






Statement:声明
This views andopinions expressed in this account are those of my own and do not represent those of my employer.本文所有观点仅代表个人,不代表雇主.
The information covered in this article is public information on the Internet and does not contain any commercial or technical secrets. I will give reference links after the article.本文涉及的信息均是互联网上的公开信息,不包含任何商业或技术机密。我将在文章后给出参考链接.

2023年8月的SIGGRAGH大会上,老黄又发布了一系列AI软硬件产品更新,其中有两个硬件更新值得注意,一个是最新发布的基于Ada Lovelace架构的L40S GPU产品,另外一个就是DGX GH200 AI超级计算机的参数更新了。本文基于早前6月份发布的该产品白皮书来简要介绍一下它的一些特点:
https://resources.nvidia.com/en-us-dgx-gh200/technical-white-paper
参数的更新
早在今年5月的Computex大会上,老黄已经发布了DGX GH200 AI超级计算机产品,当时GPU是96GB HBM3,并且将于今年年底正式供货,但是SIGGRAPH上的DGX GH200又有了一些参数的更新:
1. 每块Hopper GPU的内存从4TB/s带宽的96GB HBM3内存升级成4.9TB/s带宽的144GB HBM3e内存 , 估计是考虑到谷歌TPU v5和AMD MI300同样将采用HBM3e高速内存;
