










论文地址:https://proceedings.mlr.press/v139/yang21o#/
代码地址:https://github.com/ZjjConan/SimAM
摘要:
在这篇论文里,我们提出了一种概念简单但非常有效的注意力模块,用于卷积神经网络(ConvNets)。与现有的通道式和空间式注意力模块不同,我们的模块在不增加原网络参数的情况下,为每一层的特征图推导出3D注意力权重。具体来说,我们基于一些广为人知的神经科学理论,提出优化一个能量函数来找出每个神经元的重要性。我们还为这个能量函数推导出了一个快速的封闭形式解,这个解只需要不到十行代码就能实现。这个模块的另一个优点是,大多数操作符都是基于定义的能量函数的解来选择的,这样就避免了过多的结构调整工作。在各种视觉任务上的定量评估表明,我们提出的模块既灵活又有效,能够提升许多ConvNets的表示能力。
简单来说,我们发明了一种新的注意力模块,可以让卷积神经网络更好地关注图像中重要的部分。与现有的方法不同,我们这个方法不需要给网络增加额外的参数,只需要优化一个能量函数来找出每个神经元的重要性。我们还找到了一个简单快速的解法,用几行代码就能实现。这个模块不仅灵活,而且在各种视觉任务中都表现出色,能够提升网络的性能。如果你对这个模块感兴趣,可以在Pytorch-SimAM上找到我们的代码。
原理图
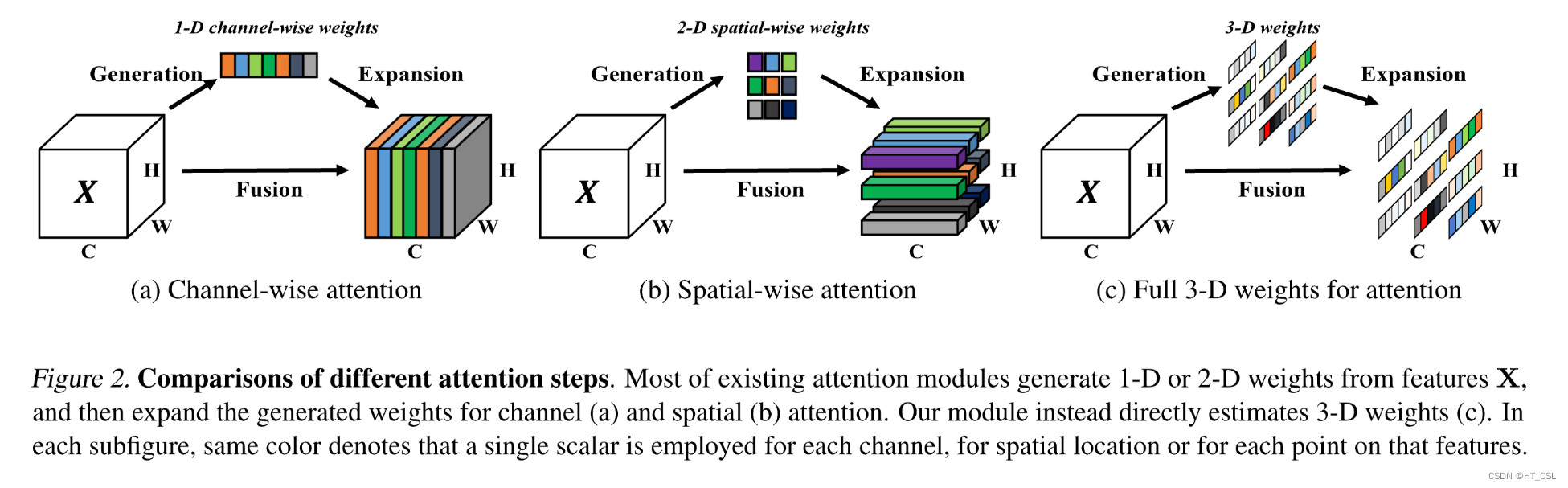
Pytorch源码:
import torch
import torch.nn as nn
class SimAM(nn.Module):
def __init__(self, lamda=1e-5):
super().__init__()
self.lamda = lamda
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 获取输入张量的形状信息
b, c, h, w = x.shape
# 计算像素点数量
n = h * w - 1
# 计算输入张量在通道维度上的均值
mean = torch.mean(x, dim=[-2,-1], keepdim=True)
# 计算输入张量在通道维度上的方差
var = torch.sum(torch.pow((x - mean), 2), dim=[-2, -1], keepdim=True) / n
# 计算特征图的激活值
e_t = torch.pow((x - mean), 2) / (4 * (var + self.lamda)) + 0.5
# 使用 Sigmoid 函数进行归一化
out = self.sigmoid(e_t) * x
return out
# 测试模块
if __name__ == "__main__":
# 创建 SimAM 实例并进行前向传播测试
layer = SimAM(lamda=1e-5)
x = torch.randn((2, 3, 224, 224))
output = layer(x)
print("Output shape:", output.shape)

















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









