







(一)理论基础
数组时存放在连续内存空间上相同类型数据的集合
注意点:
a.数组下标都是从0开始
b.数组内存空间的地址是连续的
(二)相关例题
1.二分查找
二分查找
题目中数组的特点是有序
步骤:
a.定义区间的两端
d.对区间中的具体数值进行条件判断
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0; //定义区间的两端
int right = nums.size()-1;
while(left<=right){ //对目标值和中值进行判断,3种情况
int middle = left + (right - left)/2;
if(nums[middle]>target){
right = middle;
}else if(nums[middle]<target){
left = middle;
}else{
return middle;
}
}
return -1;
}
};
2.移除元素
移除元素
要求:原地移除所有数值等于目标值的元素
步骤:
a.定义两个指针,一个用来遍历,一个用来记录剩下的元素
b.遍历时对具体数值的判断
(刚开始犯的错误是,判断当值相等时怎么删除,然而在数组的存储中用值覆盖值就自然而然的删除了)
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int slowIndex = 0; //用来记录数组长度
for(int i = 0; i<nums.size();i++){ //for 循环中也相当于一个下标指针
if(nums[i]!=val){
nums[slowIndex++] = nums[i];
}else{
}
}
return slowIndex;
}
};
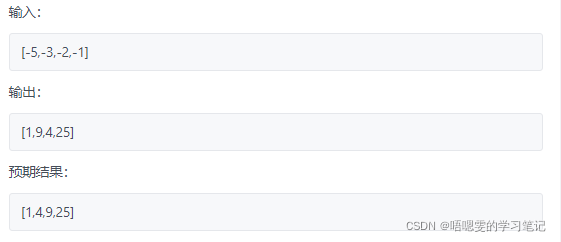
3.有序数组的平方
有序数组的平方
最简单的想法,每个数平方再排序;
数组平方后还是有一定的顺序
步骤:
a.定义一个新的数组
b.计算数组两端的平方值
c.比较两数的平方值
d.将较大的先放入数组后面,更新指针的具体值
数组的下标和数组的长度要做注意区分
错误示范
解决办法再额外再定义一个新的数组
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
for(int k = nums.size()-1;k!=-1;k--){
int nums1 = nums[0]*nums[0];
int nums2 = nums[k]*nums[k];
if(nums1<nums2){
nums[k] = nums2;
}else{
nums[0] = nums[k]; //错误点在自己打乱了数组元素的顺序,交换了两个元素的值
nums[k] = nums1;
}
}
return nums;
}
};
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int k = nums.size() - 1;
vector<int>result(nums.size(),0);
for(int i = 0,j = nums.size()-1;i<=j;){ //如果是小于的话会导致最后一个元素的排序上出错
if(nums[i]*nums[i]<nums[j]*nums[j]){
result[k--] = nums[j]*nums[j];
j--;
}
else{
result[k--] = nums[i]*nums[i];
i++;
}
}
return result;
}
};
4.长度最小的子数组
长度最小的子数组
滑动窗口,不断调整子序列的起始位置
步骤:
窗内元素的移动,
窗口起始位置的移动,
窗口结束位置的移动。
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int result = INT32_MAX; //最大的int整数,是为了比较子串的长度
int sum = 0;
int i = 0;
int subLength = 0;
for(int j = 0;j<nums.size();j++){
sum +=nums[j]; //先固定滑动窗口的初始端,累加
while(sum>=target){ //再固定滑动窗口的末尾端,减少元素数目
subLength = j-i+1;
result = result <subLength?result:subLength;
sum-=nums[i++];
}
}
//如果result没有被赋值,就返回0,说明没有符合条件的子序列
return result == INT32_MAX?0:result;//
}
};
5.螺旋矩阵
螺旋矩阵
每一个方向都要坚持相同的开闭方式
步骤:
vector<vector<int>> res(n, vector<int>(n, 0)); // 使用vector定义一个二维数组
a.对n 数组的分析
奇偶性判断;
b.对螺旋赋值的分析
螺旋圈数:n/2的整数部分;
绕圈需要的变量:起始位置、四个方向的遍历、边界条件的判断、每一圈的偏移量
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>>res(n,vector<int>(n,0));//定义一个二维数组
int count = 1;//赋值元素的值
int offset = 1;//每绕一圈边界就会有一个偏移量
int startx = 0, starty = 0;//绕圈的起始位置
int loop = n/2;//绕圈的圈数
int mid = n/2;//对中间值单独处理
while(loop--){
int x = startx, y = starty;//每一圈的起点
//从左到右遍历赋值(左闭右开),尝试过程中在y处加了等号,就会导致角落处元素被重复赋值
for(;y<n-offset;y++){
res[x][y] = count;
count++;
}
//从上到下赋值
for(;x<n-offset;x++){
res[x][y] = count;
count++;
}
//从右到左赋值
for(;y>starty;y--){
res[x][y] = count;
count++;
}
//从下到上赋值
for(;x>startx;x--){
res[x][y] = count;
count++;
}
//循环结束后更新相关的变量,(写代码时被忽略过)
startx++;
starty++;
offset++;
}
if(n%2){
res[mid][mid] = count;
}
return res;
}
};

















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









