







 本文介绍了如何使用Plotly与Pandas进行数据可视化,包括快速入门的基本线形图和柱状图,利用Cufflinks进行自定义绘图。此外,文章还探讨了Pandas的数据结构,如Series和DataFrame,以及访问和操作数据的方法,包括描述性统计分析。
本文介绍了如何使用Plotly与Pandas进行数据可视化,包括快速入门的基本线形图和柱状图,利用Cufflinks进行自定义绘图。此外,文章还探讨了Pandas的数据结构,如Series和DataFrame,以及访问和操作数据的方法,包括描述性统计分析。
目录
Plotly与Pandas
Plotly可以识别Pandas数据格式,所以如果数据是Pandas的DataFrame或Series结构,那么就不用转换成list数据格式,直接传递给Plotly。
快速入门
基本线形图
import plotly as py
import plotly.graph_objs as go
import pandas as pd
import numpy as np
pyplt=py.offline.plot
N=500
x=np.linspace(0,1,N)
y=np.random.randn(N)
df=pd.DataFrame({'x':x,'y':y})
df.head()
data=[go.Scatter(x=df['x'],y=df['y'])]
url=pyplt(data,filename='基本线性图.html')
结果:
基本柱状图
import plotly as py
import plotly.graph_objs as go
import pandas as pd
import numpy as np
pyplt=py.offline.plot
N=40
x=np.linspace(0,1,N)
y=np.random.randn(N)
df=pd.DataFrame({'x':x,'y':y}) #字典结构
df.head()
data=[go.Bar(x=df['x'],y=df['y'])]
url=pyplt(data,filename='基本柱状图2.html')
结果:
使Cufflinks绘图
为了方便绘图,Plotly为Pandas做了特殊的封装,这个封装模块就是Cufflinks,它的作用是改变Pandas绘图的默认呈现方式。Pandas绘图默认的呈现方式是Matplotlib,Cufflinks把这种呈现方式改为Plotly。这个包用`pip`安装即可。
Cufflinks目前只能在Jupyter Notebook中使用,需要打开Jupyter Notebook运行。如果在pycharm中无法创建相应文件(我的编程环境为pycharm),那么可以在cmd中运行命令“jupyter notebook”,打开网页即可。在右上方NEW可以打开新的文件,进而利用Notebook进行代码编写。
安装cufflinks最好在cmd进行:pip install cufflinks
快速入门
import chart_studio.plotly as py
import cufflinks as cf
import numpy as np
import pandas as pd
cf.set_config_file(offline=True,theme='ggplot')
N=500
x=np.linspace(0,1,N)
y=np.random.randn(N)
df=pd.DataFrame({'x':x,'y':y})
df.set_index('x',inplace=True)
df.iplot(kind='scatter',filename='快速入门.html')#cufflinks只支持iplot绘图模式,不支持plot
结果:
cufflinks并不改变Pandas的使用方式,只是在底层把Pandas绘图结果的呈现方式由Matplotlib改变为Plotly。
设置Pandas的输出模式:
cf.set_config_file(offline=True,theme='ggplot')
采用线下绘图,主题采用了R语言中的ggplot主题。cufflinks已经封装了好多种主题,包括polar、pear等,通过cf.getThemes()方法可以获取所有主题。
快速获取数据
快速生成数据并绘制图形:
import chart_studio.plotly as py
import cufflinks as cf
import numpy as np
import pandas as pd
cf.set_config_file(offline=True,theme='polar')
df=cf.datagen.scatter()#快速生成散点图数据
df.iplot(kind='scatter',mode='markers',x='x',y='y')
代码解析:
cf.datagen是cufflinks封装好的生成Pandas数据的模块,里面包含了常见的绘图(如bar/scatter/ohlc/pie)数据所需要的函数。可以通过dir(cf.datagen命令查看可用的数据)。
结果:
自定义绘图
cufflinks的绘图函数df.iplot功能比较强大,参数也比较多。
import chart_studio.plotly as py
import cufflinks as cf
import numpy as np
import pandas as pd
cf.set_config_file(offline=True,world_readable=True)
df=cf.datagen.lines(n_traces=3,columns=['one','two','three'])#生成一个3列的DataFrame
colors=['red','blue','black']
