








from PIL import Image
img=Image.open("D:\\PyCharm\\Py_Projects\\XiaoTuDui\\p12_img\\20230909152247.png")
print(img)
<PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1167x896 at 0x199AAA62310>
一、先看compose,可以结合compose——resize——2
compose似乎是进行多步操作,所以要用列表
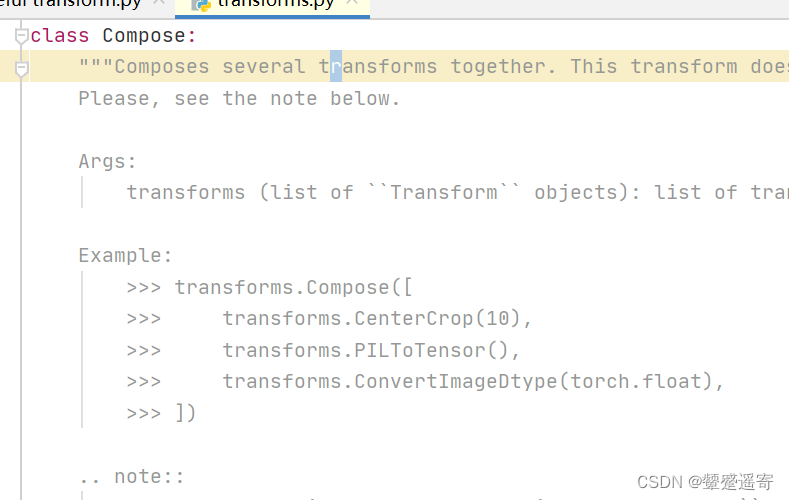
我们发现图片会
1、先被裁剪
2、转换成totensor
二、看toTensot
“”"Convert a PIL Image or ndarray to tensor and scale the values accordingly.
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
img=Image.open("D:\\PyCharm\\Py_Projects\\XiaoTuDui\\p12_img\\20230909152247.png")
print(img)
trans_tensor=transforms.ToTensor()
img_tensor=trans_tensor(img)
writer.add_image("tensor",img_tensor)
writer.close()

toPILimg是把tensor转成pIL
三、看normalize的使用
归一化:
class Normalize(torch.nn.Module):
"""Normalize a tensor image with mean and standard deviation.
This transform does not support PIL Image.
Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
channels, this transform will normalize each channel of the input
``torch.*Tensor`` i.e.,
``output[channel] = (input[channel] - mean[channel]) / std[channel]``
.. note::
This transform acts out of place, i.e., it does not mutate the input tensor.
Args:
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation in-place.
"""
需要给处均值(mean)
标准差std
for 维度n channels(rgb三通道)
output[channel] = (input[channel] - mean[channel]) / std[channel]``输出=输入channel-均值最后除以标准差
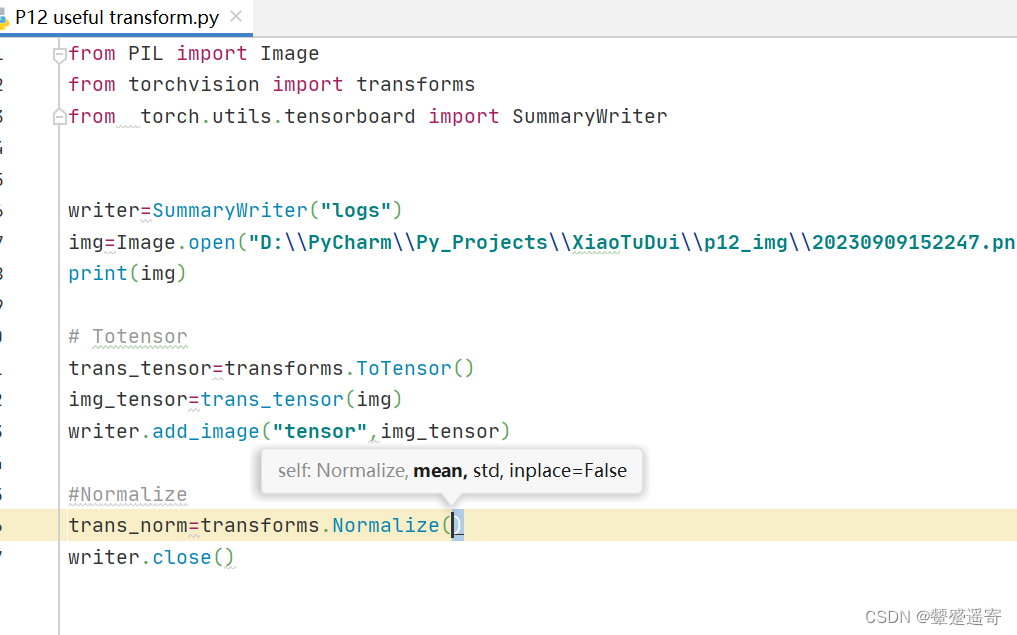
可以看到要输入均值、标准差
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
img=Image.open("D:\\PyCharm\\Py_Projects\\XiaoTuDui\\p12_img\\20230909152247.png")
print(img)
# Totensor
trans_tensor=transforms.ToTensor()
img_tensor=trans_tensor(img)
writer.add_image("tensor",img_tensor)
#Normalize
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) //由于这里是rgb三通道,所以不管是均值还是标准差都要输入三个//
img_norm=trans_norm(img_tensor)
writer.close()

