






损失函数
L1LOSS
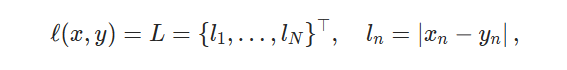
MSELoss 平方差损失
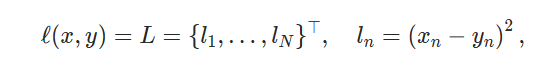
CrossEntropyLoss 交叉熵损失
通常用于分类问题中。其计算公式为:
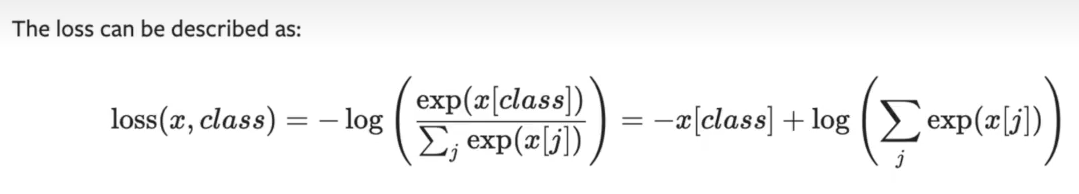
反向传播利用误差计算梯度:
import torch.nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
train_dataset = datasets.CIFAR100(root = "datasets",train=True,transform=transforms.ToTensor(),download=True)
train_dataloader = DataLoader(dataset=train_dataset,batch_size=1,shuffle=False,num_workers=0)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.models = torch.nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 512),
Linear(512, 100)
)
def forward(self,input):
output = self.models(input)
return output
model = Model()
#计算损失函数
result_loss = torch.nn.CrossEntropyLoss()
if __name__=="__main__":
for data in train_dataloader:
imgs,targets = data
output = model(imgs)
#计算误差
loss = result_loss(output,targets)
#反向传播,计算梯度
loss.backward()
优化器
在官方文档 torch.optim 中可以查找和优化器有关的属性及使用原理。
import torch.nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
train_dataset = datasets.CIFAR100(root = "datasets",train=True,transform=transforms.ToTensor(),download=True)
train_dataloader = DataLoader(dataset=train_dataset,batch_size=64,shuffle=False,num_workers=0)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.models = torch.nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 512),
Linear(512, 100)
)
def forward(self,input):
output = self.models(input)
return output
model = Model()
#计算损失函数
result_loss = torch.nn.CrossEntropyLoss()
#设置优化器
optim = torch.optim.SGD(model.parameters(),lr=0.01)
if __name__=="__main__":
for epoch in range(20):
running_loss = 0.0
for data in train_dataloader:
imgs,targets = data
output = model(imgs)
#计算误差
loss = result_loss(output,targets)
#重置优化器
optim.zero_grad()
# 反向传播,计算梯度
loss.backward()
#更新参数
optim.step()
running_loss = running_loss+loss
print(running_loss)
模型的保存及加载
保存模型的两种方式:
方式一:(保存模型架构及参数)
torch.save(model,"保存路径及保存文件名")
方式二:(仅保存模型参数)
torch.save.(model.state_dict(),"保存路径及保存文件名") #该方式以字典的形式保存参数
加载模型的两种方式:
from train_model(模型保存的文件) import *
方式一:(对应第一种保存方式的加载方式)
model = torch.load("模型文件")
方式二:(对应第二种保存方式的加载方式)
class model(torch.nn.Module):
...
model.load_state_dict(torch.load("模型文件"))
python 中的字符串格式化输出:
##其中train_data_size 为一个变量
print("训练集的长度为:{}".format(train_data_size))
#若train_data_size =10
#则上述语句会输出: 训练集的长度为: 10
使用GPU训练模型
方法一:
步骤:
- 找到模型
- 找到数据(输入和target)
- 找到损失函数
- 对上述东西调用**.cuda()**
伪代码:
train_datasets = ....
