







文章目录
RAGFlow简介
RAGFlow是一种基于Retrieval-Augmented Generation(RAG)技术的开源引擎,旨在通过融合数据检索和生成式模型,提升大型语言模型(LLM)的回答准确性和效率。RAGFlow的核心思想是将大规模检索系统与先进的生成式模型相结合,从而在回答查询时既能利用海量数据的知识库,又能生成符合上下文语义的自然语言回复。
RAGFlow下载
RAGFlow github开源网址:https://github.com/infiniflow/ragflow
git clone https://github.com/infiniflow/ragflow.git
也可通过github下载压缩包
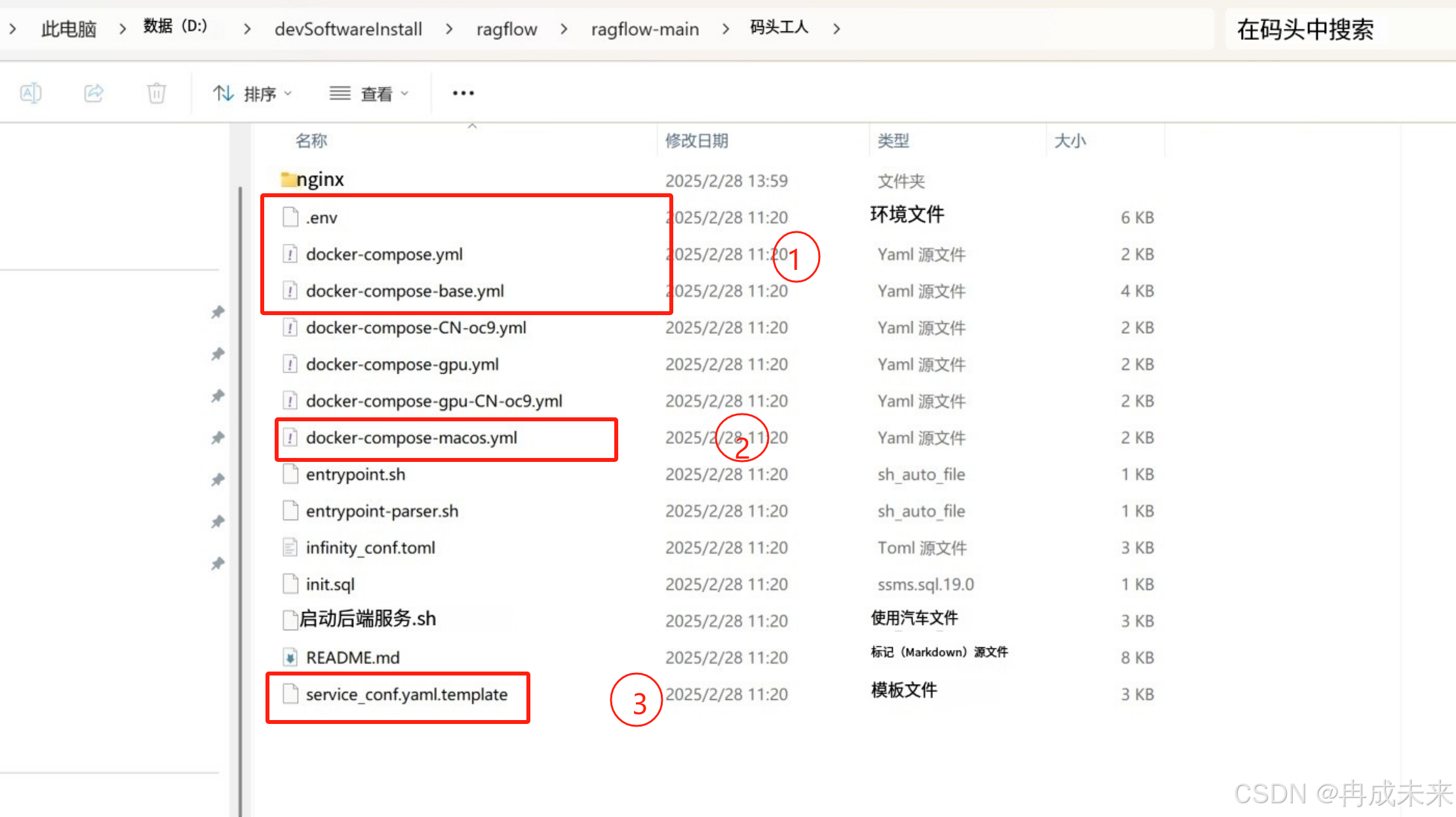
我们看下docker目录中的文件,主要关注圈中的3块
- .env 主要是docker部署的时候一些变量