根据公式
print(img_tensor[0][0][0]) //先看最开始的第0层(个通道),第0行,第0列//
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0]) //再看归一化后的第0层(第0个通道),第0行,第0列//
输出结果为
tensor(0.3137)
tensor(-0.3725)
根据公式。2×0.3137-1显然=-0.3725
最后
# Totensor
trans_tensor=transforms.ToTensor()
img_tensor=trans_tensor(img)
writer.add_image("tensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
writer.close()
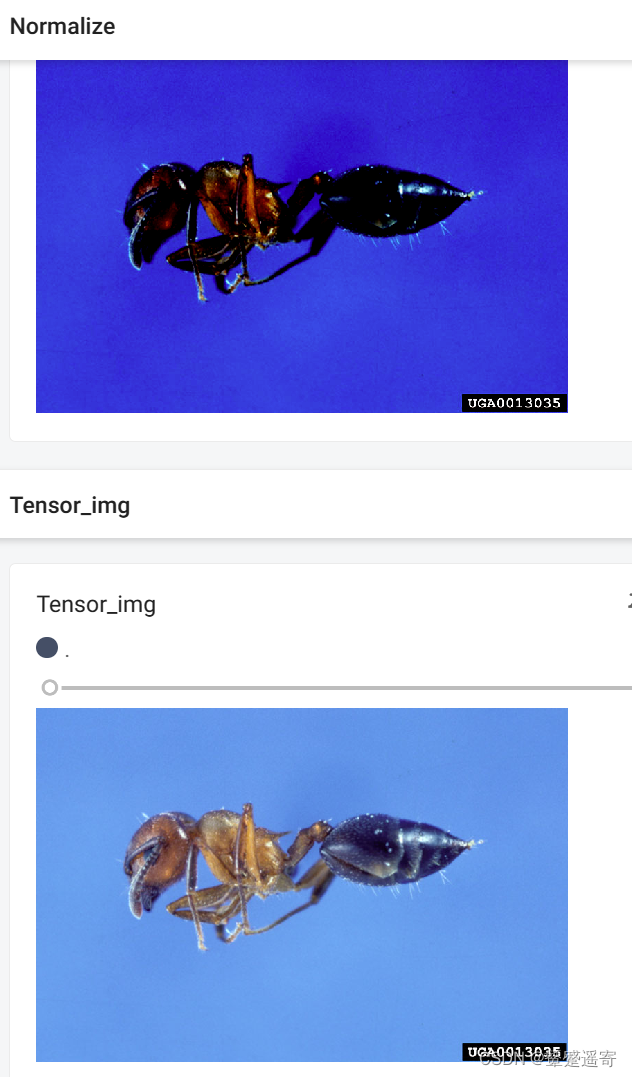
可以看到归一化后的图片
我们再修改一些参数放在step1
trans_norm=transforms.Normalize([1,3,5],[3,2,1])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,1)
writer.close()