2. GPU的高速访问内存从576GB(CPU 480GB+GPU 96GB)升级为624GB(CPU 480GB + GPU 144GB);
更新后的144GB HBM3e版本将于明年供货,前面提到的白皮书里还是基于5月GH200的产品参数,但是整体内部架构细节没有改变。
概要
DGX GH200 AI超级计算机主要由几部分组成,分别是GH200 Grace Hopper Superchip芯片,NVLink-C2C互联技术,NVLink L1和L2交换机系统和NDR Quantum-2 Infiniband网络,带内和带外以太网络组成,软件上主要包括NVIDIA Base Command和NVIDIA AI Enterprise。Grace Hooper Superchip是通过NVLink-C2C技术将GPU和CPU组成一个AI加速异构平台,GH200通过将256片 Grace Hopper Superchip有效的组合在一起,可以对外提供具有1 ExaFLOP FP8稀疏算力,具有144TB GPU的统一内存池,整体可提供115.2TB/s 的NVLink带宽。总之整个GH200对外相当于一台完整的DGX服务器,并且提供一个巨大的内存池,最大程度上消除大模型训练中多机多卡互联带来的数据内存访问和网络通讯带来的消耗。 整个GH200具有2层NVLink网络,第一层是由8个Grace Hopper Superchip和3个L1 NVLink switch组成的机框架构,单台提供3.6TB/s带宽,32台机框对外一共提供115.2TB/s带宽,第二层是由36个L2 NVlink switch将32台机框架构互联,组成2层的胖树1:1无阻塞CLOS拓扑,最终形成一个具有完整的256个GPU的超级计算系统。可以看看下面内部逻辑图:
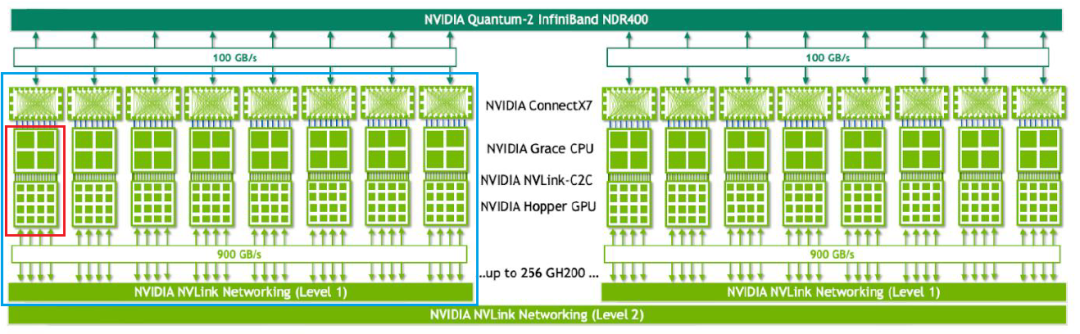
上图红色区域是一块Grace Hopper Superchip, 蓝色区域就是由8块Superchip和3个NVLink switch组成的机框,32个机框通过下面两层胖树拓扑的NVlink组成一个无阻塞的具有144TB内存的DGX超级计算机,上面则通过NDR400的Infiniband网络连接存储或者其它GH200的超级计算机。下图是通过IB将两个DGX GH200 AI超级计算机,共512个Grace Hopper Superchip连接到一起。
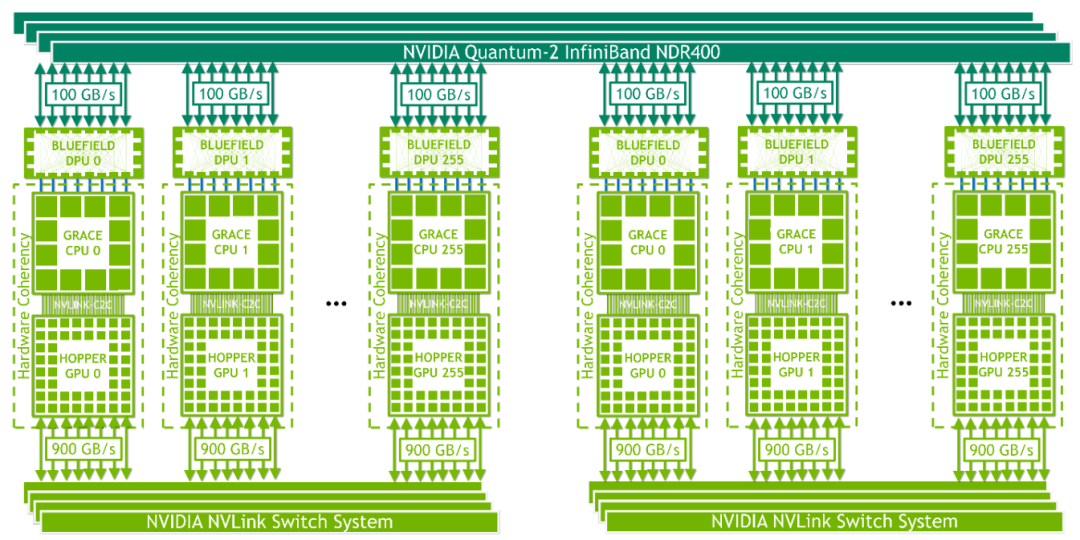
如下图,同时英伟达还推出MGX GH200的架构,可以跟OEM和ODM厂家合作,只采用Infiniband NDR400来搭建基于Grace Hopper的超大规模RDMA超算集群。
Grace Hopper Superchip
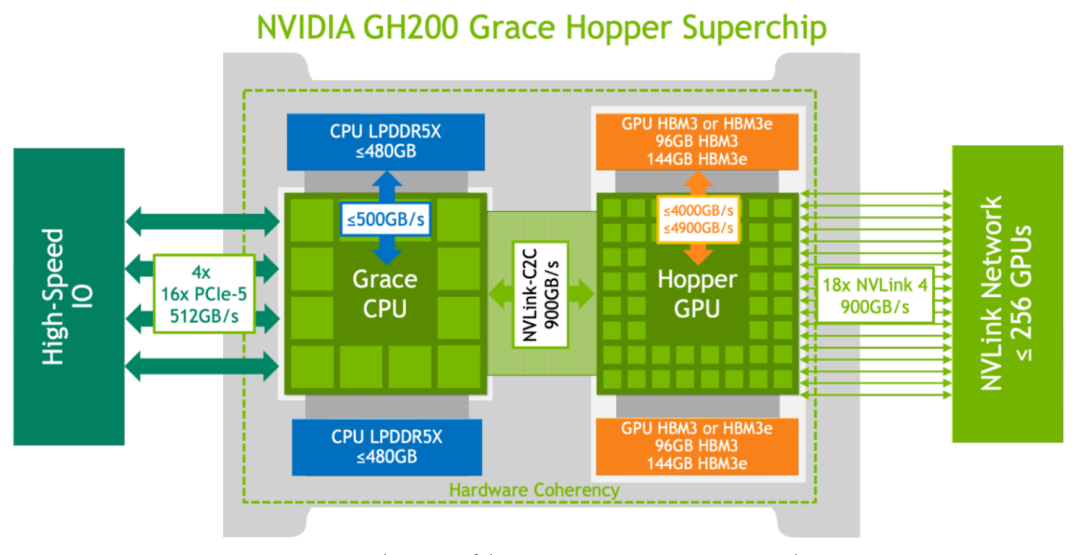
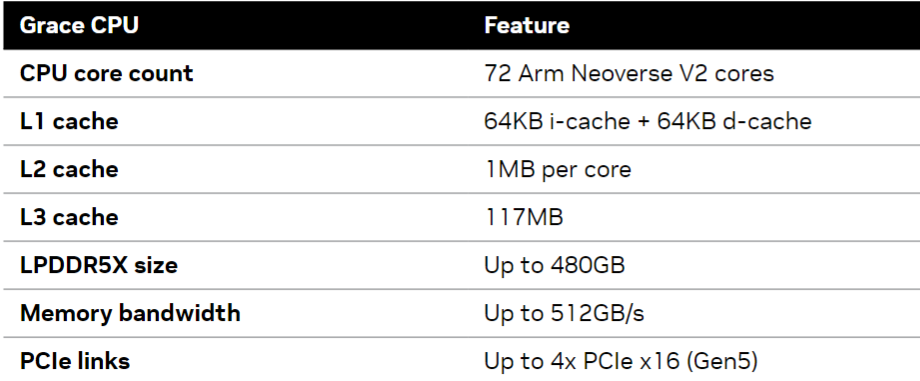
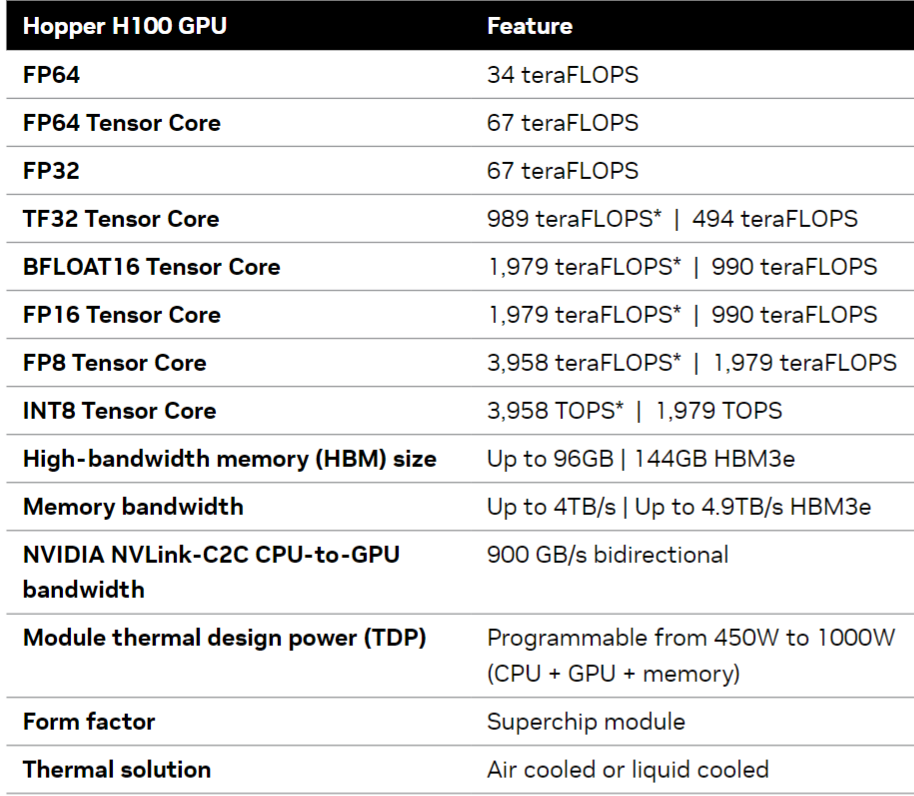
Grace Hopper Superchip是英伟达针对HPC和AI场景的首款异构加速平台。上面是CPU和GPU的基本参数,基于Hopper架构的GPU具有4.9TB/s带宽的144GB HBM3e内存,72核 Grace Arm Neoverse v2 CPU具有512GB/s带宽的480GB LPDDR5X内存。