







 本文介绍了如何在PyTorch中使用torchvision.datasets.CIFAR10数据集,并演示了如何结合transform功能进行图片批量变换,包括从官网下载、数据结构分析及transform操作的实际应用。
本文介绍了如何在PyTorch中使用torchvision.datasets.CIFAR10数据集,并演示了如何结合transform功能进行图片批量变换,包括从官网下载、数据结构分析及transform操作的实际应用。
pytorch官网提供一些数据集api
1、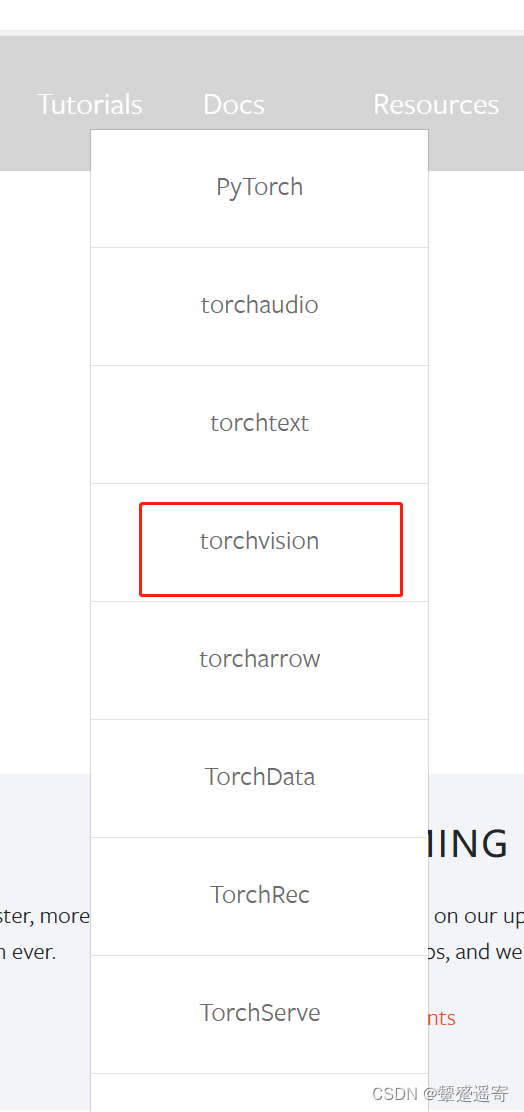
2、左侧此处可以查看不同版本的文档 up是0.9

另外

此处有一些神经网络模型:分类、语义分割、目标检测、视频分类等。
今天主要讲解。 torchvision.dataset。 以及dataset如何与transform联合使用实现图片批量变换
一、我们首先学习如何使用所给的数据集
1、看文档
打开cifar

这是官方文档的一些说明
CLASStorchvision.datasets.CIFAR10(root: str, train: bool = True, transform: Union[Callable, NoneType] = None, target_transform: Union[Callable, NoneType] = None, download: bool = False) → None[SOURCE]
CIFAR10 Dataset.
Parameters:
root (string) – Root directory of dataset where directory cifar-10-batches-py exists or will be saved
to if download is set to True.
//这里是说存放位置//
train (bool, optional) – If True, creates dataset from training set, otherwise creates from test set.
//若是true,则用来训练。如果是false,则用来测试//
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
//对数据集进行一些变换//
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
//对于target进行transform//
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
//如果是true,则从网上下载数据集,如果为false,则不会下载//
__getitem__(index: int) → Tuple[Any, Any][SOURCE]
Parameters: index (int) – Index
Returns: (image, target) where target is index of the target class.
Return type: tuple
2、 自己输入看看
import torchvision
train_set =torchvision.datasets.CIFAR10()

继续:
import torchvision
train_set =torchvision.datasets.CIFAR10(root="./P14_dataset",train=True,download=True)
//这里设置相对路径,训练,从网上下载,没设置transform//
//这里改为训练//
test_set=torchvision.datasets.CIFAR10(root="./P14_dataset",train=False,download=True)
观察到下方正在下载,左侧多了文件夹