四、resize的使用
先看介绍

类似于做一个等比缩放
另外其中warning:
在对图像进行降采样(downsampling)时,使用不同的插值方法会导致PIL库和张量(tensors)之间存在轻微的差异,因为PIL库会应用抗锯齿(antialiasing)技术。这些差异可能会对神经网络的性能产生显著影响。
为了保持一致性,通常建议使用相同的输入类型来训练和部署模型,也就是使用相同的库或框架进行训练和推理。需要注意的是,PIL库中的antialias参数可以帮助使PIL图像和张量的输出结果更接近,但它并不能完全消除两者之间的所有差异。
大概就是用PIL格式更好吧。。
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
img=Image.open("D:\\PyCharm\\Py_Projects\\XiaoTuDui\\p12_img\\0013035.jpg")
print(img)
# Totensor
trans_tensor=transforms.ToTensor()
img_tensor=trans_tensor(img)
writer.add_image("tensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([2,2,2],[0.1,0.2,0.3])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,1)
//再上文的基础上输入
#resize
print(img.size)
trans_resize=transforms.Resize()
img_resize=trans_resize(img)
print(img_resize)
writer.close()

ctrl+p显示需要输入大小应该是高宽
我们输入512 512
trans_resize=transforms.Resize((512,512))
运行后:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=768x512 at 0x1A01F37F160>
tensor(0.3137)