- service_conf.yaml.template是服务启动使用的配置文件,需要和.env文件里的配置对应,特别是端口•
- 需要注意的是,在mac操作系统下,会引入2
Docker拉取镜像
在 D:\devSoftwareInstall\ragflow\ragflow-main目录下执行命令
docker compose -f docker/docker-compose.yml up -d
如果80端口可以正常使用的话,执行上面的命令也可以启动RAGFlow服务,也可用下面的命令进行启动。

启动RAGFlow
上一步拉取镜像之后,在相同目录下执行
docker logs -f ragflow-server
运行RAGFlow并进行配置
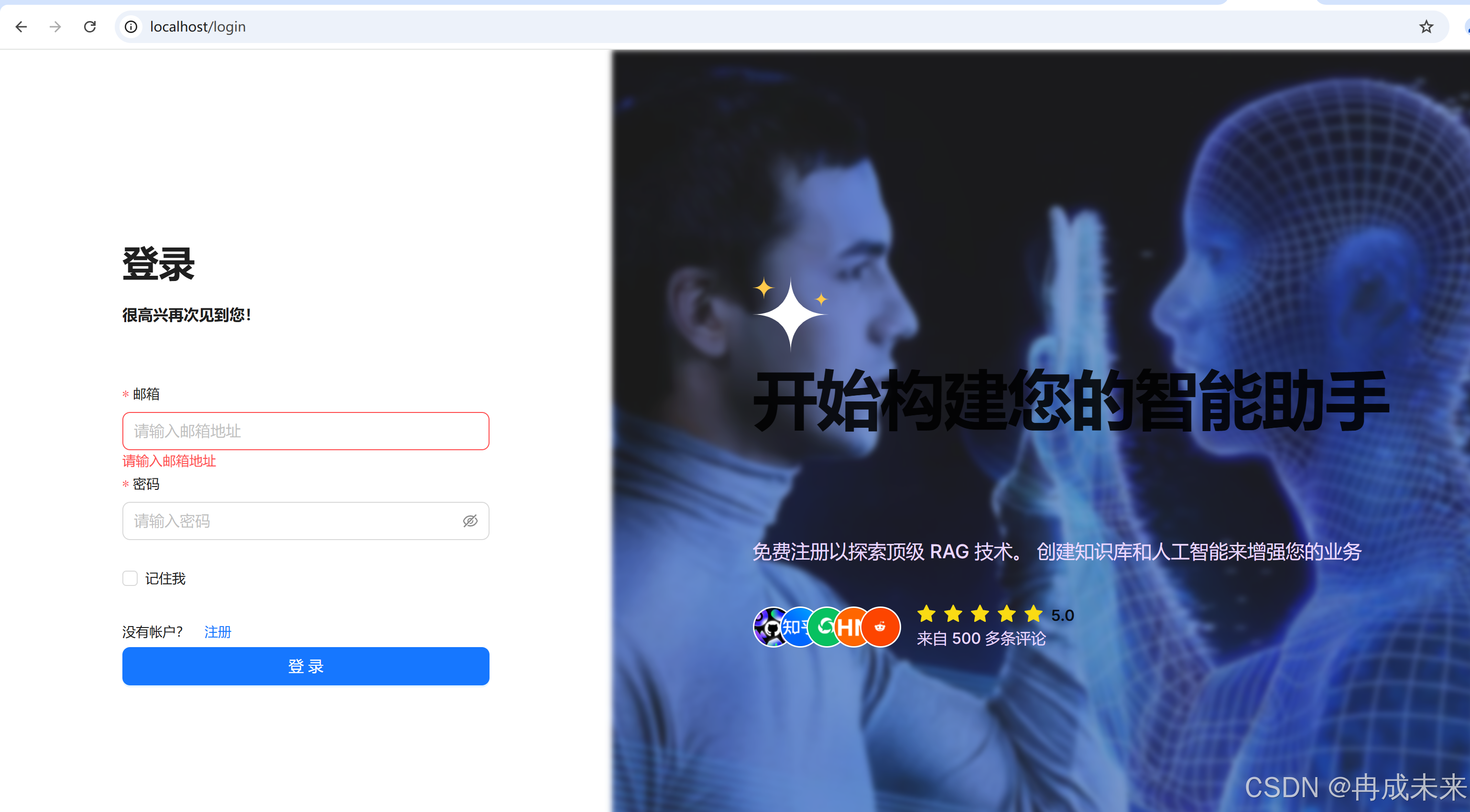
运行成功后的页面如下:
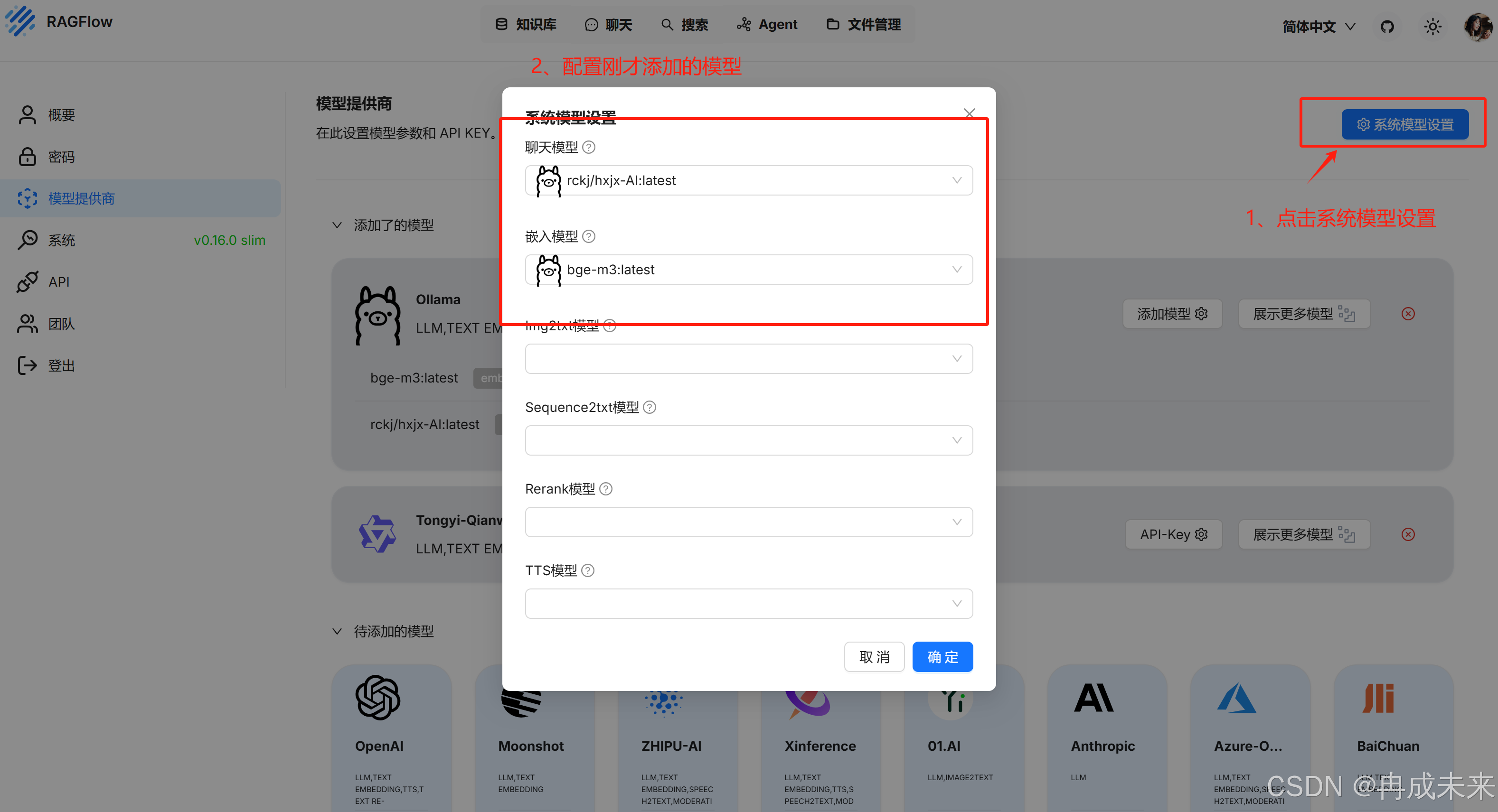
