






 本文介绍如何利用Pandas清理Kaggle数据集,并借助Plotly进行数据可视化,尤其是创建分级统计图来展示地理区域的趋势和模式。通过删除冗余列和排序,分析最新数据,然后使用GeoPandas和Plotly Express创建基于确诊病例的印度邦分级统计图,以加深对数据的理解。
本文介绍如何利用Pandas清理Kaggle数据集,并借助Plotly进行数据可视化,尤其是创建分级统计图来展示地理区域的趋势和模式。通过删除冗余列和排序,分析最新数据,然后使用GeoPandas和Plotly Express创建基于确诊病例的印度邦分级统计图,以加深对数据的理解。
全文共1948字,预计学习时长8分钟

图源:unsplash
设想一下,自己正在说服客户投资公司,拿着员工成就记录的excel表格就直接给客户看了。换位思考,如果你是客户的话会有什么反应?数据太多难道不会让人感到不知所措吗?讲真的,数据可视化了解一下。
数据可视化是将原始数据转换成可视化的图形和图表,从而更易于理解,它的主要目的是更快地进行研究和数据分析,并有效传达趋势和模式。
相较于冗长的纯文本,人脑能够更好地理解具有视觉吸引力的数据。
图源:Dribbble

kaggle数据集的清理和可视化
本文将在Kaggle选取一个数据集,按照要求清理数据,并尝试将数据可视化。
首先,要从外部源加载数据并对其进行清理,这将会用到Pandas库。在使用Pandas库之前先要有序导入,可以通过使用Pandas进行导入。
import pandas as pd
接着加载从Kaggle获取的CSV文件,并尝试了解更多信息。
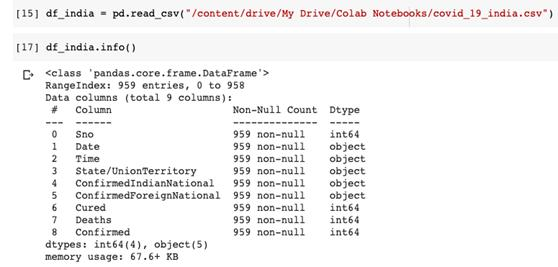
可以看到数据集共有9列。“日期(Date)”和“时间(Time)”列显示上次更新的日期和时间。因为不会用到“印度确诊病例”和“国外确认病例”,所以先删除这两列。“时间”(Time)列也并不重要,也将其删除。由于Data Frame中已经有索引,“序列号”(Sno)一列也是不需要的。
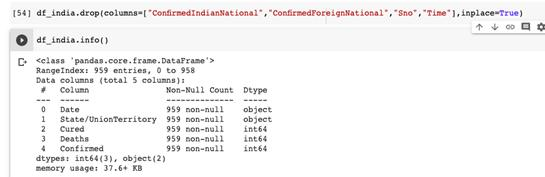
现在可以看到,数据帧只有5列数据。删除冗余数据是个好习惯,因为保留冗余数据会占用不必要的空间,可能会导致运行中断。
此处的Kaggle数据集每天都会更新,添加新数据并不会覆盖原有数据。例如,4月13日的数据集有925行,每行代表一个特定邦的累积数据。但在4月14日,数据集有958行,这意味着4月14日添加了34 行新数据。
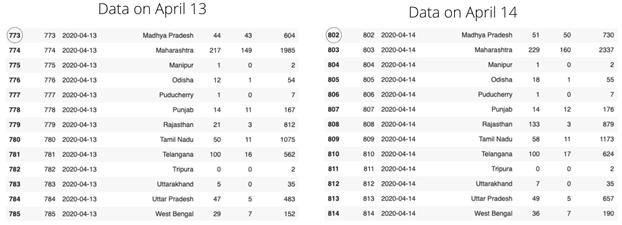
上图中可以看到相同的邦名,但试着观察其他列发生的变化。有关新确诊病例的数据每天都被添加到数据集中,这种数据形式有助于了解传播趋势。比如随时间增加的病例数,或者是进行时间序列分析。
但我们只想分析最新数据,而不是分析以往的数据,因此可以删掉那些多余行。首先,按日期降序排列数据,并通过使用邦名对数据进行分组,消除重复值。
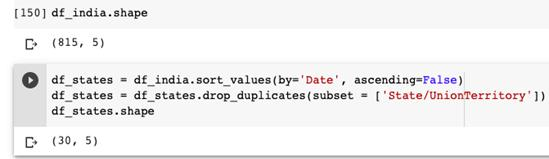
可以看到,df_states数据帧只有30行,这意味着有一行专门显示每个邦的最新统计数据。在使用日期列对数据帧进行排序时,将按照日期降序对数据帧进行排序(注意代码中升序=False),
remove_duplicates会保存首个匹配值,并删除所有重复值。
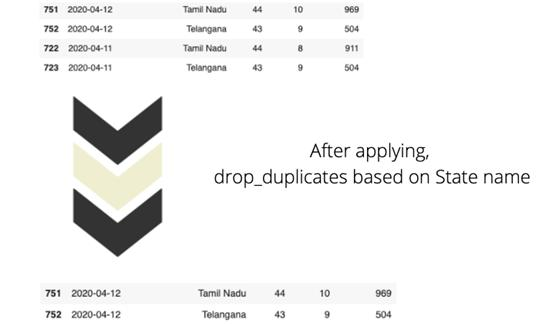
现在来聊聊数据可视化。我们将使用Plotly对上述数据帧进行可视化。柱状图、条形图、散点图都能有效解释模式和趋势,但由于要处理的是地理数据,所以笔者更建议使用分级统计图。
