







 本文详细介绍了YOLOv8网络的关键点检测预测流程,包括预处理、推理和后处理三个模块。预处理涉及图片尺寸调整和归一化;推理阶段,KeyPoint、Box和Cls特征图经过解码;后处理使用NMS筛选关键点,并处理不可见关键点的情况。文章探讨了解码方式的改进可能性以及关键点预测的挑战。
本文详细介绍了YOLOv8网络的关键点检测预测流程,包括预处理、推理和后处理三个模块。预处理涉及图片尺寸调整和归一化;推理阶段,KeyPoint、Box和Cls特征图经过解码;后处理使用NMS筛选关键点,并处理不可见关键点的情况。文章探讨了解码方式的改进可能性以及关键点预测的挑战。
YOLOv8_seg的网络结构图在博客YOLOv8网络结构介绍_优快云博客已经更新了,由网络结构图可以看到相对于目标检测网络,实例分割网络只是在Head层不相同,如下图所示,在每个特征层中增加了KeyPoint分支(浅绿色),通过两个卷积组和一个Conv卷积得到得到通道数为51的特征图,51表示17个人体关键点的XY位置及置信度信息,即51=17*3.
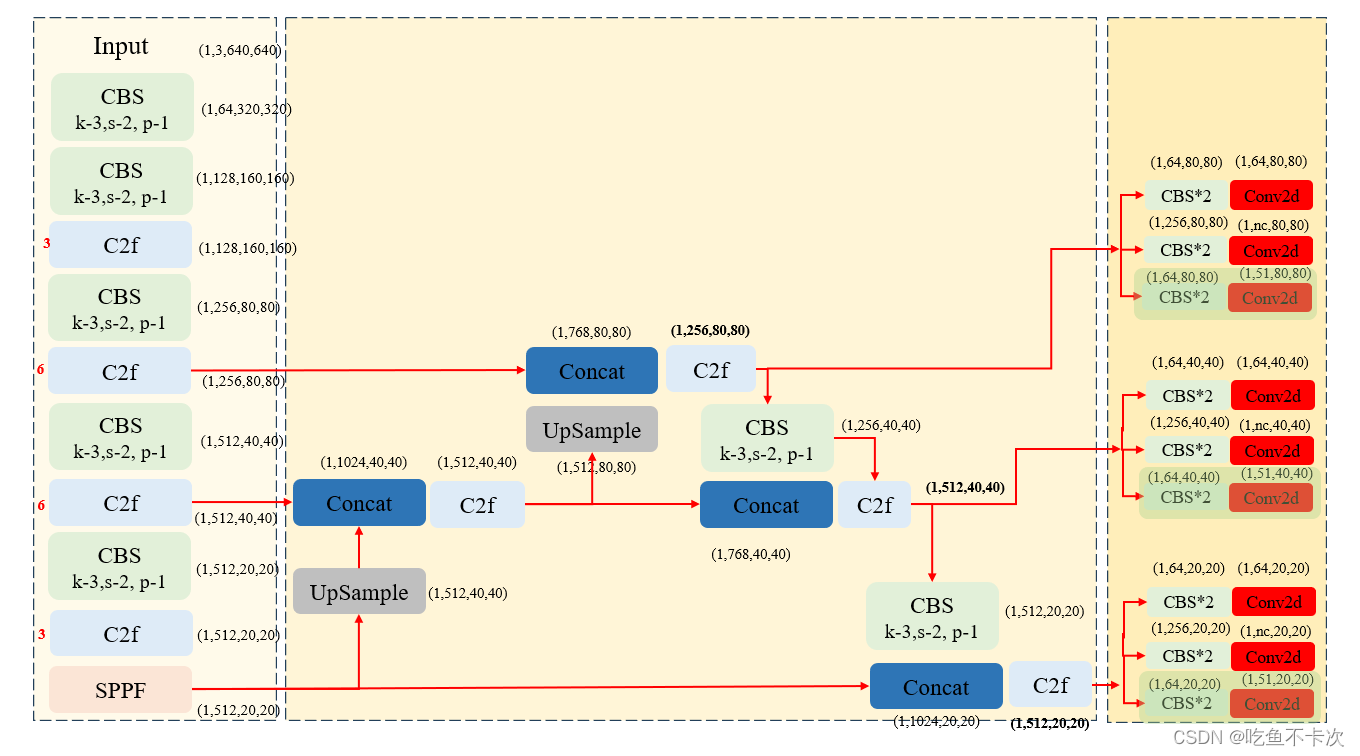
下面正式介绍下YOLOv8的预测流程,先来大概看一下预测流程有哪些,主要分预处理模块、推理模块和后处理模块。这里面有很多内容是和目标检测预测流程是重合的,主要区别在于KeyPoint分支、NMS后处理以及绘制关键点部分。本文也主要介绍一下这三个模块,其他模块可以结合

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2410
2410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