dashes=['solid','dash','dashdot']
widths=[2,3,4]
plot_url=df.iplot(kind='scatter',mode='lines',colors=colors,dash=dashes,width=widths,xTitle='日期',yTitle='数量',title='自定义绘图')
结果:
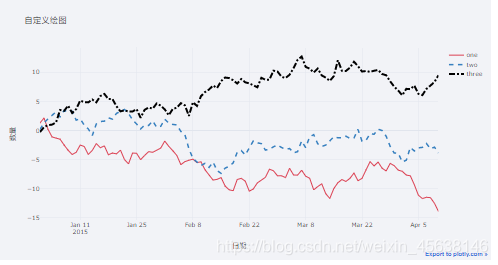
更多案例
(1)获取cufflinks的源代码或最新版信息link.
(2)获取更多案例代码,可以在上面打开的链接选择Chart Gallery链接
(3)想要获取更为高级的代码,可以在上面打开的网页选择Pandas Like Visualization链接。
Pandas统计分析
Pandas数据结构
Pandas是一个非常重要的数据统计分析库,包含了众多API,使得数据分析变得简单高效。Pandas建立在Numpy之上,提供了多种统计分析功能,这些功能主要基于两个核心的数据库:序列(Series)和数据帧(DataFrame)。
数据结构
序列是一维数组;数据帧是二维数组,可以理解为表格;面板是三维数组。
序列
可以通过很多种方法创建序列,例如:
1.通过NumPy数组创建序列
import pandas as pd
import numpy as np
init_data=np.array(['hello','world','python'])
data=pd.Series(init_data)
print(data)
结果:
2.通过字典创建:
import pandas as pd
init_data= {"name":"Ivy","age":10}
data=pd.Series(init_data)
print(data)
3.通过列表创建:
import pandas as pd
init_data=["hello","world","python"]
data=pd.Series(init_data)
print(data)
数据帧
数据帧可以看成一个表格,创建方法跟序列差不多。
1.通过列表创建:
import pandas as pd
init_data=[{"name":"Wilson","age":15,"gender":"man"},
{"name":"Ivy","age":25,"gender":"woman"}]
data=pd.DataFrame(init_data)
print(data)
2.通过字典创建,将key作为列:
import pandas as pd
init_data={"name":["Wilson","Bruce","Chelsea"],"age":[15,24,19],"gender":["man","man","woman"]}
data=pd.DataFrame(init_data)
print(data)
访问数据
选择行
import pandas as pd
series={"name":pd.Series(["Wilson","Bruce","Chelsea"],index=["user1","user2","user3"]),
"age":pd.Series([15,24,19],index=["user1","user2","user3"]),
"gender":pd.Series(["man","man","woman"],index=["user1","user2","user3"])}
df=pd.DataFrame(series)
print(df)
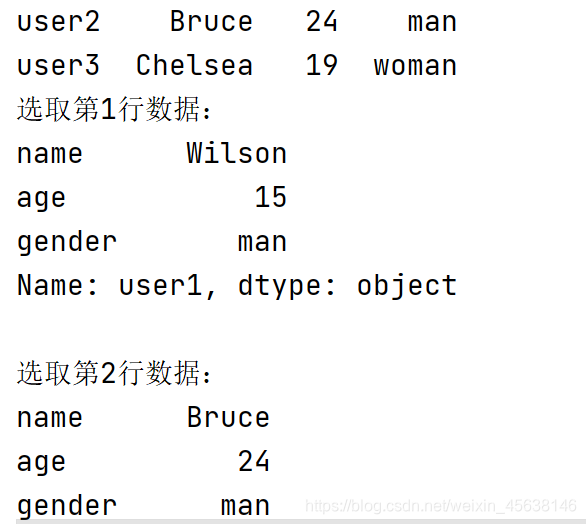
#访问行数据,需要用loc方法,通过传入行名称来选取行
print("选取第1行数据:")
print(df.loc["user1"])
print("")
print("选取第2行数据:")
print(df.loc["user2"])
结果:
添加行
使用append方法:
import pandas as pd
series={"name":pd.Series(["Wilson","Bruce","Chelsea"],index=["user1","user2","user3"]),
"age":pd.Series([15,24,19],index=["user1","user2","user3"]),
"gender":pd.Series(["man","man","woman"],index=["user1","user2","user3"])}
df=pd.DataFrame(series)
df1=pd.DataFrame({"name":["Lucy"],"age":[27],"gender":["woman"]})
df=df.append(df1)
print(df)
结果:

删除行
调用drop方法:
import pandas as pd
series={"name":pd.Series(["Wilson","Bruce","Chelsea"],index=["user1","user2","user3"]),
"age":pd.Series([15,24,19],index=["user1","user2","user3"]),
"gender":pd.Series(["man","man","woman"],index=["user1","user2","user3"])}
df=pd.DataFrame(series)
df=df.drop("user1")
print(df)

列操作
只需要通过df["列名“]即可获得相应列,删除列只需通过df.pop(列名)

















 4181
4181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