if cuda.is_available():
train_datasets = train_datasets.cuda()
class model(torch.nn.Module):
def __init__(self):
pass
def forward(self,input):
pass
lei = model()
#将模型放到cuda中去
if cuda.is_available():
lei = lei.cuda()
可使用Google的Colaboratory提供的免费的GPU训练
完整项目(以CIFAR10为例):
主函数(cifar-10_train.py):
在主函数中,完成了数据读取、模型训练、模型保存等步骤。同时会保存10次每次的模型参数,同时会将每个epoch中的loss值写入tensorboard。
import torch.nn
import torchvision.transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
trian_datasets = datasets.CIFAR10(root="datasets",train=True,download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()]))
train_dataloader = DataLoader(dataset=trian_datasets,batch_size=64,shuffle=True)
'''构建模型'''
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.conv1 = torch.nn.Conv2d(3,32,5,padding=2)
self.pooling = torch.nn.MaxPool2d(2)
self.conv2 = torch.nn.Conv2d(32,32,5,padding=2)
self.conv3 = torch.nn.Conv2d(32,64,5,padding=2)
self.flatten = torch.nn.Flatten()
self.linear1 = torch.nn.Linear(1024,64)
self.linear2 = torch.nn.Linear(64,10)
def forward(self,input):
output = self.conv1(input)
output = self.pooling(output)
output = self.conv2(output)
output = self.pooling(output)
output = self.conv3(output)
output = self.pooling(output)
output = self.flatten(output)
output = self.linear1(output)
output = self.linear2(output)
return output
model = Model()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
'''优化和损失函数'''
critizer = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
'''训练模型'''
def train(epoch):
running_loss = 0
steps = 0
for data in train_dataloader:
imgs,target = data
imgs = imgs.to(device)
target = target.to(device)
output = model(imgs)
#计算误差
loss = critizer(output,target)
#优化函数
optimizer.zero_grad()
loss.backward()
optimizer.step()
if steps % 49 == 0 :
print("第{}个batch训练的loss值为:{}".format(steps+1,loss))
steps = steps + 1
running_loss = running_loss + loss.item()
return running_loss
if __name__ == '__main__':
print("Train Start!")
writer = SummaryWriter("logs")
for epoch in range(50):
loss = train(epoch)
print("-----------第{}轮的loss值为:{}-------------".format(epoch+1,loss))
torch.save(model,"chack_point/model_{}.pth".format(epoch))