tensor(-16.8627)
(768, 512)
<PIL.Image.Image image mode=RGB size=512x512 at 0x1A01F3E0EB0>
观察到原来的768,512 变为了512,512
并且是PIL格式
为了最后得到totensor类型:
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
img=Image.open("D:\\PyCharm\\Py_Projects\\XiaoTuDui\\p12_img\\0013035.jpg")
print(img)
# Totensor
trans_tensor=transforms.ToTensor()
img_tensor=trans_tensor(img)
writer.add_image("tensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([2,2,2],[0.1,0.2,0.3])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,1)
#resize
print(img.size)
trans_resize=transforms.Resize((512,512))
# img PIL→ resize →img_resize PIL
img_resize=trans_resize(img)
print(img_resize)
#img_resize PIL→ img_resize tensor
//此处为新加代码。///
img_resize=trans_tensor(img_resize) //注意这里不要写
transform.TOtensor(img_resize)会报错,写trans_tensor是因为已经把
transform,torensor实例化了//
writer.add_image("Resize",img_resize,0)
writer.close()
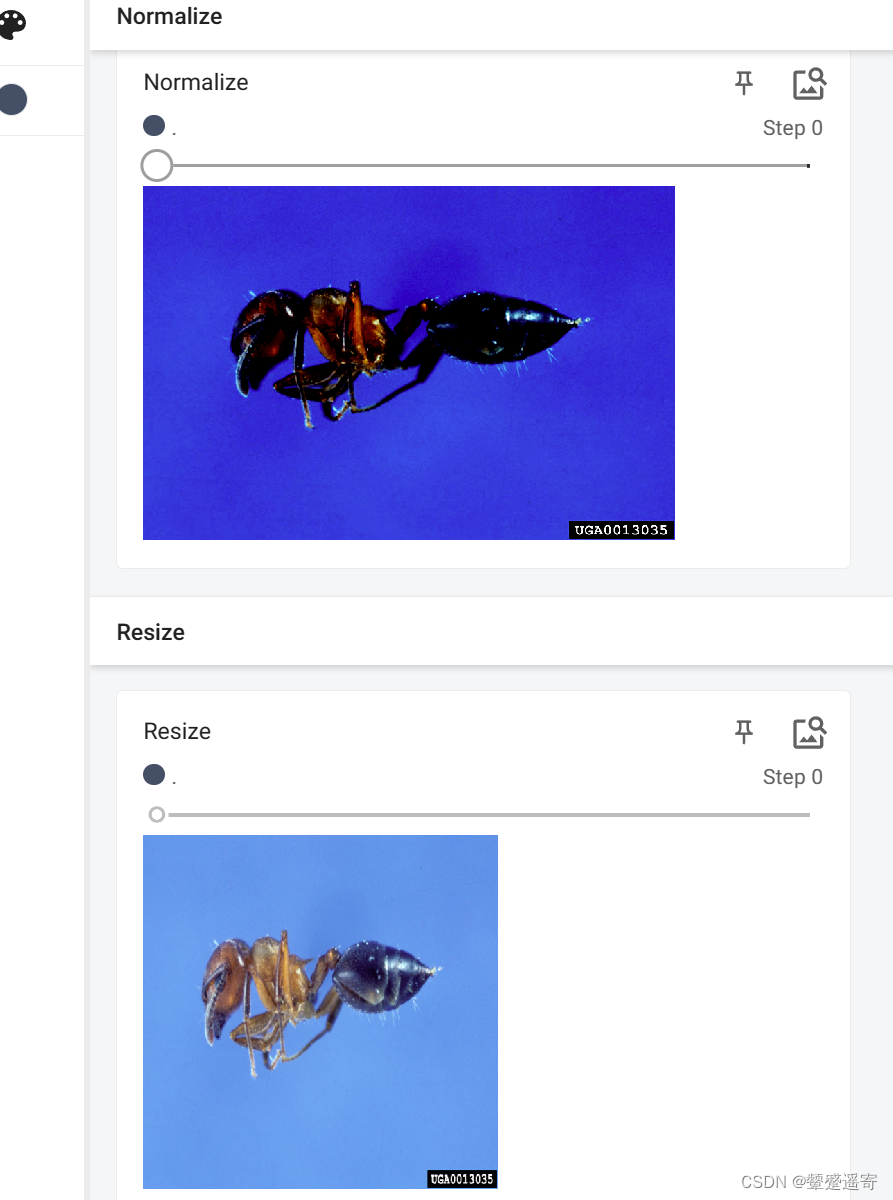
终端的对比效果如上
五、compose-resize的用法