通过NVLink-C2C技术可以将GPU内存和CPU内存高带宽和低延迟的连接到一起,提供900GB/s的双向带宽,全双工带宽就是450GB/s,是普通PCIE5.0*16带宽的7倍(32*16/8*7=448GB/s),结合Extended GPU Memory (EGM)技术和Magnum IO GPUDirect加速软件栈可以让本地GPU访问本地CPU和远端CPU,GPU都能达到450GB/s的全双工高速带宽,做到全网统一的144TB内存。
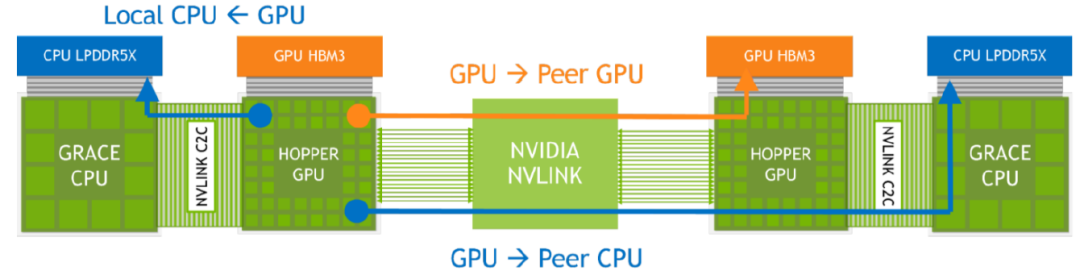
这种总的高速内存的增大可以带来batch size的增大,在最新发布的MLPerf3.1 Inference测试结果可以看到,单颗Superchip要比x86架构下H100SXM卡的推理性能有很大提升,尤其是BERT和DLRMv2参数。
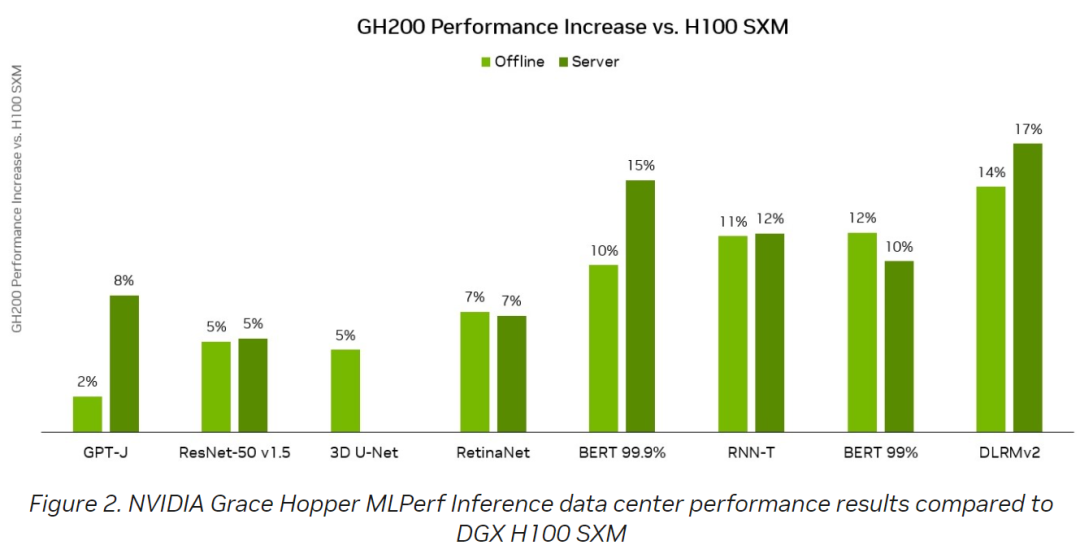
每个Superchip还具有4个PCIE5.0*16的IO高速接口(512GB/s双向带宽)连接外部,同时通过18根第四代NVlink连接,通过第一层的3个NVLink switch系统来连接其它7个Grace Hopper Superchip。
NVLink Switch交换机
第3代NVSwitch ASIC结构图
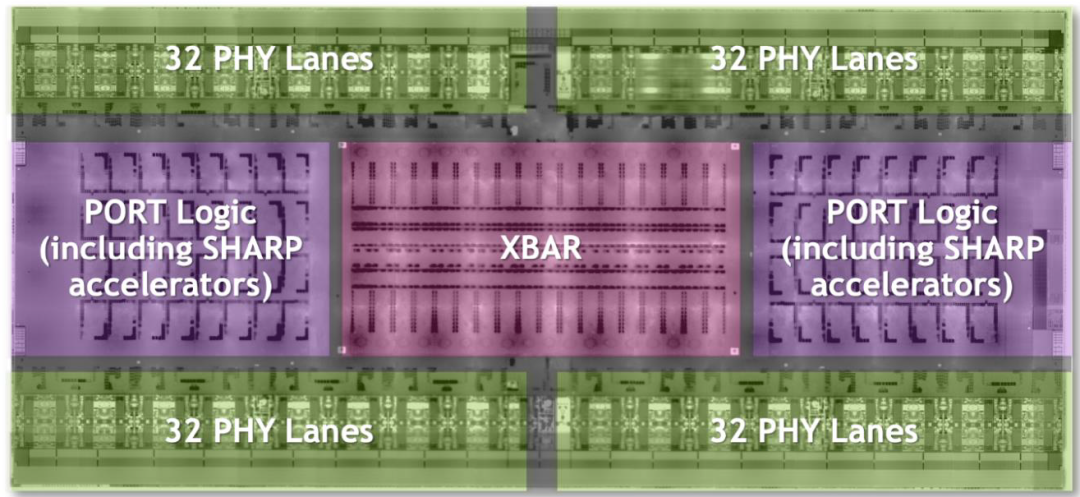
每个L1或者L2 NVLink Switch都是内置2颗第三代NVSwitch ASIC芯片(如上图所示),2个ASIC总共可对外提供128个第四代NVlink接口,每个接口是2个PHY Lanes共26.6GB/s(大概200Gb/s)全双工带宽,那么128个NVlink4接口可提供128*200=25.6Tb/s的全双工带宽。同时可以看到ASIC内部还有SHARP的加速单元,除了外部IB的SHARP,在NVLink内部也实现了SHARP对All Reduce的硬件加速计算。
Grace Hopper 计算机框