模型配置
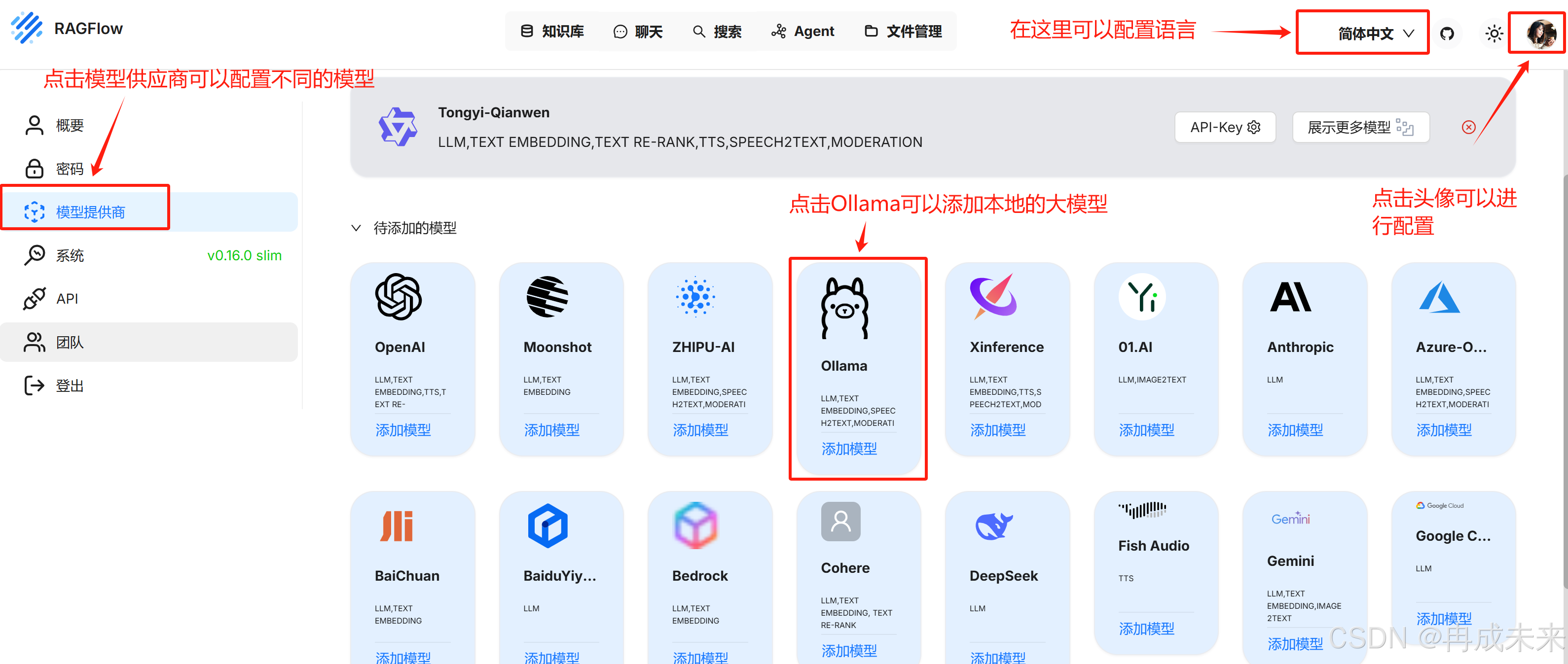
查看配置拉取的模型

将本地模型配置到RAGFlow中
添加chat模型
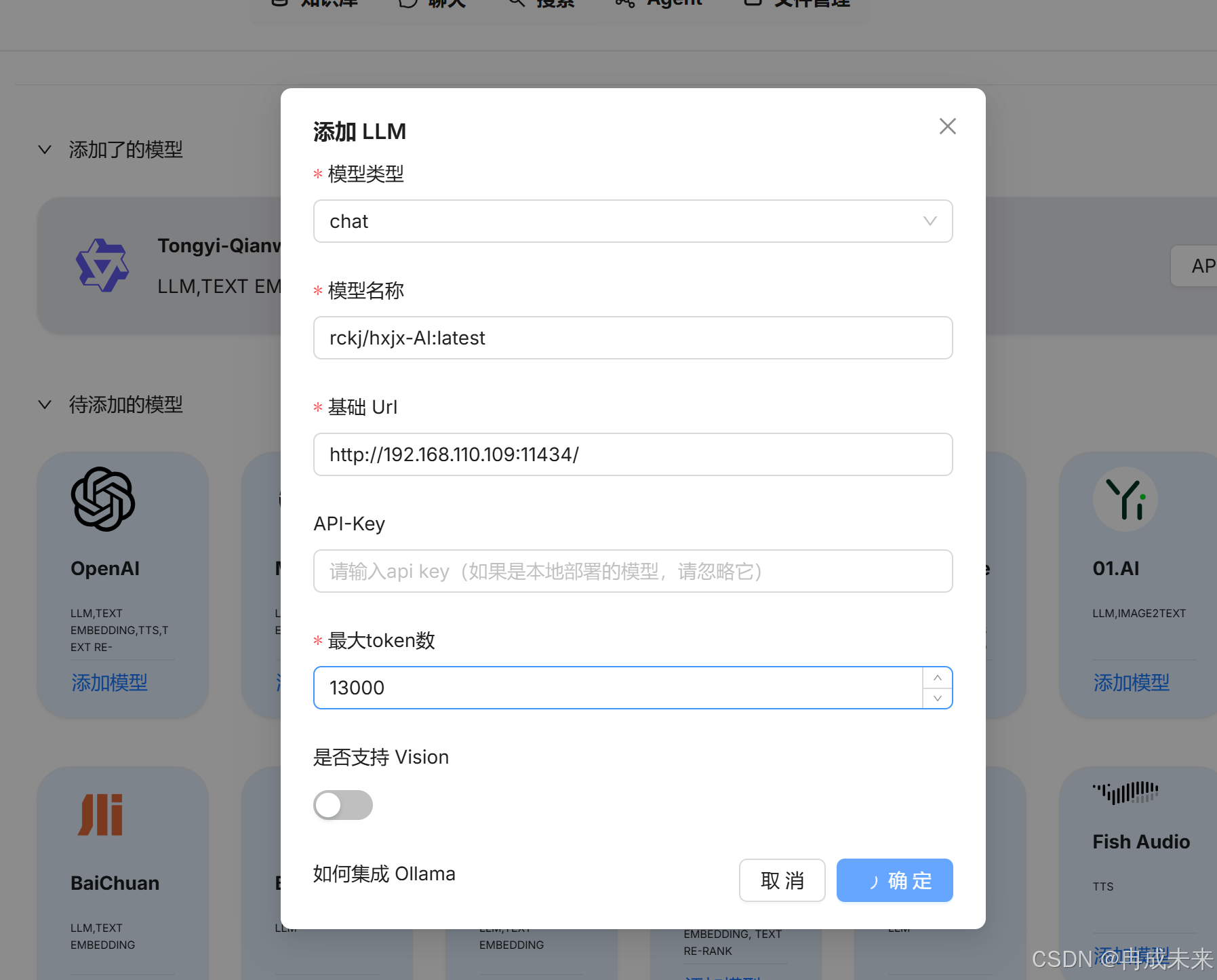
添加embedding模型
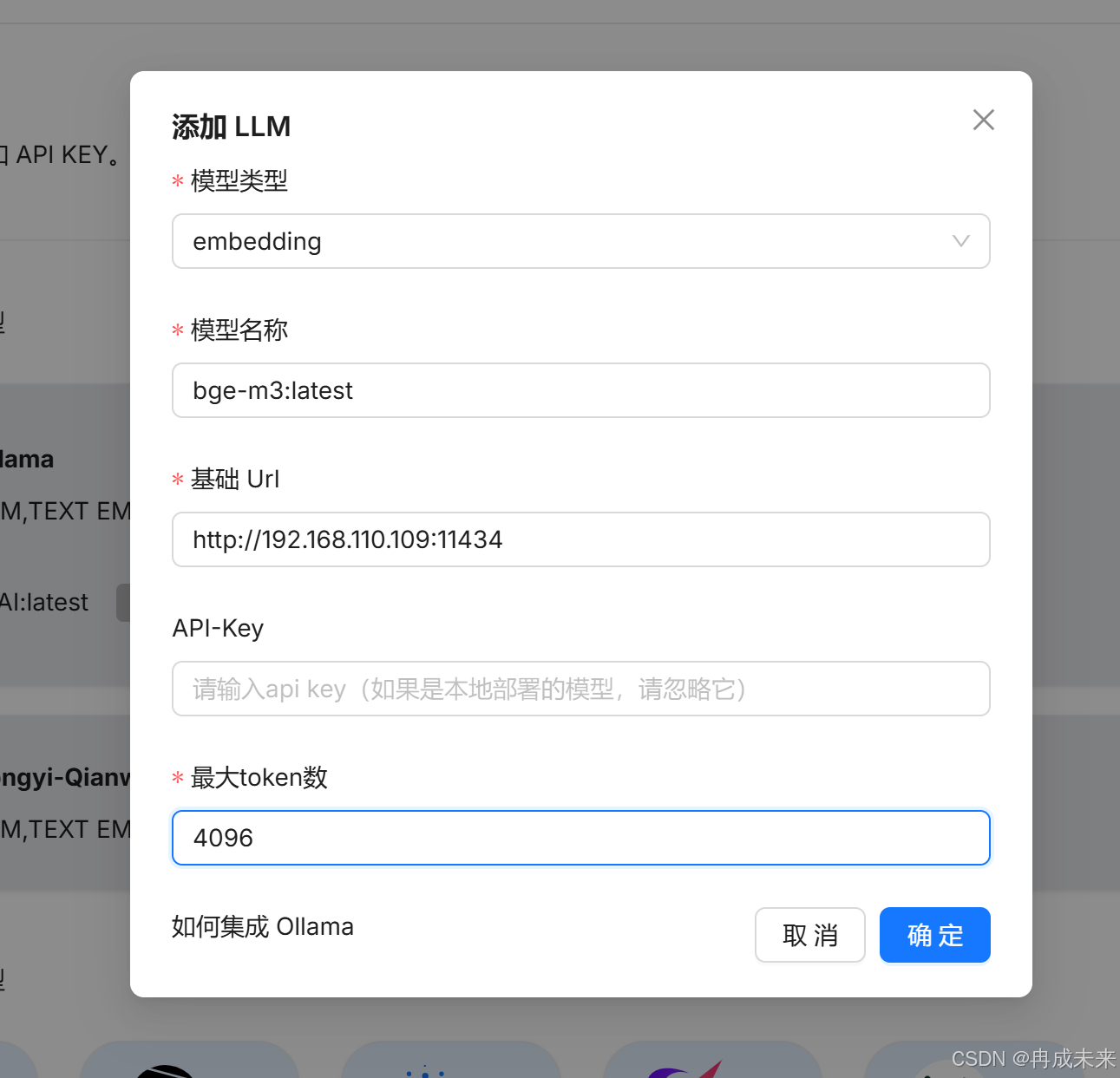
系统模型设置