并且输入是PIL格式
trans_resize_2=transforms.Resize(512)
# PIL → PIL → rensor
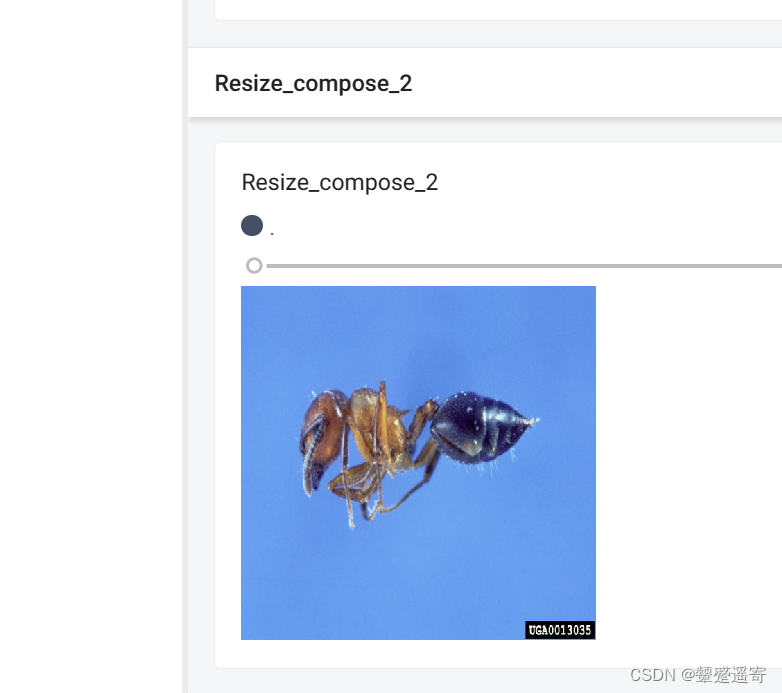
trans_compose=transforms.Compose([trans_resize_2,trans_tensor])
img_resize_2=trans_compose(img)
writer.add_image("Resize_compose_2",img_resize,0)
writer.close()
其他需要注意的
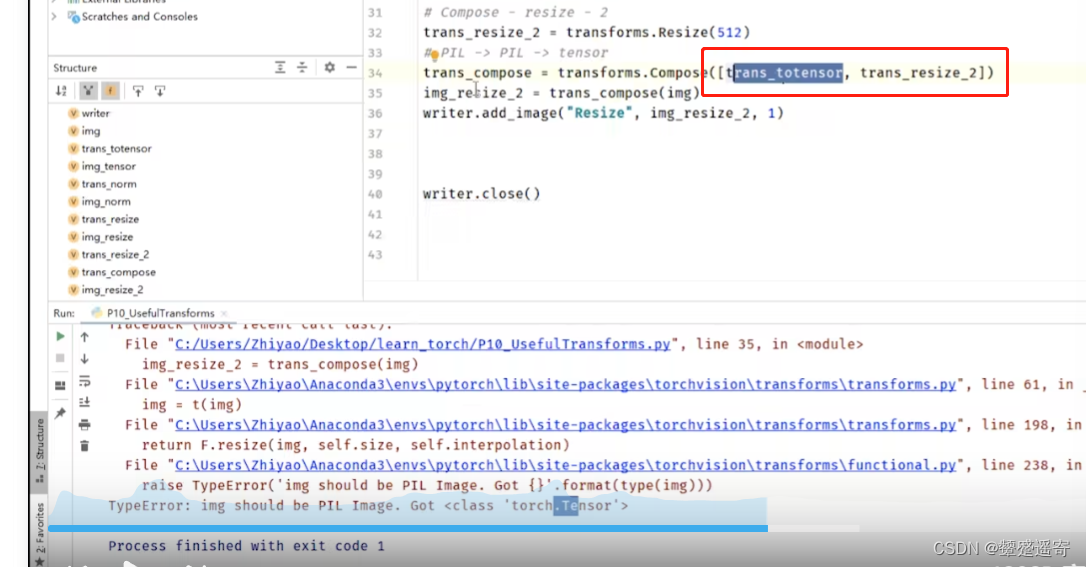
compose似乎是进行多步操作,所以要用列表