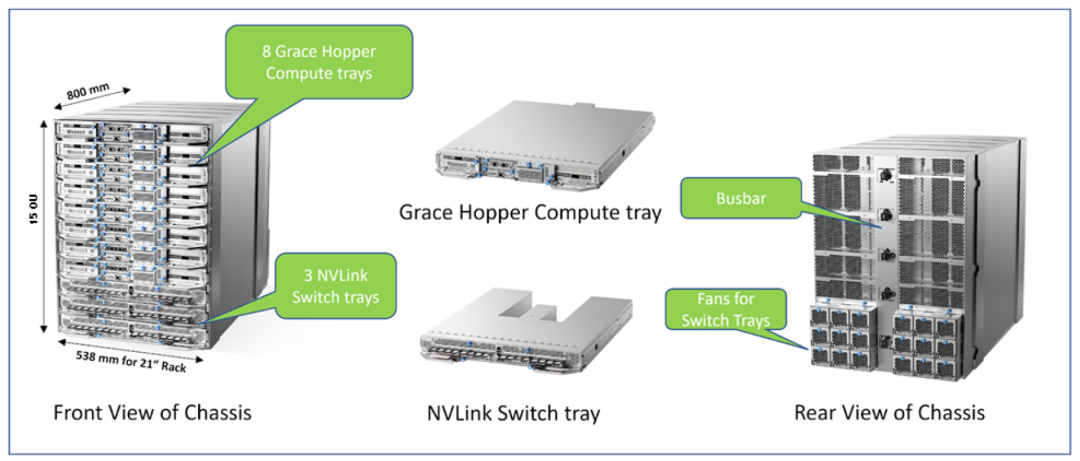


如上图所示,这种机框由8个Grace Hopper Superchip板卡和3个NVLink Switch板卡组成,每一个NVlink Switch由2颗第3代NVLink switch ASIC组成。同时每一个Grace Hopper Superchip板卡还自带一块1*400G OSFP的CX7 NDR IB网卡和一块2*200G QSFP112的CX7或者BF3网卡,前者可以用来扩展连接其它GH200超级计算机,做出超出256块GPU的超算集群。后者则主要用来做带内管理和存储,应该是1个200G配置以太模式做带内管理,另一个200G配置IB模式做高速并行存储。
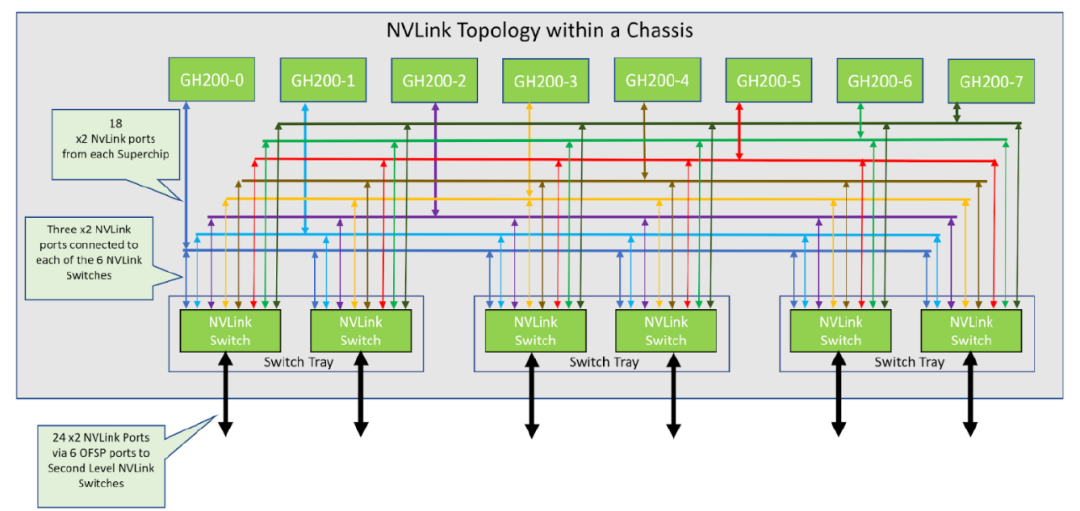
从上面内部逻辑图可以看出,每一个Grace Hopper Superchip芯片通过18根4代NVLink连接到6颗NVLink Switch ASIC芯片,这里一根NVLink代表2个NVLink ports,也就是2个112G PAM4的Lanes。每个NVLink Switch ASIC芯片对内通过24根NVLink连接到8颗Grace Hopper Superchip芯片,然后对外通过24根NVLink连接到L2 NVLink switch上,相当于一个ASIC对外伸出6个800G的OSFP口。
我们以一个机框为视角,3个L1NVLink Switch共6个ASIC, 向内每个ASIC通过24个NVLink4连接到8个GPU,总共6*24*200=3600GB带宽,向外每个ASIC通过24个NVLink4连接到6个L2 NVLink Switch上,总共24*6*200=3600GB带宽,32台L2 NVlink Switch应该是分成6组,每组6台交换机与所有32个机框中的相同位置NVLink ASIC全互联,6颗ASIC共可连接6组L2 NVlink Switch。
