







- 问题引入
- 针对的是文生图里面的personalization的问题,将user specific的subject加入到生成当中;
- 基于fintuning的personalization的解决方案存在削弱原始文生图模型能力的问题,本文将原始文生图模型定义为prior model;
- 本文更加类似于ip-adapter和instant id,在有新的subject的时候不需要额外的optimization,而是通过使原始T2I模型可以接受图片输入,但是不同点在于本文的方法将subject和text绑定,以更好的应对多subject的生成,要是没有这种绑定机制,就需要额外的mask来实现多subject的生成;
- 总结来看,本文想要实现的目标是1)prior perserving; 2)fast generation(对于新的subject不需要额外的optimization)3)layout free:不需要额外的mask机制来保证多subject生成;
- methods
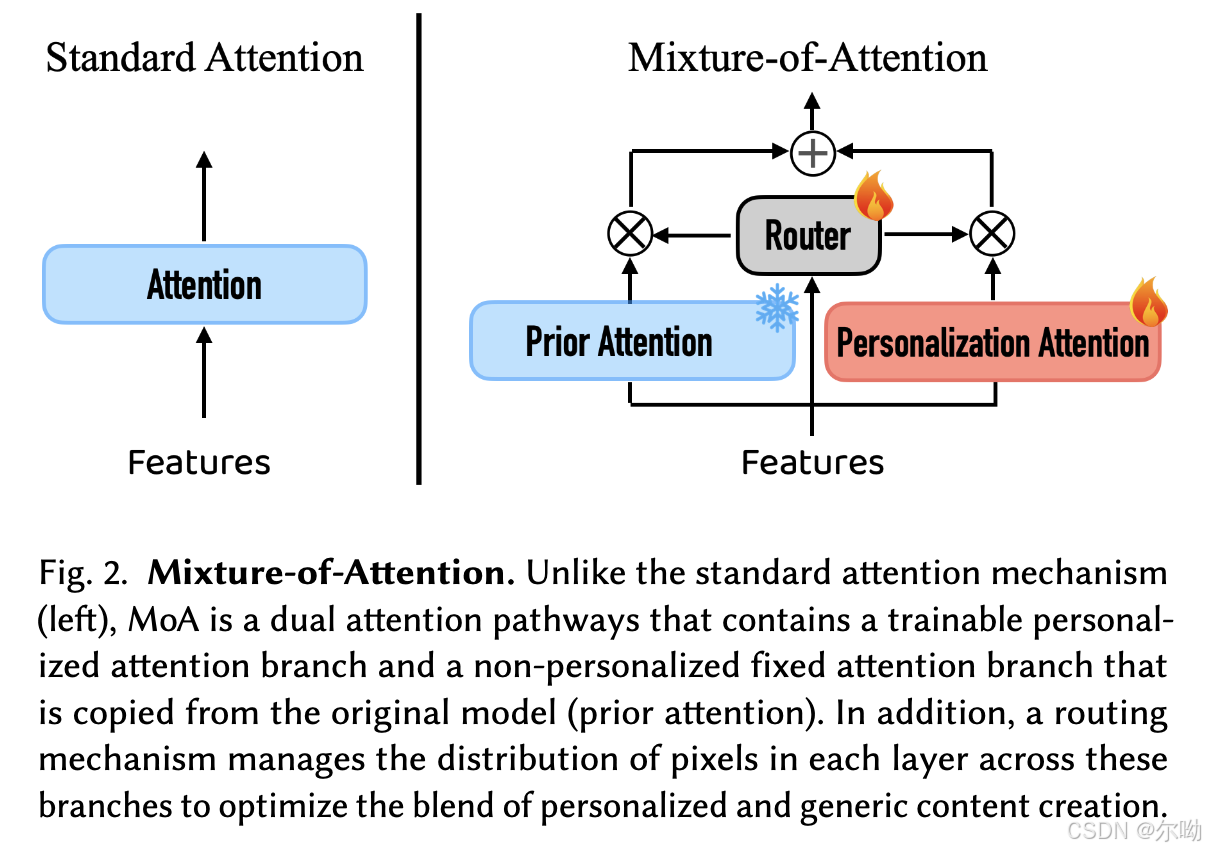
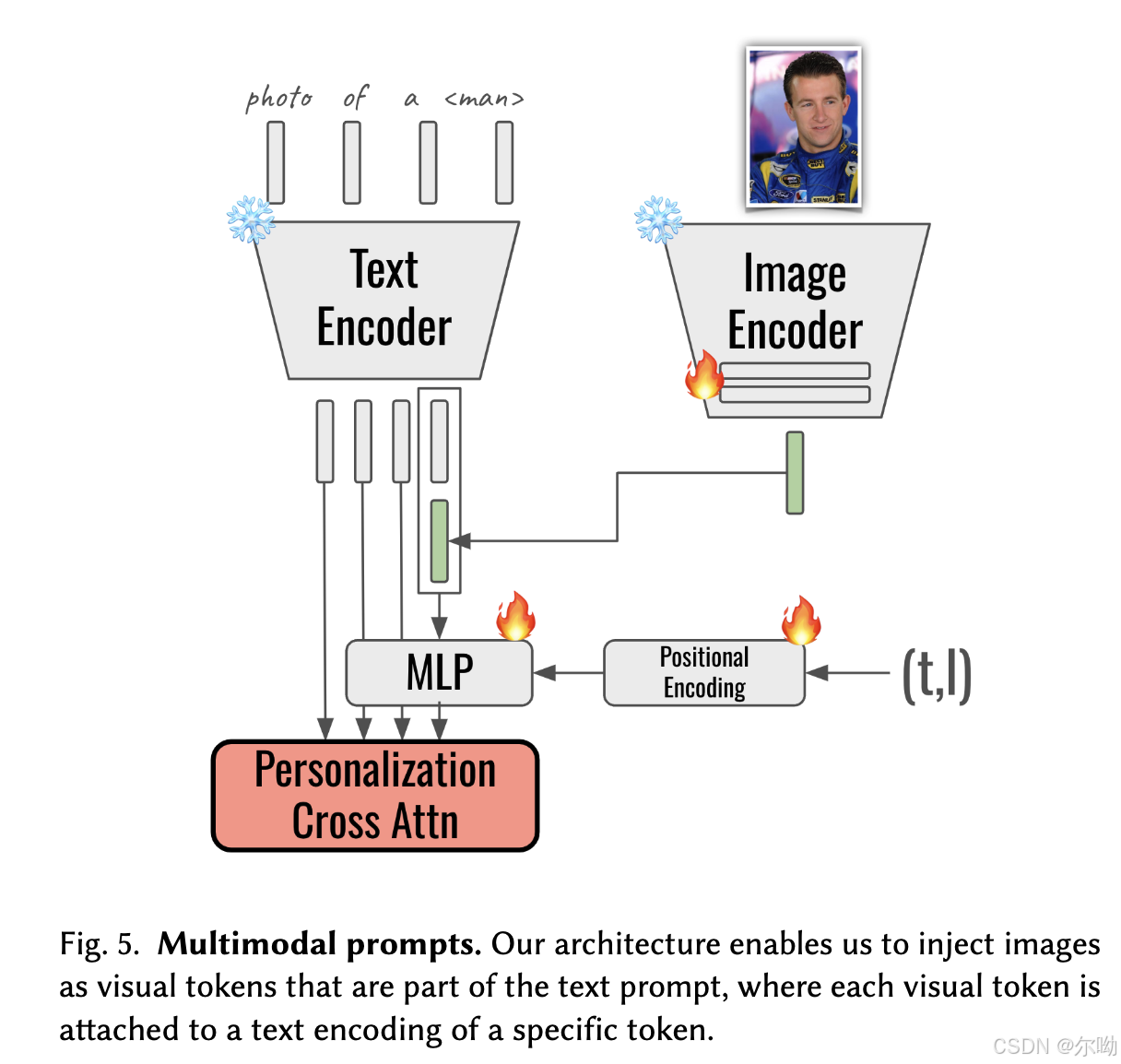
- 在self attn和cross attn中都会使用MOE架构,使用pretrained model进行初始化,其中只有新添加的模块是在训练的,MOE架构包含N个expert网络以及一个router,对于MOA来说,self attn中的prior network和personalization network的输入是一样的;而cross attn部分中,prior的输入条件还是单纯的text embedding,而personalization部分会加入图片的embedding得到multimodal embedding,方式是先使用CLIP image encoder获取到image 的embedding,之后和对应的text的embedding进行concat,例如subject是man就和man的embedding进行concat,之后这个embedding还加入了diffusion timestep和unet layer为条件,具体图示如下:
- Training the Router:对于背景位置,router尽可能的使之使用prior的结果,所以损失函数是 L r o u t e r = ∣ ∣ ( 1 − M ) ⊙ ( 1 − R ) ∣ ∣ 2 2 , R = 1 ∣ L ∣ ∑ l ∈ L R 0 l L_{router}=||(1 - M)\odot (1-R)||_2^2,R = \frac{1}{|\mathbb{L}|}\sum_{l\in\mathbb{L}}R_0^l Lrouter=∣∣(1−M)⊙(1−R)∣∣22,R=∣L∣1∑l∈LR0l,R是router的权重,M是前景的mask;
- 最终使用的损失是masked diffusion loss和router loss以及fastcomposer方法中提出的object loss的加权和,其中masked diffusion loss是指只计算前景的diffusion原始损失,object loss是对attn map计算segmentation的损失,和storymaker里面的那个类似;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









