






原创: ikeke 行可可 今天
开篇:
最近有小伙伴关于咨询模型的一些相关东西,可能没有实践过,认知的过程有些难度?
1、什么是观察点?
2、什么是观察期?
3、什么是表现期,多久合适,怎么定义表现期?
4、模型怎么用,是做什么的,为什么建模?
5、申请、行为、催收的观察点和表现期分别又在哪,多久?
6、目标定义怎么确定?
7、vintage账龄分析是什么,用处在哪?
8、迁徙率和滚动率有什么区别?分别是做什么用的?
9、客群、模型、产品、之间的关系?
10、专家模型又是怎么回事?
其实当你真正做个一个项目也会遇到很多问题,本以为自己很熟悉,但却有的时候比较迷茫
下面我们拿一个真实的场景来具体建模过程中遇到的上面的问题
场景假设:
一、
某银行信用卡,主要针对代发工资户,企事业单位、白领进行发卡,政策,产品,风控策略已经设定好,这个时候模型怎么用?
这里就涉及到上面的,9和10的问题
9的问题:
一但前期设计好,其他不变,你的客群基本已经订好,所以你以后的样本要选择从这个产品上,就是样本必须都是使用过这个产品的样本,建立的模型严格点也只能用到这个产品上。
前期没有模型,使用专家模型也不是随便选择的,也必须按选择可以最优接近这个客群的已有的模型,所以企业成立初期挖人,都是要干过几乎一模一样事的人,但是很多企业很难找到这样的人,尤其整个市场初期,一个专家模型对你业务客群的代表性也往往决定着后续业务的逾期风险。
所以整体的产品设计,客群的针对,决定着你的模型,反过来,模型也只能用在这个产品才是合理的,有效的,用在其他的差异巨大的产品,模型算不上专家模型。
专家模型:就是有经验的人士,把自己积累多年的模型,拿过来直接用。
这个时候信用卡假设找到了专家模型人员,经过一致认同,开始上线,上线后我们积累了数据,所谓积累的数据,并不是累计了数据,而是重点你积累了这个人在你这个产品上的表现,这个表现就是他是好客户,还是坏客户,具体是还款良好的客户还是逾期坏账的客户。
说到这里就提到了模型的样本、观察、表现、目标
样本:
必须是你这个产品的、然后有表现的数据,而且可以明确的定义样本的好坏1和0.
观察点:
这个观察点可以理解为你能收集x变量的截止点。有的同学没有做过,非纠结到还款日当天。这个也有问题,但是你要知道这个模型在哪用,结合实际的环境。你申请信用卡的时候,这个时候银行就要跑模型,决定是否给你批卡授信,所以我的模型在这个时候用,我的观察点就在这块。截止到这个点之前的数据我都可以收集。从授信批卡日到首个还款日的数据我在使用模型是收集不到数据的,这个前后逻辑不对。
凡是做事情你要知道要具体需求是什么,你的目的是什么,就会清晰很多。
观察期:
观察点之前的时期都叫观察期,从出生那一天到观察点叫做观察期也没问题。
银行一行都是2年左右,这个也没固定,假如你发现一个变量在5年前,对你的目标预测能力很强,而且稳定,直接用。之所以行业普遍2年,也说明2年前的数据没有什么预测能力,滞前性太前。这个2年也不是固定,像现金贷短期的,可能在3个月,6个月更短。所以这个观察期一般就是能收集大部分有预测能力变量的时间范围。
像这个信用卡项目,观察期可以更长2-5年,大部分变量在征信报告中,这个征信数据是伴随人的一生,很长,都可以去分析,更长时间的数据,甚至10年。
目标:
为什么定义这个呢,你的模型x+参数=y。x前面的观察期和观察点选好了,就去衍生吧。参数呢,就是你知道了y,各种算法去求这个值了。这里不涉及讲解算法,主要是逻辑回归,决策树、GBDT、神经网络等有监督的模型算法。所以剩下的定义就是这个目标。这个目标定义的准确直接影响你求出的模型参数,所以目标定义不好,求出的参数不准确,模型的预测能力也不理想。
目标定义就是样本y的定义,例如,信用卡账单发生逾期大于60天定义为坏,否则定义为好,这么简单的。哦,一般方法会分为三部分,确定:逾期天数小于30为好客户,30到60为不确定,大于60天为坏客户。不确定的样本不确定了就别放模型了,因为你不知道y是1还是0.。有的同学会问,那建立的模型预测不确定的未来样本怎么办,这个有意思。回答来就是什么样本建的模型,用在什么预测上,也许预测不确定的就是概率0.5。哈哈哈,因为不确定本身没有参与建模,也不能预测不确定。这块不用纠结。现实中也是用在所有的客户上的。不确定客户用模型预测就是不会那么很准罢了。