最终32个机框总共96台L1 NVLink Switch与36台L2 NVlink Switch进行胖树的全互联,做到1:1的无阻塞拓扑。
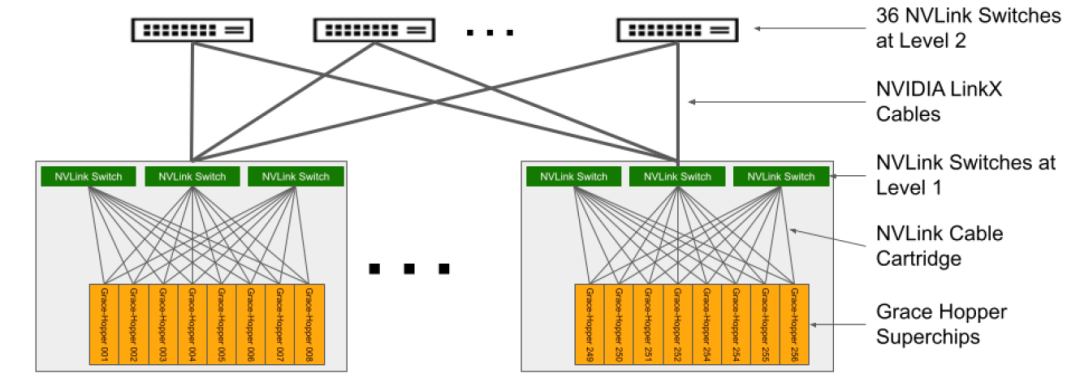
其它四张网
除了上面介绍的由NVLink和NVLink Switch组成的256个GPU的无阻塞计算网络,GH200超级计算机还包括了其它4个网络,与DGX Superpod的设计思路基本一致。
a.NDR400 IB网络
通过CX7 400G IB网卡和NDR 400G交换机可以组成一个胖树的无阻塞IB网络,支持轨道优化,SHARPv3,MPI和gRPC,并且可以扩展256个GPU,连接扩展其它DGX GH200的超级计算机集群。
b.NDR200 IB存储网络
每个Grace Hopper板卡上的一块双口 200G QSFP112 CX7或者双口 200G QSFP112 BF3的其中一个200G来做存储。单独做存储网络的目的是为了最大化存储性能,与计算网络互不干扰。每一块板卡推荐实现25GB/s的读写能力,整个GH200建议实现450GB/s的读写能力。
c.200G带内管理以太网络
前面说到的双口200G的另外一个200G口可以配置成以太模式,带内管理主要承担Base Command Manager自动化部署、SLURM或者K8S作业调度、NFS (home directory)服务、NGC内的docker image下载等功能。
d.1G带外管理以太网络
主要连接着每一块Grace Hopper Superchip板卡的BMC口,BF3的BMC口,还有L1,L2 NVLink switch的ComEx口,可以提供telemetry监控和firmware升级等任务。
