







这节我们介绍监督学习中的分类算法决策树和KNN。
决策树(Decision Tree)
对于线性回归,ML的目的就是得到一个损失最小的直线;
对于SVM,ML的目的就是得到一个robust的超平面;
而对于决策树,ML的目的就是得到一棵像树一样的决策逻辑去最好地对数据分类。先看看这树长什么样。
这是百度的一个图,我觉得对概念解释得非常好。更生动一点,可以看下面这个图:
怎么一步步求出这棵树呢?我们要引入熵和信息增益这两个概念。
熵可以理解为混乱的程度(越大越混乱),我们肯定希望这棵树是朝着熵越来越小的方向去发展!然后我们引入信息增益去衡量我们每一步的好坏,其含义是当前的熵减去之后的熵,按照之前希望熵越来越小地发展,所以我们的信息增益应该越大越好!
直接进入实战,
这是我做过的一道题,这些数据有三个描述助教的特征(季节,熬夜与否,是否在CS282这门课当助教)和标签(是否晚起),然后选择那个特征作为根节点最好?
先求最原始的熵,
因为有5个数据,2+和3-所以套公式得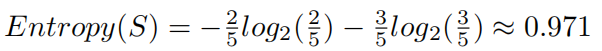
下面算信息增益,先看看公式:
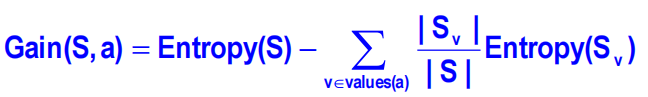
首先计算Gain(S,season),即选择season当根节点的信息增益是多少,它的公式是用Entropy(S)分别减去(分支权重乘以分支的熵),分支权重指的是该分支个数占该特征的比例,如season中summer占其4/5,而winter占其1/5;分支的熵就是再求一次Entropy(summer)和Entropy(winter),套公式呗,
E
n
t
r
o
p
y
(
s
u
m
m
e
r
)
=
−
2
4
log
2
(
2
4
)
−
2
4
log
2
(
2
4
)
=
1
Entropy(summer) = -\frac{2}{4}\log_2(\frac{2}{4})-\frac{2}{4}\log_2(\frac{2}{4}) = 1
Entropy(summer)=−42log2(42)−42log2(42)=1
E
n
t
r
o
p
y
(
w
i
n
t
e
r
)
=
−
1
1
log
2
(
1
1
)
=
0
Entropy(winter) = -\frac{1}{1}\log_2(\frac{1}{1}) = 0
Entropy(winter)=−11log2(11)=0
(求熵技巧,碰见标签五五开分布,直接等于1;碰见标签清一色分布,直接等于0。)