话说回来,这个60天是固定的么。当然不是,怎么确定的呢,说下一个问题
迁徙率:
说到这我要说下和滚动率的区别。我之前也很疑惑,看了很多文章,至今很多文章也是混淆的,但是我讲下我的认知,他俩是严格有区别的。
滚动率:
就是假如100人本次还款逾期30天以上了,他们都正常还款后,再借款,再发生逾期30天以上的概率,假如有80人下次仍然逾期30天以上,这个30天以上逾期的滚动率就是80%。有10人到60天以上,滚动到60+的就是10%,有10人正常还款了,滚动到正常的是10%,这就是所谓的滚动率。
也就是说80%的人在发生逾期30天以上后下次借款仍然会继续逾期30天以上。我个人感觉这个样本很难搞哈,M1,M2,的滚动率还好,那么M5,M6的呢,几乎没法算了,谁也不会再给这样的人放款了,所以也不知道样本了。哈哈哈
那迁徙率呢,拿上面同样的例子。这100人逾期30天了,记住不是正常还款后的下次,跟上面区分在这,就是本次,这100个人有80个人继续逾期到60天,30-60天逾期的迁徙率就是80%。然后又有40人逾期到90天了,那么40/80=50%,就是60-90的迁徙率。
这个迁徙率代表的就是客户经过催收,回款的难度,迁徙率越高,说明回款难度越大,达到90%多,说明几乎没有回款,也就是我们可以定义这个群体样本的好坏了。
假如这个信用卡业务我们看迁徙率:从逾期60天迁徙到逾期90天有90%多,我们这个时候就定义逾期大于等于60天为坏目标。反过来从逾期30天到逾期60天有50%,这个时候定义大于等于30天是显然不合理的,因为还有一半的人回款了,变成了好客户。
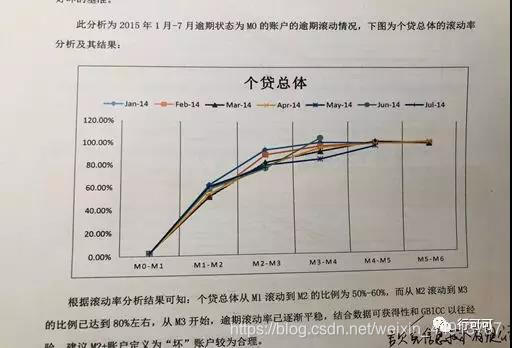
这个文章分析的就是迁徙率,文章说的是滚动率,所以上文说的目前有的比较混淆,当然也许是我还不专业,哈哈哈,这个不重要,这个表就是在定义目标。很直观。M3-M4几乎100%,你就可以直观的定义坏目标了吧。
表现期:
这个定义简单就是开始有样本表现的日期,审批之后的都可以叫表现期,只不过模型里的这个表现期就具体些了,一个客户可能用信用卡几年之后你才能确定这个客户是好坏,我们不能等3年再去建模吧,啥都凉了。就算一个12期的产品,我们也不能等12个月吧,这个时候就需要选择一个表现期,最短的时间来选择样本定义表现期进行建模。怎么选择表现期呢:这个表现期需要能代表大部分客户都能定义是好坏了。怎么大部分定义,下一步讲解另一话题,vintage。
Vintage账龄:
假如这个信用卡业务,就是先把单独一个月放款的客户拉出来,我们看这个单独的月份的在未来1、2、3、4、5、6、等各个账龄下发生目标的概率(这块直接说的是目标的概率,就是前面定义看逾期大于等于60天的概率,也就是逾期大于等于60天的坏账,因为我们目标定义好了,我们直接看这个目标的概率什么时候稳定,也就是坏的已经坏的差不多了,好的已经也好的差不多了,然后在概率稳定的时候就是定义表现期的时候)。然后我们在把每个月的这个曲线放在一块,看是否稳定。然后我们定义表现期。
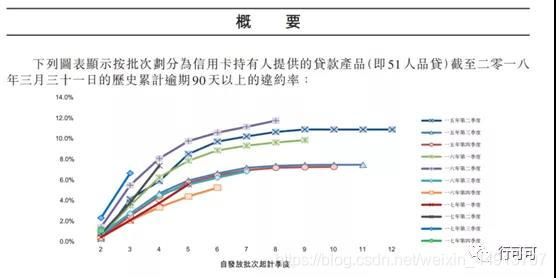
51的上市年报,假如我们目标定义的是90+,我们看在到第8个月,每个季度的逾期都很平稳,所以选择在放款后的8个月账龄作为表现期,因为这个时候好坏占比已经趋于稳定。也就是说8个月内足以判断大部分客户是好是坏。
所以迁徙率的目的是定义目标,而vintage就是确定表现期。
综上所述:
通过观察点,我们来选择这个点之前数据作为模型的x
X所产生的这段时间就是观察期
我们在通过迁徙率定义y
定义好y后我们在通过vintage定义表现期
然后我们在这个表现期内去生成我们样本的好坏目标
这样模型的x,y在业务上、逻辑上、量化上做了最好的准备,我们在通过纯粹的算法去建立模型求出参数。
所以提到一个问题,不是上来就跑模型、写代码。上面的阐述的任何一个细节没做好,直接决定着模型的质量。
最后好像还有个问题没有回答,
申请、行为、催收的一些观察点、观察期、表现期都在哪?

大概是这个意思,也不太具体,哈哈哈。

为了解答问题,我又把之前研究的文章翻开了,写作我是认真的,哈哈哈哈
当然答案永远在你的求知路上,希望有所帮助!

















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