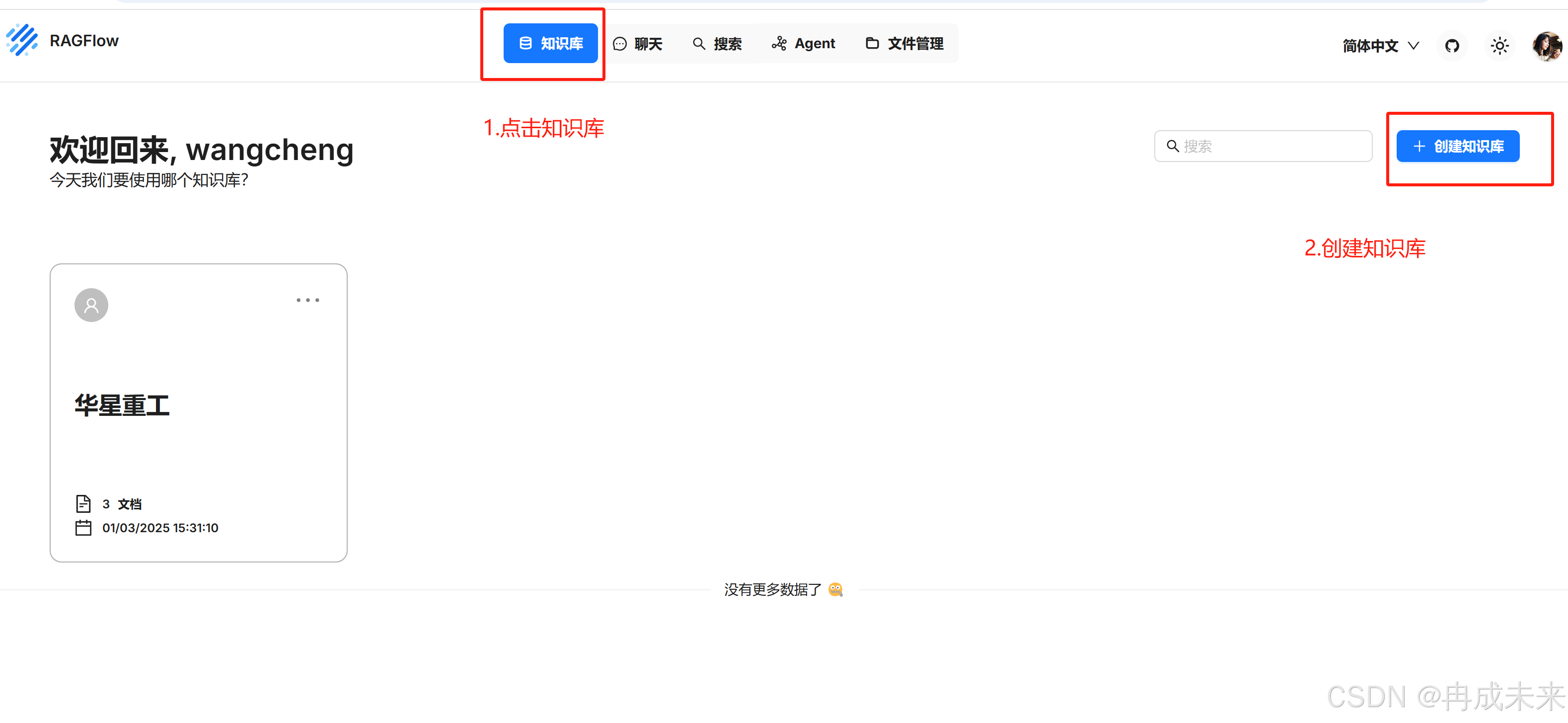
创建知识库
定义好知识库名称后会进入如下页面:
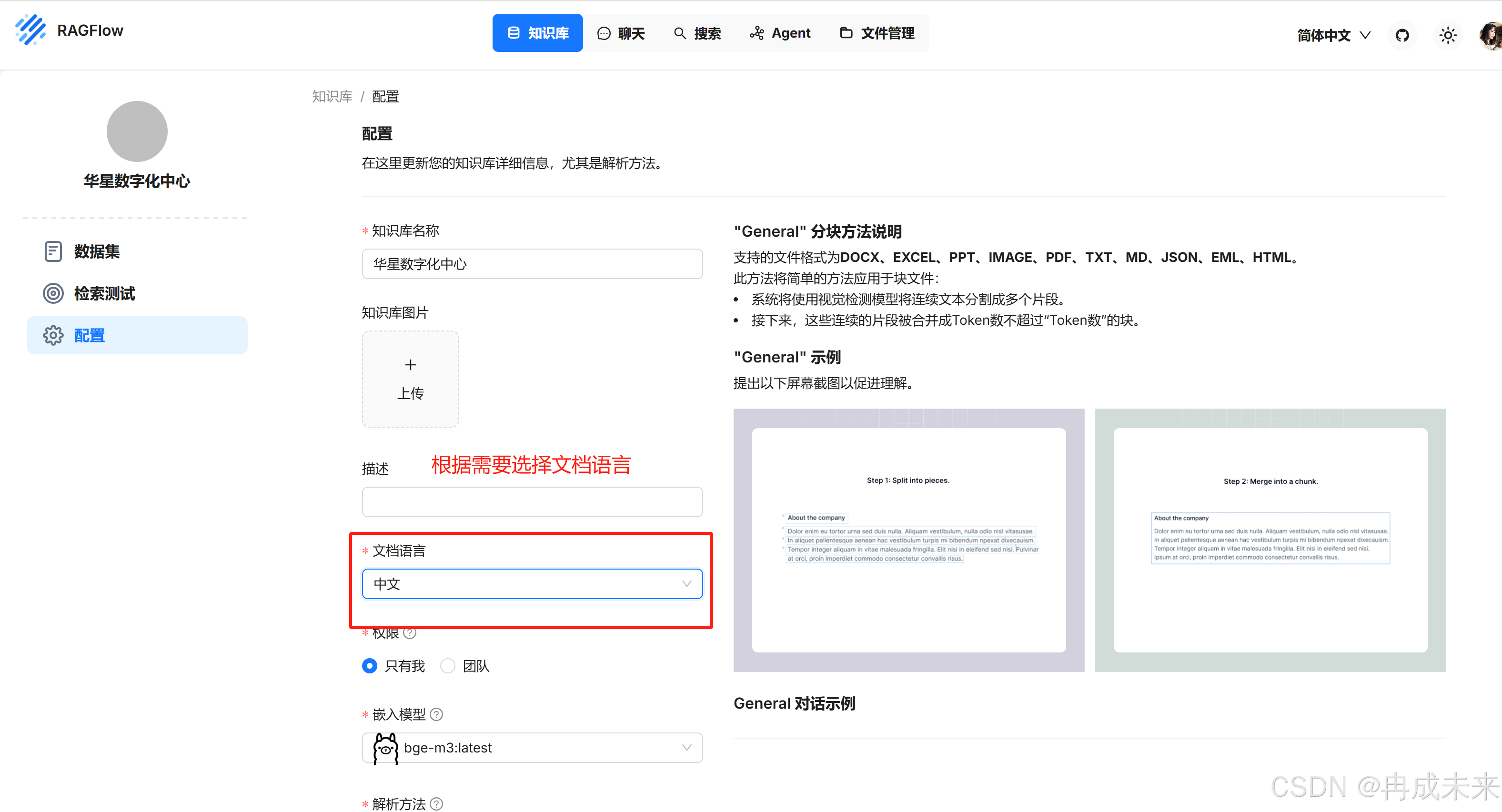
修改好语言,进行保存,便配置好知识库
数据集可以先不关联,后期在文件管理中进行管理
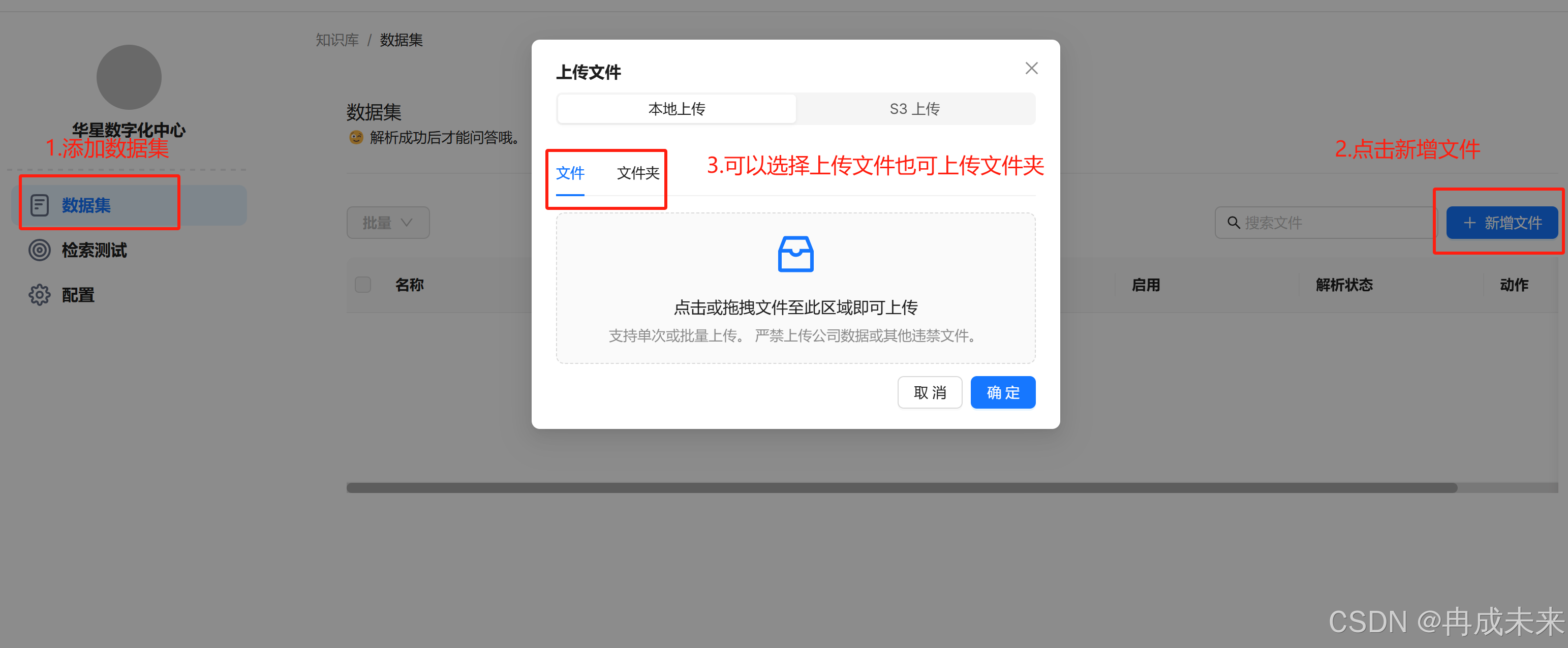
文件管理
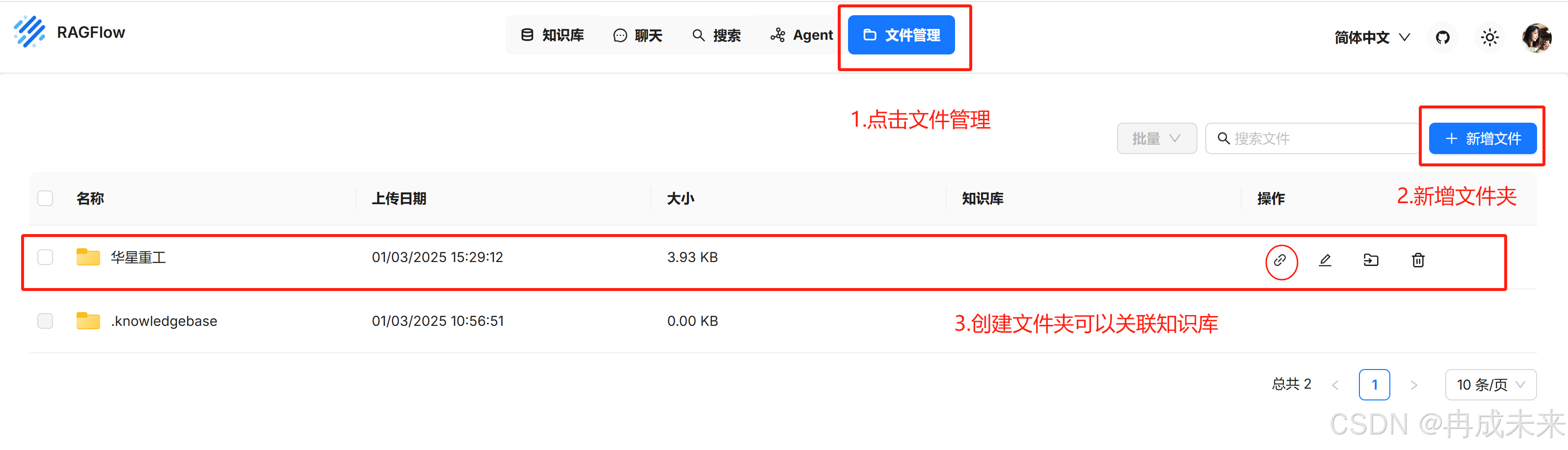