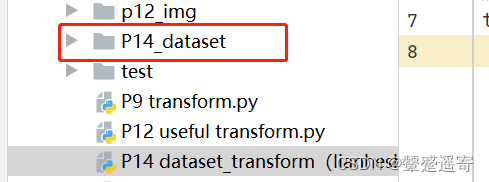
并且此相对路径产生的文件夹是与我们的python文件级别并列的
插个题外话****如果下载过慢可以使用迅雷把上方网址辅助到迅雷下载,。
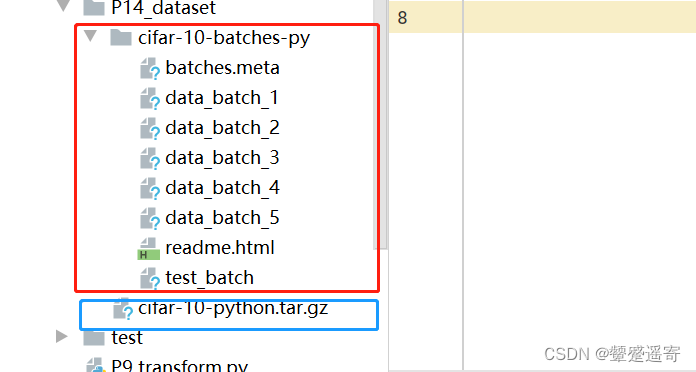
3、可以看到首先下了一个tar格式的压缩文件,然后会对文件自动解压
4、增加断点,debug下,我们可以看到一些东西。。
比如会有图片,还有对应的target
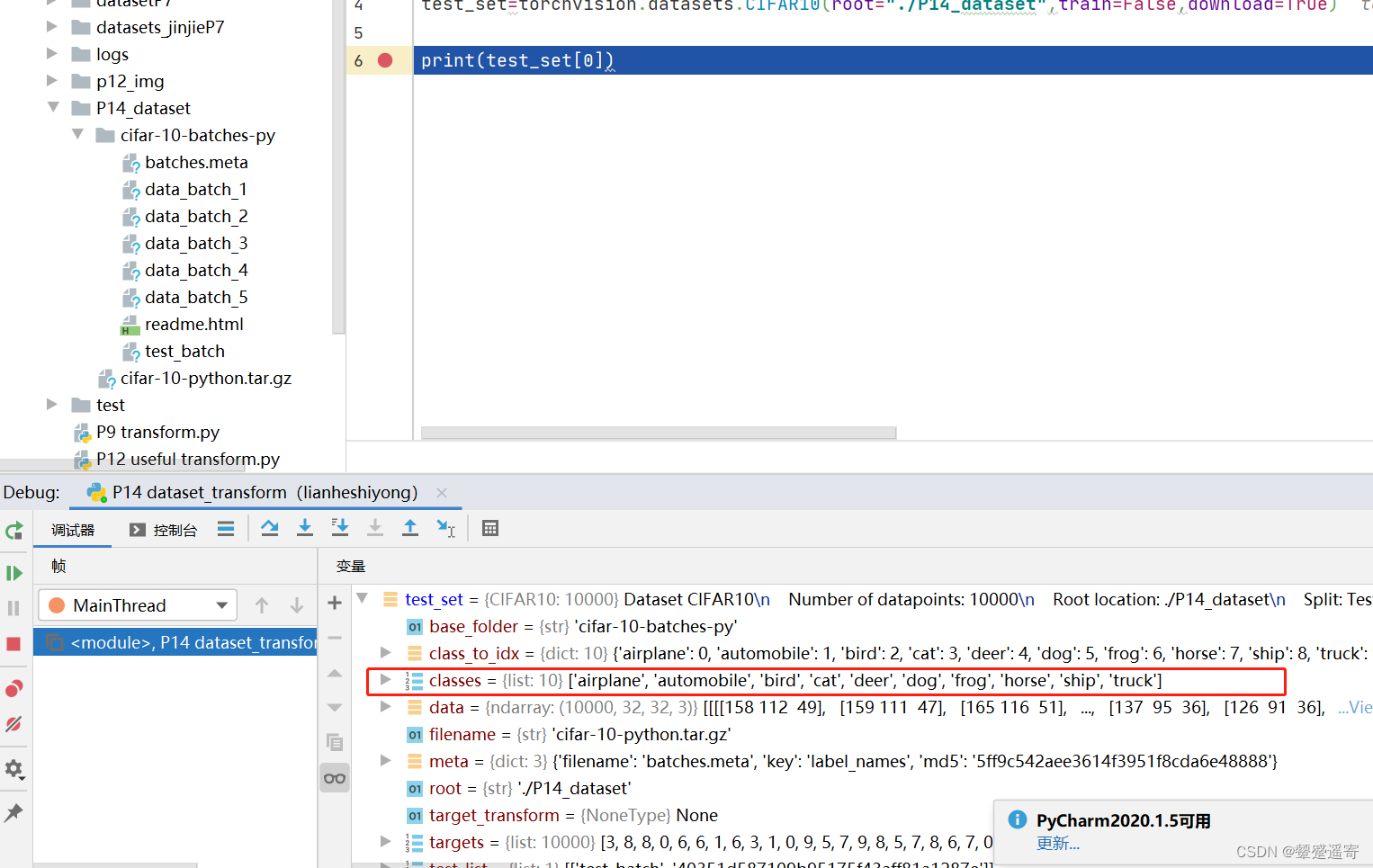
5、
似乎会自带图片和对应的target
import torchvision
train_set =torchvision.datasets.CIFAR10(root="./P14_dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./P14_dataset",train=False,download=True)
print(test_set[0])
print(test_set.classes)
img,target=test_set[0] //注意这里//
print(img)
print(target)
print(test_set.classes【target】)//这里target已经在上一步赋值了数字//
img.show()
(<PIL.Image.Image image mode=RGB size=32x32 at 0x2736347FF70>, 3)
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
<PIL.Image.Image image mode=RGB size=32x32 at 0x2736347FFA0>
3
cat
我们可以看到分别输出了target中含有的类:[‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’]
img类型是PIL
test_set【0】的图片是猫,输出的target 为3 显然是猫
二、再来讲解下CIFAR数据集