up这里调换了transform_tensor 与 trans_resize_2位置,那么操作顺序变了,、
trans_resize——2要求PIL格式
所以报错了
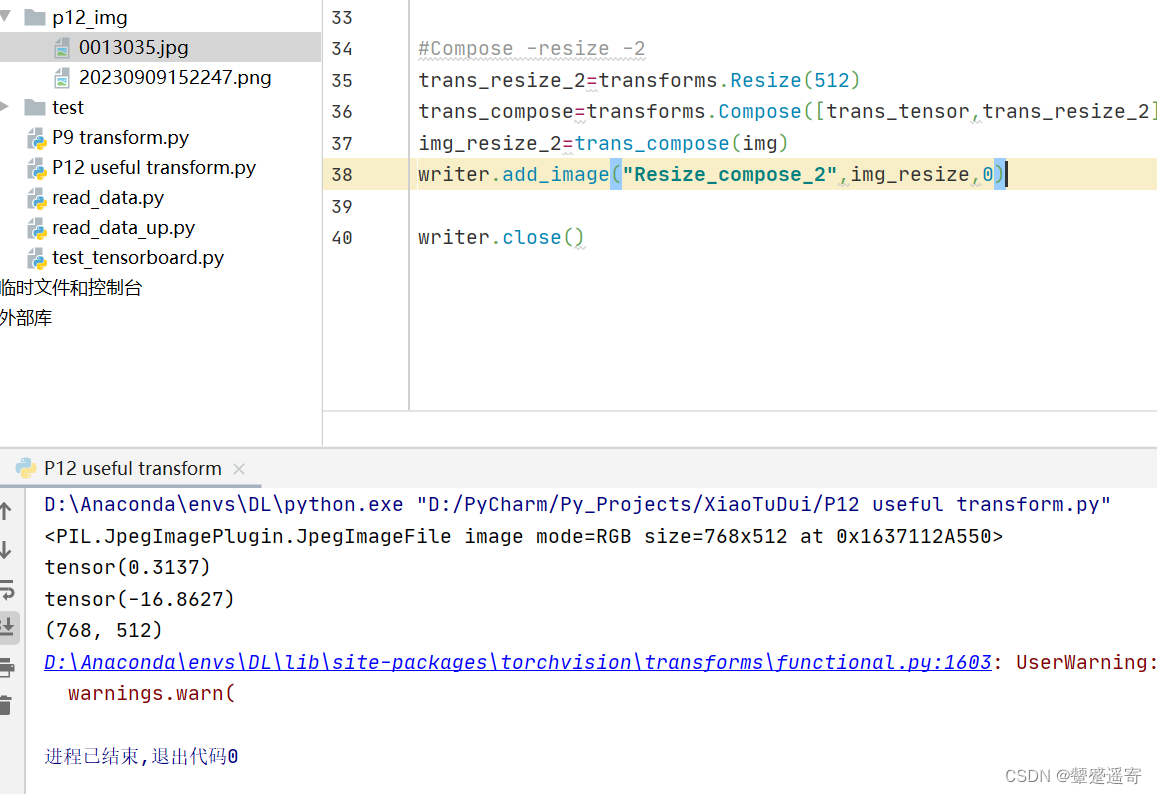
我没有报错似乎是因为resize现在可以读取tensor格式
 ## 六、RandomCrop
## 六、RandomCrop
先看介绍,参数这里要么给一个序列(sequence)((高,宽))或是一个值int,他会裁剪承一个正方形,比如输入512,他会裁剪512×512
Args:
size (sequence or int): Desired output size of the crop. If size is an
int instead of sequence like (h, w), a square crop (size, size) is
made. If provided a sequence of length 1, it will be interpreted as (size[0], size[0]).
padding (int or sequence, optional): Optional padding on each border
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
img=Image.open("D:\\PyCharm\\Py_Projects\\XiaoTuDui\\p12_img\\0013035.jpg")
print(img)
# Totensor
trans_tensor=transforms.ToTensor()
img_tensor=trans_tensor(img)
writer.add_image("tensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([2,2,2],[0.1,0.2,0.3])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,1)
#resize
print(img.size)
trans_resize=transforms.Resize((512,512))
# img PIL→ resize →img_resize PIL
img_resize=trans_resize(img)
#img_resize PIL→ img_resize tensor
img_resize=trans_tensor(img_resize)
writer.add_image("Resize",img_resize,0)
#Compose -resize -2
trans_resize_2=transforms.Resize(512)
trans_compose=transforms.Compose([trans_resize_2,trans_tensor])
img_resize_2=trans_compose(img)
writer.add_image("Resize_compose_2",img_resize,0)
#RandomCrops
trans_random=transforms.RandomCrop(512)
trans_compose_2=transforms.Compose([trans_random,trans_tensor])
for i in range(10): //这里我们随机裁剪生成10张//
img_crop=trans_compose_2(img)
writer.add_image("Random",img_crop,i)
writer.close()

可见随机生成了10个。
现在来看指定高、宽的效果

**
七、总结
**
1、关注输入、输出及他们的格式类型
2、多看官方文档
3、关注方法需要什么参数

举例,像图中的padding没有给定默认值,则需要我们自己设置。

比如这里需要int或元组类型。
不知道返回值的时候我们可以用prit或者print type来看类型或者debug




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