文件夹管理中的新增文件,同数据集里面新增文件类似,但在文件管理中添加层次更加明确。
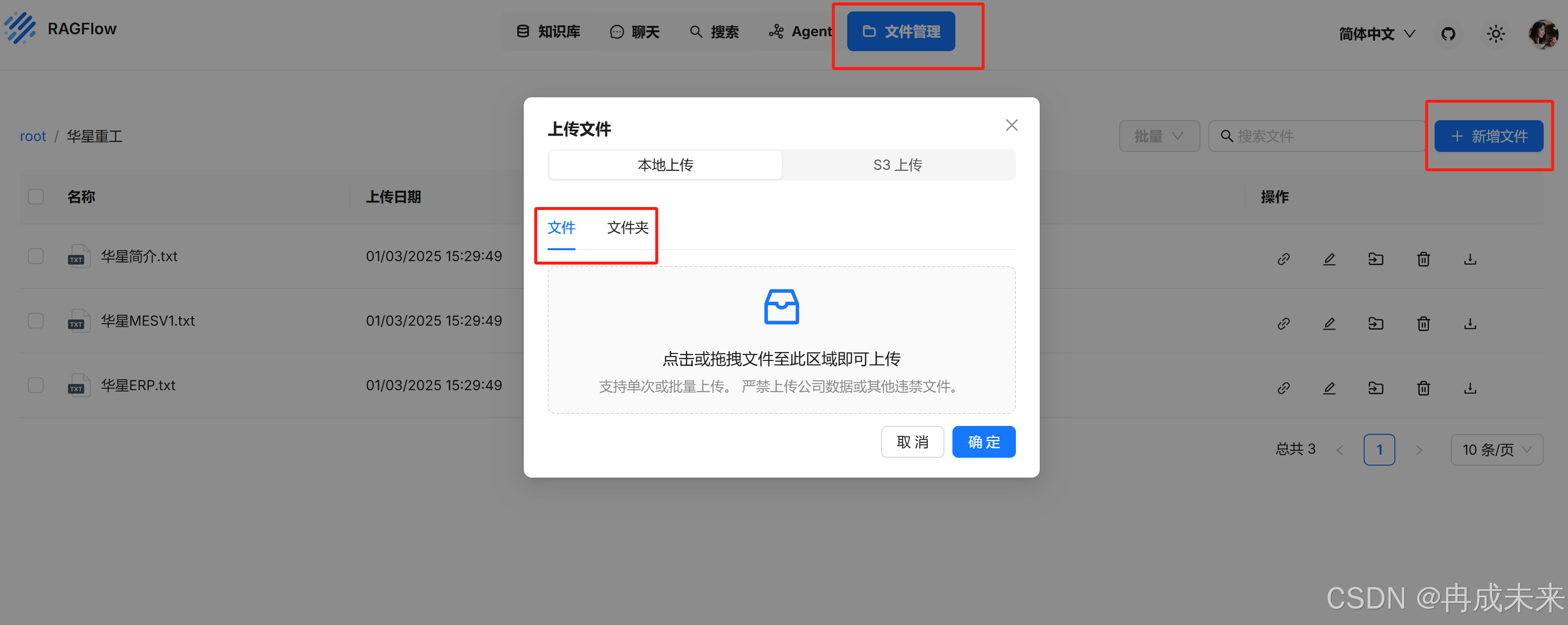
至此我们的知识库便搭建成功了,还有很多功能需要我们进一步的研究。
添加模型报错
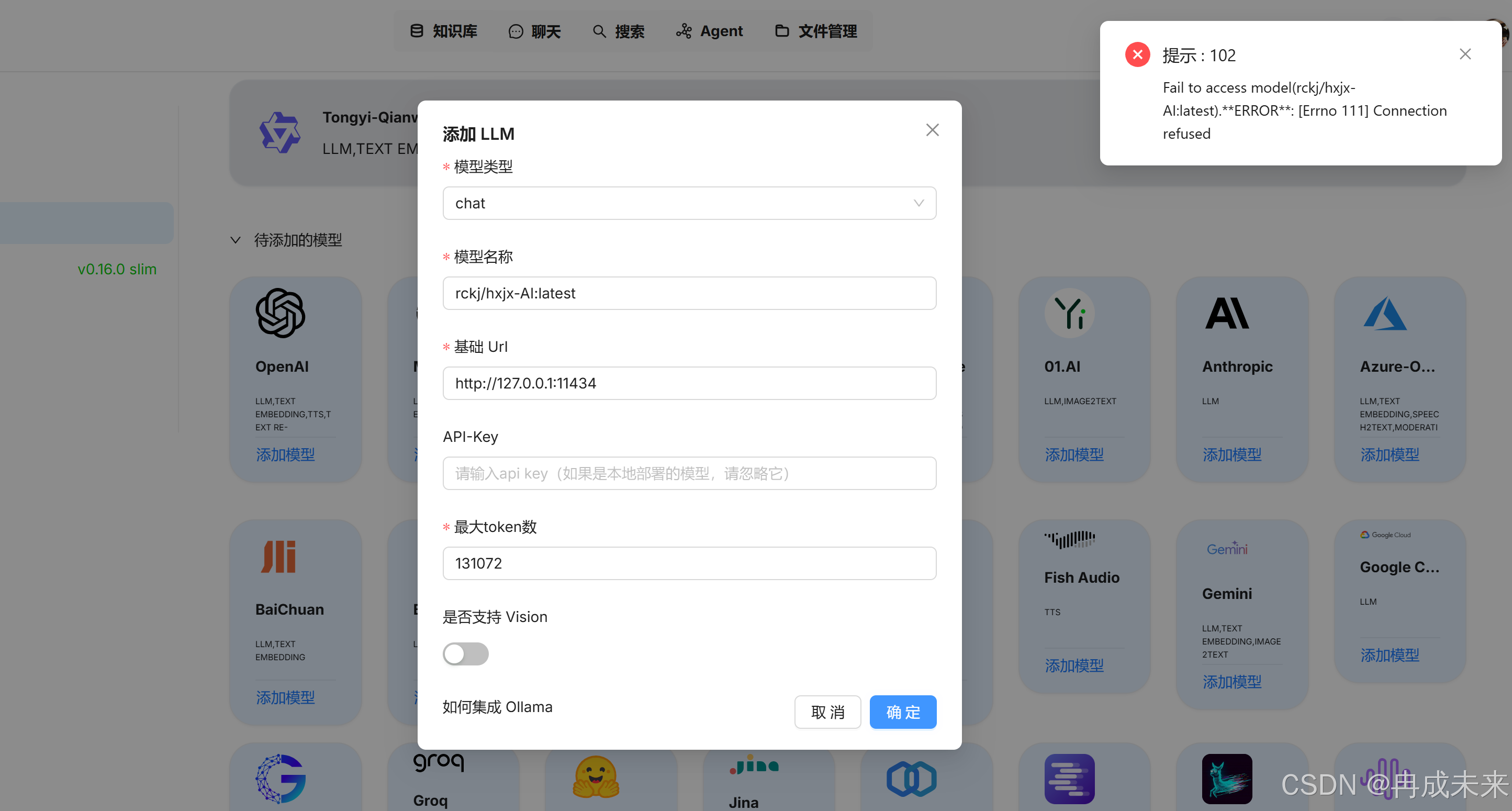
出现这个问题是因为网络端口不通的原因,我们将RAGFlow部署到docker