我这里没有显示,可能文档版本原因,up那里显示,有60000张32×32彩色照片分为10类,每类6000张,其中5000为训练,1000为测试。。
三、、与transform联动
1、
原始代码
import torchvision
train_set =torchvision.datasets.CIFAR10(root="./P14_dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./P14_dataset",train=False,download=True)
print(test_set[0])
print(test_set.classes)
img,target=test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
2、我们进行transform操作
先继承类
dataset_transform=torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor()
]
)
**这里增加一项transform操作**
train_set =torchvision.datasets.CIFAR10(root="./P14_dataset",train=True,transform=dataset_transform,download=True)
test_set=torchvision.datasets.CIFAR10(root="./P14_dataset",train=False,transform=dataset_transform,download=True)
看下结果
import torchvision
dataset_transform=torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor()
]
)
train_set =torchvision.datasets.CIFAR10(root="./P14_dataset",train=True,transform=dataset_transform,download=True)
test_set=torchvision.datasets.CIFAR10(root="./P14_dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
# print(test_set.classes)
#
# img,target=test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
print(test_set[0])
3、观察到转换为tensor类型

4、为了方便观察,我们可以使用tensor_board来看自己的结果。
import torchvision
import tensorboard
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor()
]
)
train_set =torchvision.datasets.CIFAR10(root="./P14_dataset",train=True,transform=dataset_transform,download=True)
test_set=torchvision.datasets.CIFAR10(root="./P14_dataset",train=False,transform=dataset_transform,download=True)
//这里关键。//
writer=SummaryWriter("P14")
for i in range(10):
img,target=test_set[i]
writer.add_image("P14",img,i)
writer.close()
//以上。。//
# print(test_set[0])
# print(test_set.classes)
#
# img,target=test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
#
# print(test_set[0])


有意思,,
四、其他数据集
以coco为例子

只是多了个annfile放json文件的位置
另外我们可以鼠标+左键
去找url从而下载数据集



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









