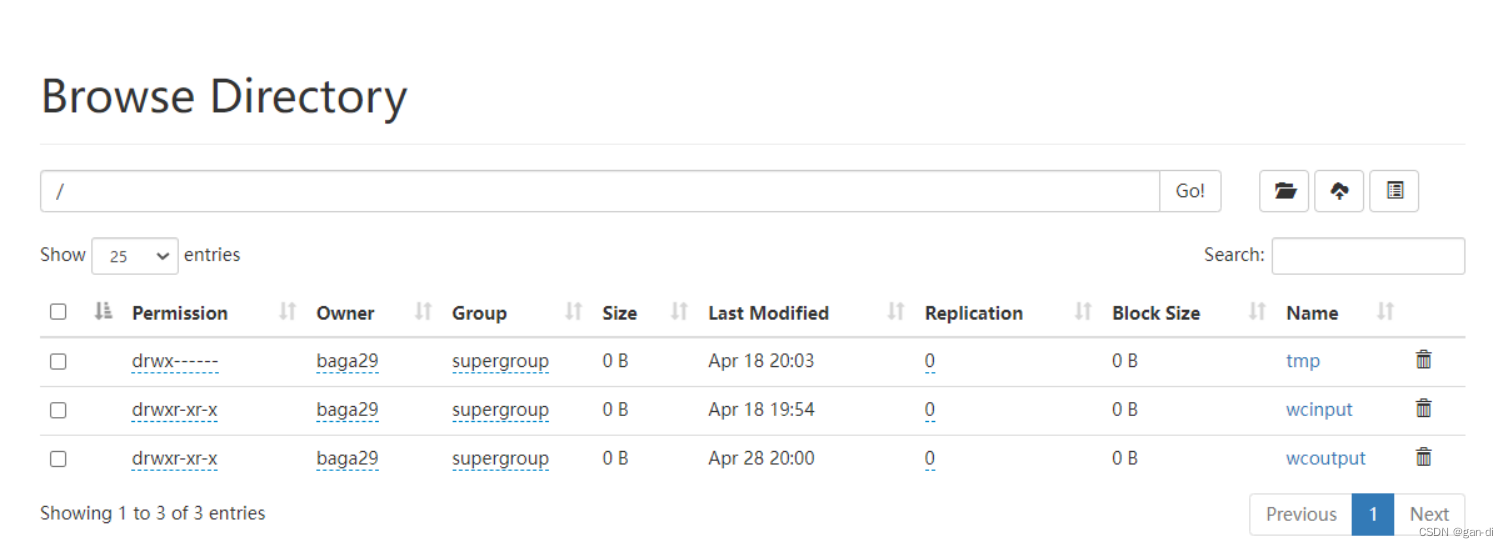
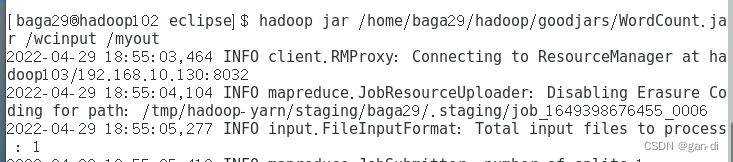
运行程序
再查看HDFS系统文件:
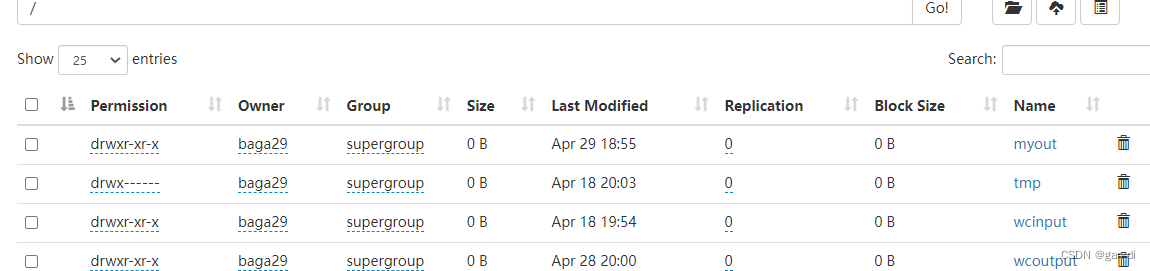
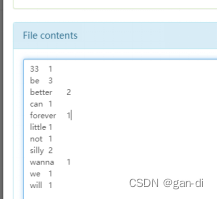
发现了myout文件,词频统计功能实现。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