中,docker是运行在window下的容器中,导致端口无法进行访问。需要在系统环境中进行配置。
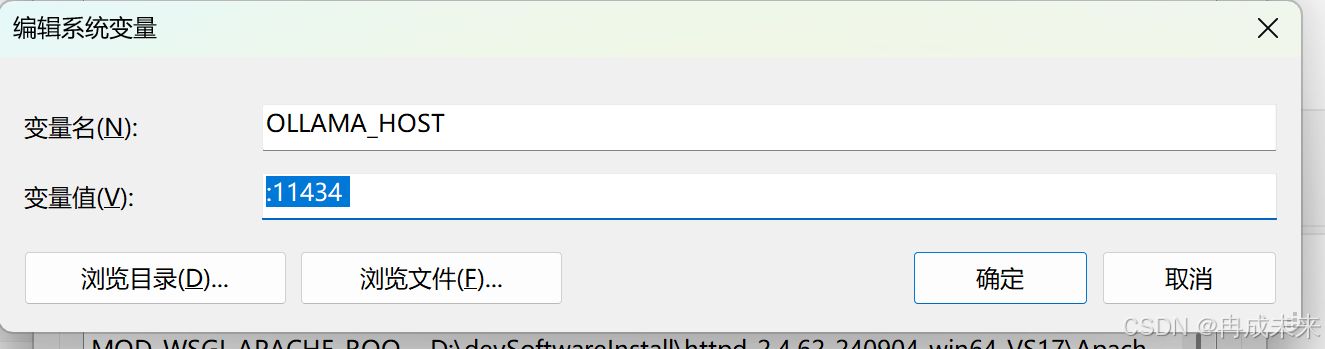
添加上11434这个端口,重新启动系统,再进行添加便可成功。

















 62
62

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