所以我们求出三个特征的信息增益: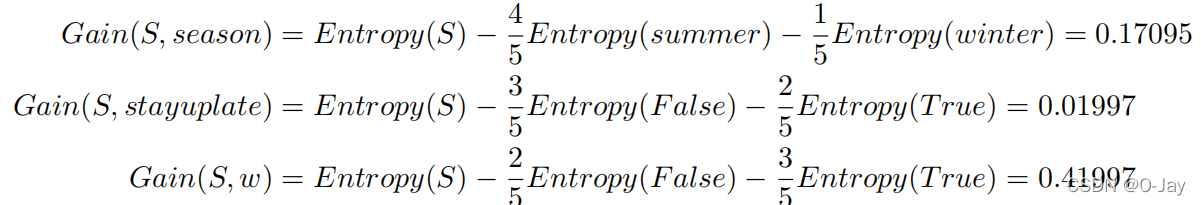
对比得出第三个特征的Gain最大,就选它!然后基于这个根节点再照葫芦画瓢地不断接着算信息增益,找最大的当下一个节点,直至整棵树完成。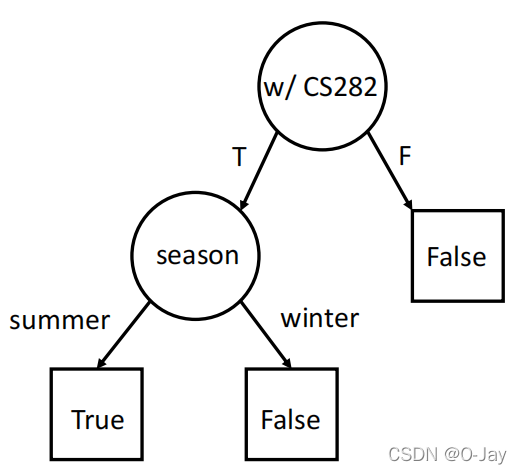
需要说明的是决策树的迭代算法是贪心的算法,它只着眼于当前和下一步,不会做全局考虑,所以会有时候得不到最佳结果,甚至过拟合。
为了防止过拟合,我们可以prepruning和postpruning,即训练前规定树的层数和训练后修剪叶节点。
K近邻(KNN)
这个是最简单的,一句话能讲明白,近朱者赤近墨者黑,或者鱼配鱼虾配虾乌龟配王八。就是看一点它周围的点是这怎样的,我们就判断它是怎样的。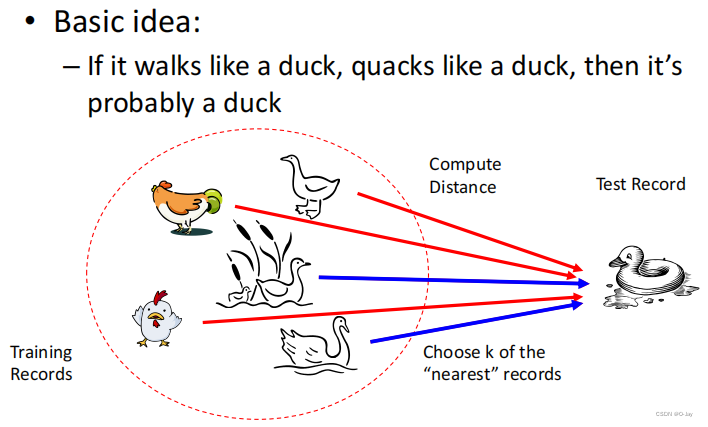 就是在一堆已经知道标签的数据中,放进一个待估计数据,先选一个K值,如K=3,则以该点为中心,算出它跟所有训练数据的距离后,选出最近的3个,ok,然后看这三个中哪类标签的数量多,如2+1-则预测为+,2-1+则预测为-,就是这么粗暴,计算距离一般就用最简单的初中方法求两点距离。
就是在一堆已经知道标签的数据中,放进一个待估计数据,先选一个K值,如K=3,则以该点为中心,算出它跟所有训练数据的距离后,选出最近的3个,ok,然后看这三个中哪类标签的数量多,如2+1-则预测为+,2-1+则预测为-,就是这么粗暴,计算距离一般就用最简单的初中方法求两点距离。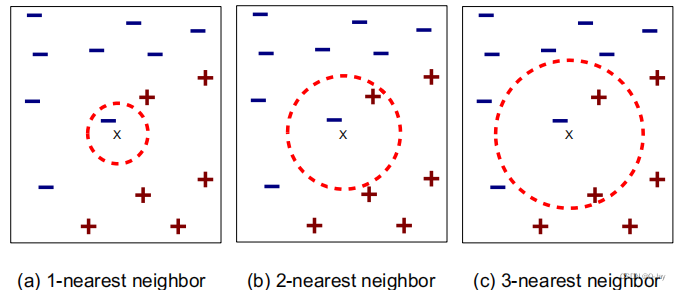
一般不会选择k为偶数(1+1-很难判断,需要加入其它参数来协同判断,如最近的是什么标签),k为奇数就可以简单地得到可靠结果。
附上其他笔记的链接:
《无废话的机器学习笔记(一)》
《无废话的机器学习笔记(二)(线性回归)》
《无废话的机器学习笔记(三)(梯度下降)》
《无废话的机器学习笔记(四)(感知机、逻辑回归、贝叶斯)》
《无废话的机器学习笔记(五)(SVM)》
《无废话的机器学习笔记(七)(聚类: kmeans、GMM、谱聚类)》
《无废话的机器学习笔记(番外)(数据集,方差-偏差,过拟合,正则化,降维)》


















 2584
2584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