writer.add_scalar("loss",loss,epoch)
writer.close()
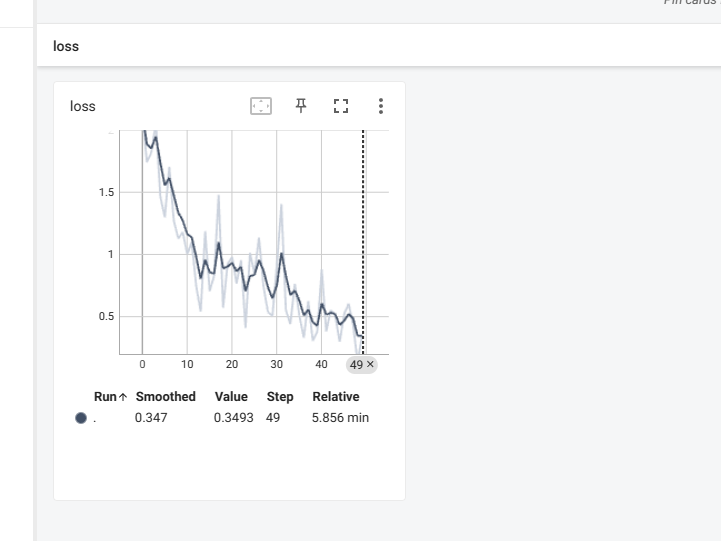
得到模型的loss结果和epoch如下图所示:
测试函数(cifar-10_test.py):
import torch
from cifar10_train import *
test_datasets = datasets.CIFAR10(root="../datasets",train=False,download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()]))
test_dataloader = DataLoader(dataset=test_datasets,batch_size=64,shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load("chack_point/model_9.pth")
with torch.no_grad():
for data in test_dataloader:
imgs,target = data
imgs = imgs.to(device)
target = target.to(device)
output = model(imgs)
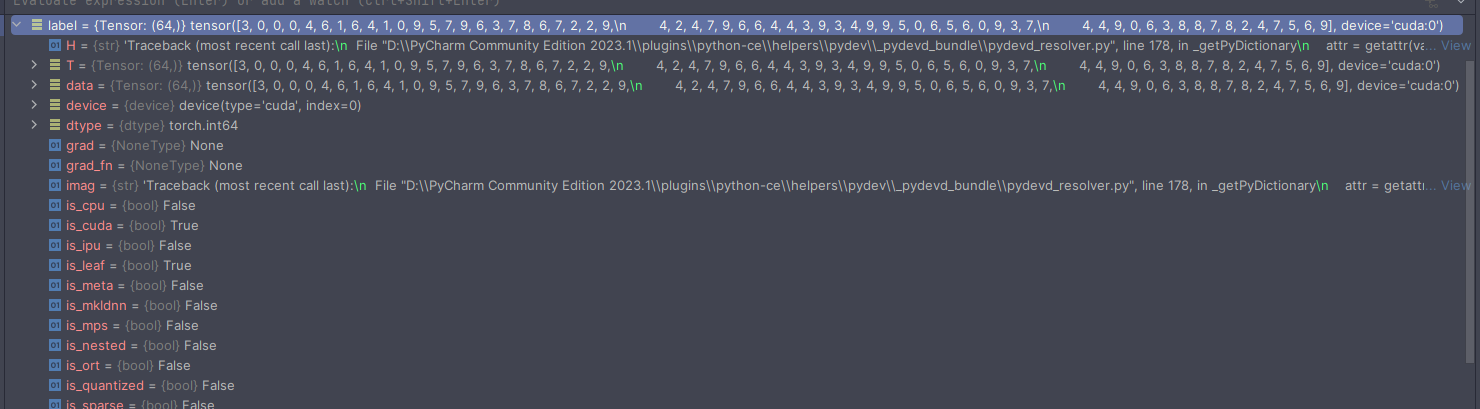
label = output.argmax(1) #获取每一行的最大值,从而判断出最有可能的分类情况
在此问题中,测试函数得到的output值一个64*10的矩阵

而此处的label也获得了每一行的最大值,即为最大可能性分类。
分类测试(test.py):
import cv2
import torch
from torchvision import transforms, datasets
test_datasets = datasets.CIFAR10("E:/Pytorch_Study/TuDui_pytorch/NetWork/datasets")
index = test_datasets.class_to_idx
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.conv1 = torch.nn.Conv2d(3,32,5,padding=2)
self.pooling = torch.nn.MaxPool2d(2)
self.conv2 = torch.nn.Conv2d(32,32,5,padding=2)
self.conv3 = torch.nn.Conv2d(32,64,5,padding=2)
self.flatten = torch.nn.Flatten()
self.linear1 = torch.nn.Linear(1024,64)
self.linear2 = torch.nn.Linear(64,10)
def forward(self,input):
output = self.conv1(input)
output = self.pooling(output)
output = self.conv2(output)
output = self.pooling(output)
output = self.conv3(output)
output = self.pooling(output)
output = self.flatten(output)
output = self.linear1(output)
output = self.linear2(output)
return output
model = torch.load("../chack_point/model_9.pth",map_location="cpu")
img = cv2.imread("picture/cat4.png")
print(img.shape)
tansform = transforms.Compose([transforms.ToTensor(),transforms.Resize((32,32),antialias=True)])
imgs = tansform(img)
imgs = torch.reshape(imgs,(1,3,32,32))
output = model(imgs)
exp = torch.argmax(output)
for key,value in index.items():
if exp == value:
print("该图片是:{}".format(key))

















 1707
1707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