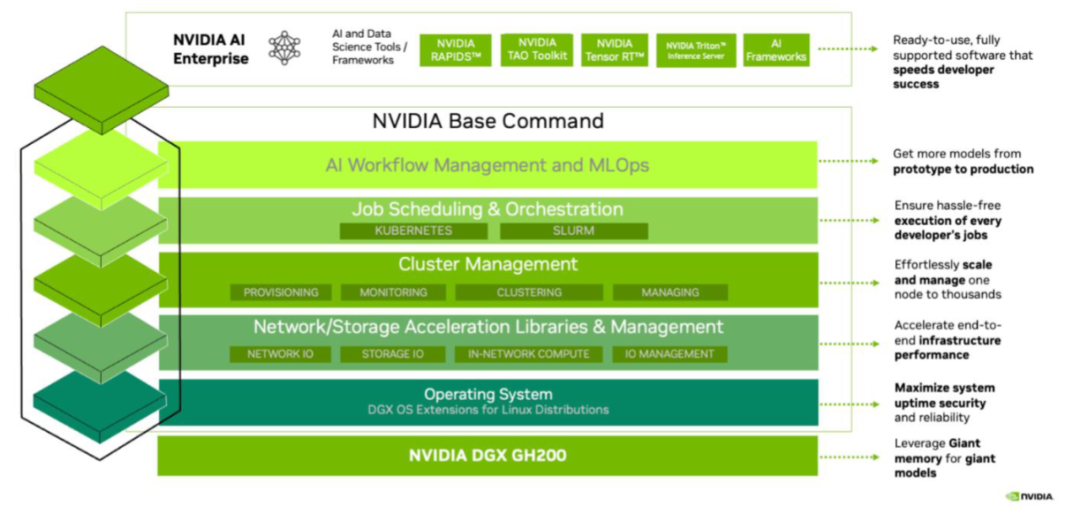
DGX GH200软件
从下图可以看出,GH200的软件框架与A100/H100的Superpod上软件框架基本一致,主要分为两部分,一部分是Base Command体系,包括DGX OS的自动化部署和安装,各种网络和存储的加速软件库管理,还有Base command manager用来做整个集群的各种软件自动化部署,健康监控和软件调度。Base Command还结合了Infiniband管理监控软件UFM和以太网交换机管理监控软件NetQ, 同时NetQ加入了对NVLink Switch系统的监控功能。另一部分是NVIDIA AI Enterprise框架,可以通过NGC软件中心来提供各种定制化AI软件应用的容器,比如已经安装好的TensorFlow,PyTorch,Nemo-Megatron等训练框架的容器,以及推荐系统,图像识别,文本翻译,HPC等各种AI应用容器。
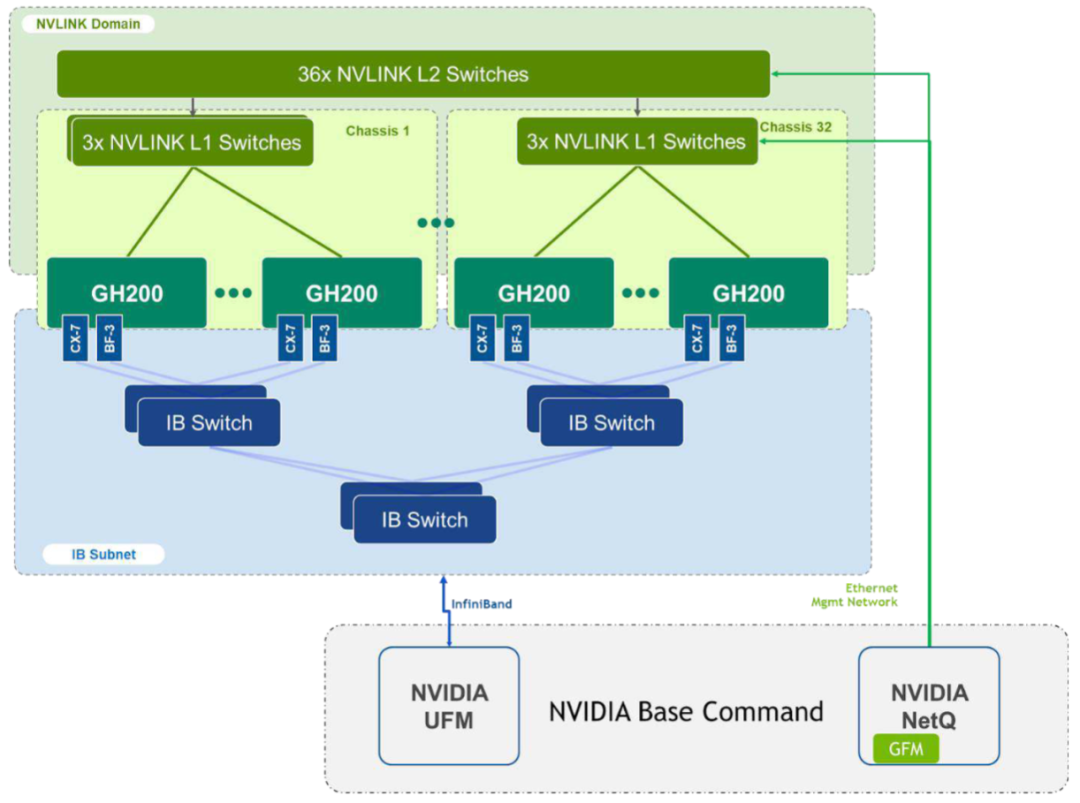
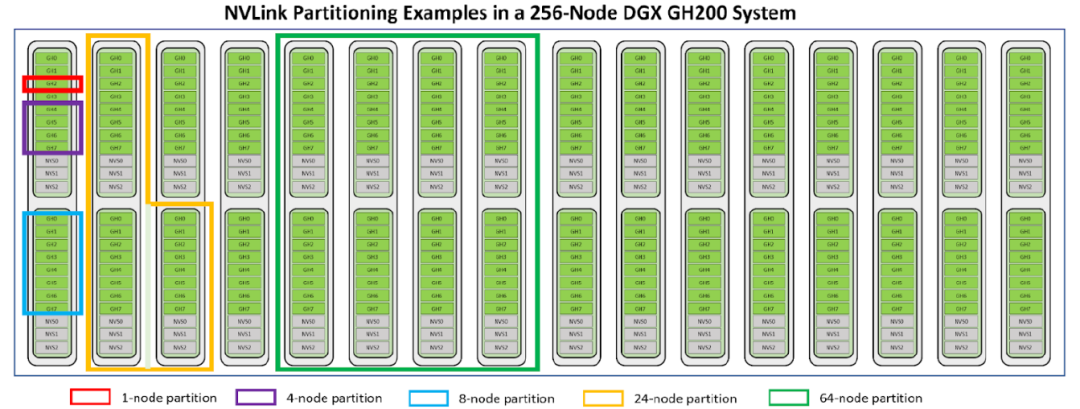
NetQ中的Global Fabric Manager(GFM)功能还可以支持对256GPU节点的partition拆分,做到不同partition之间的内存和性能完全隔离。
GH200 vs H100
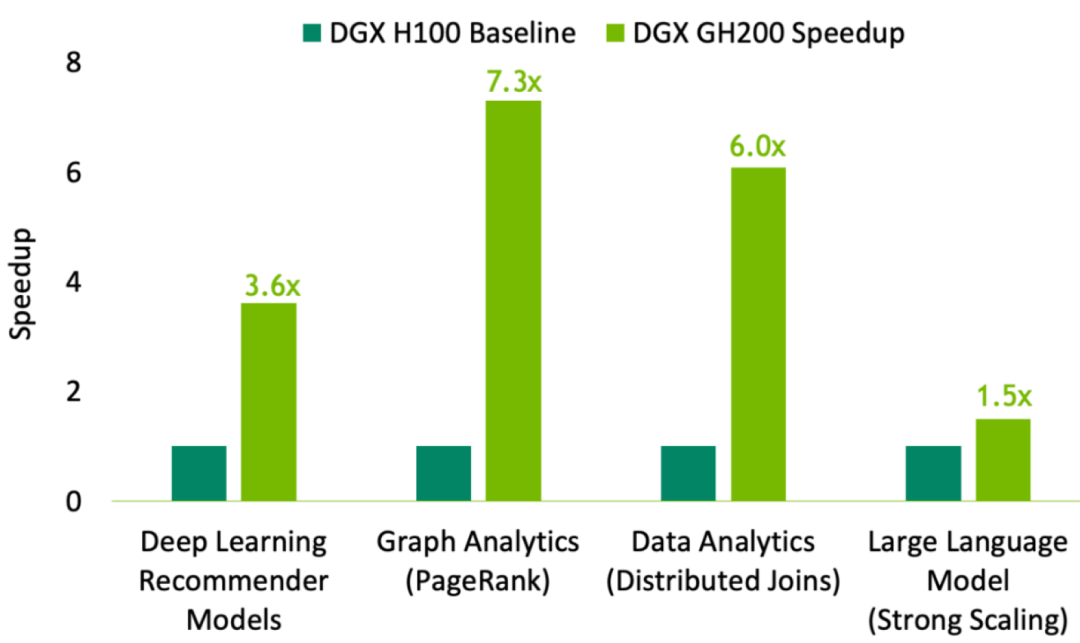
上图应该是GH200和32台DGX H100服务器(每机8卡)组成的IB网络进行的性能对比。GH200可以将256颗GPU和CPU高效的整个到一起,跨越了32台DGX H100服务器带来的GPU内存和网络通讯瓶颈,在推荐系统,图形和数据分析,大语言模型训练等方面都有一定的提升。
