







 本文深入探讨了机器学习中的KNN算法和决策树。KNN算法详述了其优缺点、原理及应用实例,强调了计算距离和选择最近邻居的重要性。决策树部分讨论了其优缺点、生成原理,包括信息增益、增益率和基尼指数等划分标准,并提及了剪枝处理以防止过拟合。文章通过实例解释了如何运用这两种算法进行预测。
本文深入探讨了机器学习中的KNN算法和决策树。KNN算法详述了其优缺点、原理及应用实例,强调了计算距离和选择最近邻居的重要性。决策树部分讨论了其优缺点、生成原理,包括信息增益、增益率和基尼指数等划分标准,并提及了剪枝处理以防止过拟合。文章通过实例解释了如何运用这两种算法进行预测。
1 K-临近算法(KNN算法)
(一)优缺点和适用范围
(1)优点:精度高、对异常值不敏感、无数据输入假定
(2)缺点:计算复杂度高、空间复杂度高
(3)适用数据范围:数值型和标称型
(二)原理和算法思想
原理:训练样本集中每个数据都存在标签,输入没有标签的新数据以后,将新数据的每个特征与样本集数据对应的特征进行比较,算法提取样本集最相似数据的分类标签。一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K-临近算法中K的出处。
算法思想:
(1) 计算已知类别数据集中的点与当前点之间的距离,这里采用的是欧氏距离公式: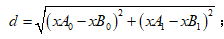 ;
;
(2) 按照距离递增次序排序;
(3) 选取与当前距离最小的K个点;
(4) 确定前K个点所在类别的出现频率;
(5) 返回前K个点出现频率最高的类别最为当前点的预测分类。
(三)KNN算法实例
实例一:使用KNN算法改进约会网站的配对效果
(1)收集数据:提供文本数据;
(2)准备数据:使用python解析文本文件;
(3)分析数据:使用matplotlib画二维扩展图;
(4)训练算法:使用KNN分类器;
(5)测试算法:使用测试样本计算分类的错误率;
(6)使用算法:根据输入数据预测喜欢程度。
Matplotlib分析的结果如图2-1所示:
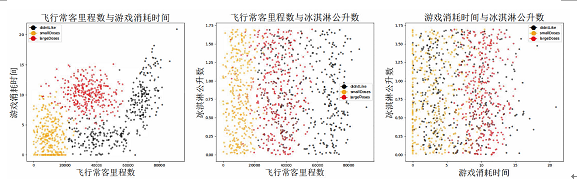
Figure1:我们使用三种颜色代表喜爱程度:红色代表非常喜欢、黄色代表有一点喜欢、黑色代表不喜欢,这里分别作出了飞行常客里程数与游戏消耗时间、飞行常客里程数与冰淇淋公升数、游戏消耗时间与冰淇淋公升数三幅散点图,用来观察对喜爱程度的主要影响因素。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















03-01
 962
962
962
01-16
1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