什么是分级统计图?
运用Plotly绘制,分级统计图按照地理区域进行划分,这些区域相对于数据变量被涂上颜色或阴影。这些图表能够简单快捷地显示一个地理区域的数据值,表现出趋势和模式。
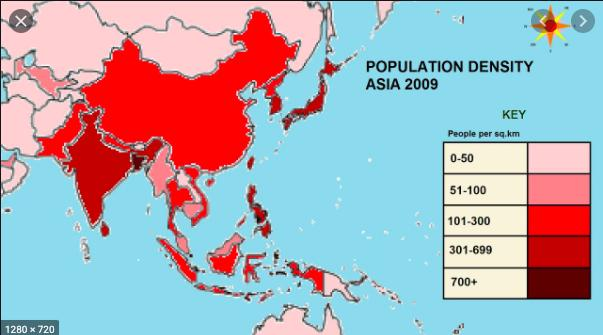
图源:Youtube
上图中,各个区域根据人口密度呈现不同颜色。颜色越深意味着该地区人口越多。现在针对我们的数据集,创建一个基于确诊病例的分级统计图。确诊病例越多,特定区域的颜色就越深。
如果想绘制一张印度地图,需要一个带有邦坐标的shapefile文件。维基百科告诉我们,shapefile格式就是地理信息系统(GIS)的地理空间矢量数据格式。
在使用shapefile文件之前,需要安装GeoPandas,这是一个python软件包,可以轻松处理地理空间数据。
pip install geopandas
import geopandas as gpd
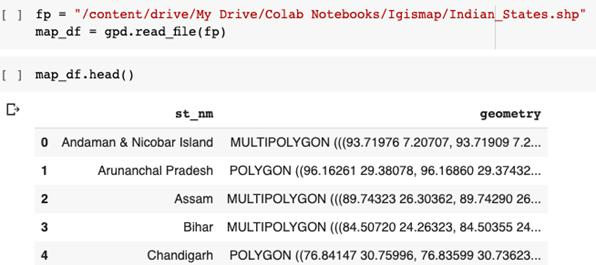
可以看到数据帧有一列是邦名,且其坐标为矢量形式。现在要把这个shapefile格式转换成所需的JSON格式。
import json#Read data tojson.merged_json = json.loads(map_df.to_json())
下一步,使用Plotly Express.’ 的px.choropleth函数创建分级统计图。制作分级统计图需要几何信息:
· 这可以由GeoJSON格式(上文已创建)提供,其中每个特性都具有唯一标识值(比如本例中的st-nm)
· Plotly中包含美国和世界其他各国在内的现有几何信息
GeoJSON数据(即上文创建的merged_json)被传递给geojson参数,度量值被传递给px.choropleth的color参数。
每个分级统计图都有一个locations参数,该参数以邦/国家为参量。因为要为印度的不同邦创建一个分级统计图,所以我们将State列传递给参数。
fig = px.choropleth(df_states,
geojson=merged_json,
color="Confirmed",
locations="State/UnionTerritory",
featureidkey="properties.st_nm",
color_continuous_scale =["#ffffb2","#fecc5c","#fd8d3c","#f03b20","#bd0026"],
projection="mercator"
)fig.update_geos(fitbounds="locations",visible=False)fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})fig.show()
第一个参量是数据帧本身,颜色深浅将根据确诊病例数值而变化。将fig.updtae_geos()中的visible 参数设置为False,从而隐藏基本图表和框架。还可以将fitbounds = "locations"设置为自动缩放世界地图,显示人们感兴趣的区域。
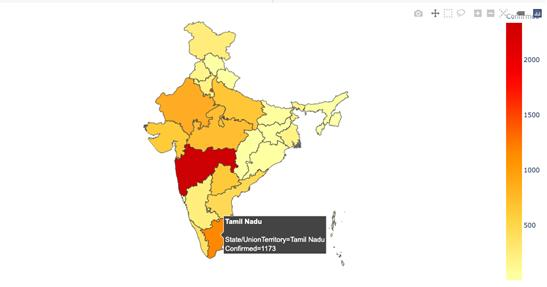
可以将鼠标放在各个区域上,了解更多相关信息。
数据可视化从前是一门被忽视的艺术,如今它的重要性逐渐被人们注意到了。这里讲到的只是处理数据的其中一种方法,事实上,数据可视化的世界千变万化,等待你去探索。

我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









