










论文地址:
https://arxiv.org/pdf/1506.02025.pdf
简要介绍:
STN,也就是空间变换网络,是一种很酷的机器学习技术,它能自动地调整图像,让网络更好地处理图片的各种变化,比如扭曲或旋转。这个过程就像给图片做一个微整,让它们在变美的同时,也让计算机更容易识别。
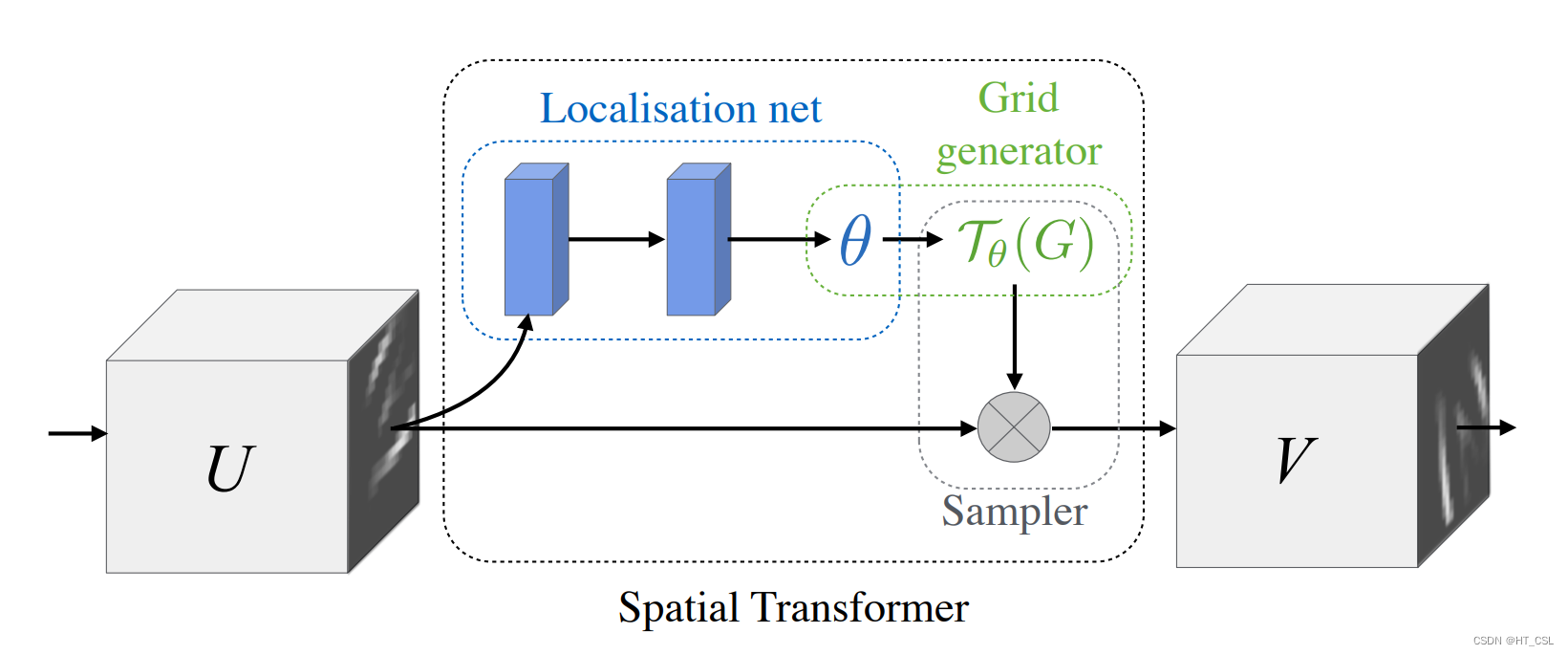
STN由三个主要部分组成:定位网络、网格生成器和采样器。定位网络负责分析图像,找出需要调整的地方,比如哪里需要拉伸,哪里需要旋转。想象一下,这就像有一支神奇的笔,能够精确地标记出图片的每个像素需要怎么移动。
网格生成器根据定位网络提供的信息,制作出一个“模板”,这个模板指导采样器如何从原始图像中取样。采样器就像一个巧手的工匠,按照这个模板,用细腻的手法从原始图片中选取正确的像素,然后把它们重新放置到新的位置,让图片达到最佳的视觉效果。
STN的好处是,它能够自我学习如何处理各种复杂的图像变换,这让它在识别图片时更加精准。而且,STN可以像搭乐高一样,和其他深度学习模型一起使用,让整个系统变得更加强大。
结构图:
Pytorch源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
class STN(nn.Module):
def __init__(self):
super(STN, self).__init__()
self.localization = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=7),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(8, 10, kernel_size=5),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True)
)
# 移除fc_loc中第一个nn.Linear的输入尺寸定义
self.fc_loc = None # 将在forward中动态创建
# 用于空间变换网络的权重和偏置初始化参数
self.fc_loc_output_params = torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float)
def forward(self, x):
xs = self.localization(x)
xs_size = xs.size()
# 动态计算全连接层的输入尺寸
fc_input_size = xs_size[1] * xs_size[2] * xs_size[3]
# 根据动态计算的输入尺寸创建fc_loc
if self.fc_loc is None:
self.fc_loc = nn.Sequential(
nn.Linear(fc_input_size, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2)
)
# 初始化空间变换网络的权重和偏置
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(self.fc_loc_output_params)
xs = xs.view(-1, fc_input_size)
theta = self.fc_loc(xs)
theta = theta.view(-1, 2, 3)
grid = F.affine_grid(theta, x.size(), align_corners=True)
x = F.grid_sample(x, grid, align_corners=True)
return x
def test_stn(input_size=(1, 1, 32, 32)):
stn = STN()
input_tensor = torch.rand(input_size)
transformed_tensor = stn(input_tensor)
print(transformed_tensor.shape)
input_image = input_tensor.numpy()[0][0]
transformed_image = transformed_tensor.detach().numpy()[0][0]
plt.figure()
plt.subplot(1, 2, 1)
plt.title("Original Image")
plt.imshow(input_image, cmap='gray')
plt.subplot(1, 2, 2)
plt.title("Transformed Image")
plt.imshow(transformed_image, cmap='gray')
plt.show()
# 测试不同尺寸的输入
# test_stn(input_size=(1, 1, 32, 32))
test_stn(input_size=(1, 1, 64, 64))

















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