整体配置参数

最后再来看看整体配置参数,GH200可以根据客户实际需求定制32,64,128,256个GPU节点。NVIDIA还同时宣布在年底前建造名为"Helios"的超算集群,通过NDR IB网络将4个DGX GH200超级计算机连接在一起,总共提供1024块Grace Hopper GPU的算力。
总结
DGX GH200 AI超级计算机通过NVLink-C2C技术提供了CPU和GPU高速内存直接访问,通过NVLink高带宽,低延迟的连接将256块CPU和GPU高效的连接成一体,这些仅仅是管中窥豹,其中还有EGM,ATS(Address Translation Services),面向GH200平台内存访问优化的CUDA API等一系列创新技术,用来打造一个目前地表最强的应用于HPC和AI场景的超级计算集群。当然除了性能,客户还要考虑计算平台是否支持从x86向arm平台的转换。同时针对目前多机多卡集群的模型和数据的3D并行拆分方式,在GH200超级计算平台上也都会改变。
参考链接
https://nvidianews.nvidia.com/news/nvidia-announces-dgx-gh200-ai-supercomputer
https://resources.nvidia.com/en-us-grace-cpu/nvidia-grace-hopper?lx=TzzQDS
https://resources.nvidia.com/en-us-grace-cpu/grace-hopper-superchip
(注明:仅转载学习,无其他商业用途)

















 2700
2700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









