









值传递(pass by value):
在内存(程序堆栈)中开辟新的空间,将原值复制到新的空间中
传址(pass by reference):
不在内存中开辟新的空间,作为原变量的别名,不独立,依附于原变量,对其的改变会直接修改原变量,引用不可修改,只可在初始化时指定
指针传递(pass by pointer):
在内存(程序堆栈)中开辟新的空间,新开辟的空间的值为原变量的地址,则指向原变量,对其进行提领(reference)操作之后的修改会影响原变量。
指针的引用传递(传址):
由于指针实际上也是一块内存,所以和普通pass by reference 并无区别,是给指针起了给别名而已。
编译的角度
从编译的角度来讲,程序在编译时分别将指针和引用添加到符号表上,符号表中记录的是变量名及变量所对应地址。指针变量在符号表上对应的地址值为指针变量的地址值,而引用在符号表上对应的地址值为引用对象的地址值。
指针在符号表上对应的地址是存放指针的内存地址,而指针指向的内存地址是这块内存中存储的值
引用在符号表上对应的地址是原变量地址,实际上和int a=x的a并无区别。符号表生成之后就不会再改,因此指针可以改变其指向的对象,而引用对象则不能修改,就像你声明了变量a,但是在程序运行之中,你想要修改a这个变量的变量名是不切实际的,与引用同理。
(PS:除非你释放掉a的内存然后再申请这个内存?但这实质上已经不是修改a的变量名了)
为什么要有引用
C++之父Bjarne Stroustrup说主要是为了支持运算符的重载
我认为引用还有几个好处
a. 和指针一样,当我们传入对象时,值传递效率过慢,直接使用引用或者指针对于class object是相当高效的
b. 指针有空指针,但是引用没有空引用
c. 指针有野指针,但是引用必须初始化,排除了野指针
d. 引用的值不可改变,不会像指针一样,有时候会访问到不知不觉改变了的指针
理论上如上述,但是实际编译引用会占内存,其底层还是存储了一个指针变量,只是在编译和C++层面对这个指针加以限制,比如说以下实例。
实例
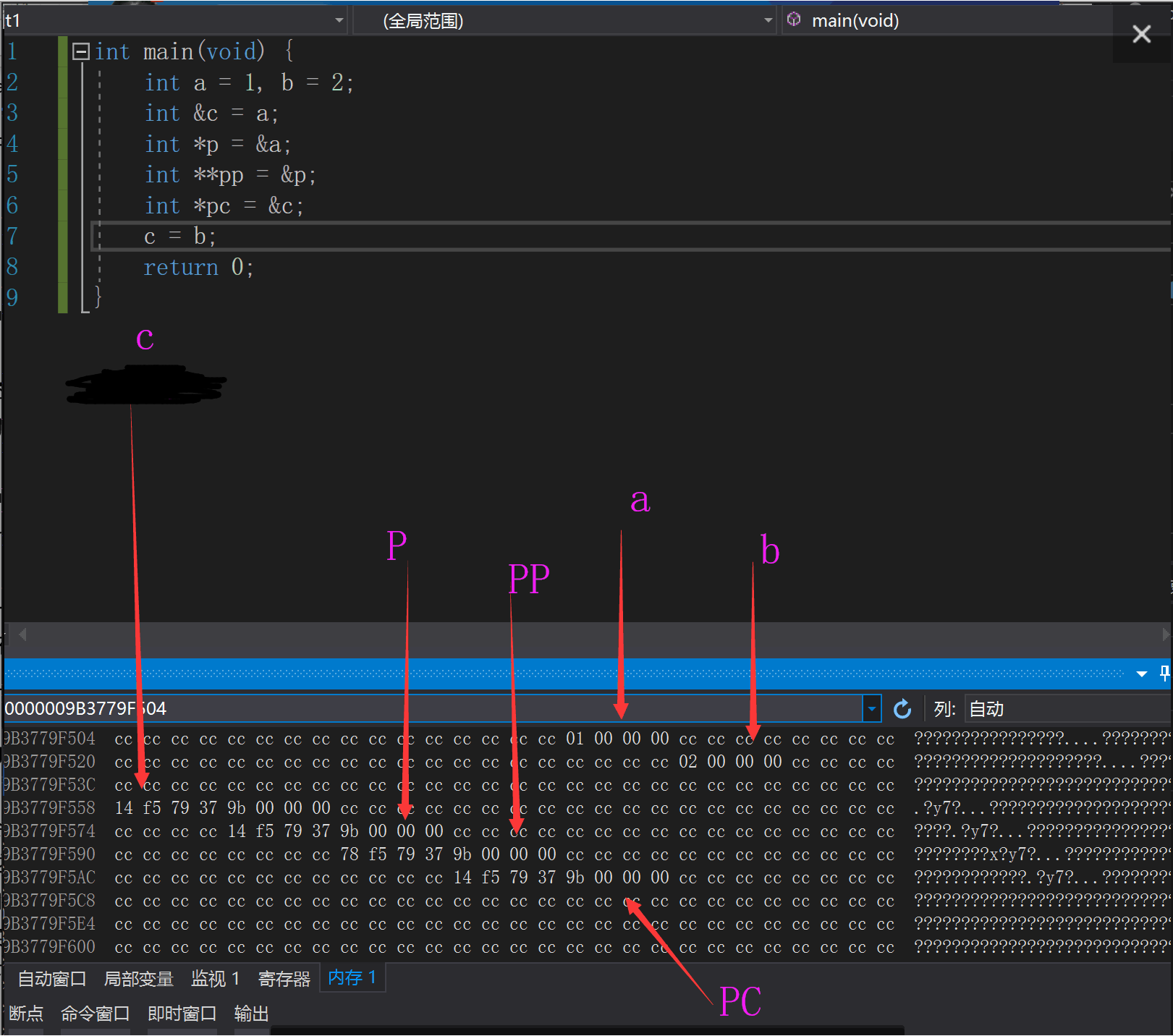

首先我们可以轻易看出除了c以外的所有内存代表的变量,可以看出,对c取地址的pc还是存储了a的地址,所以我们说在编译器和c++级别是适用我们之前的概念的,但是我们可以看到实际上还是存储了一个未知地址,那么它到底是不是引用c呢,我们反汇编查看一下
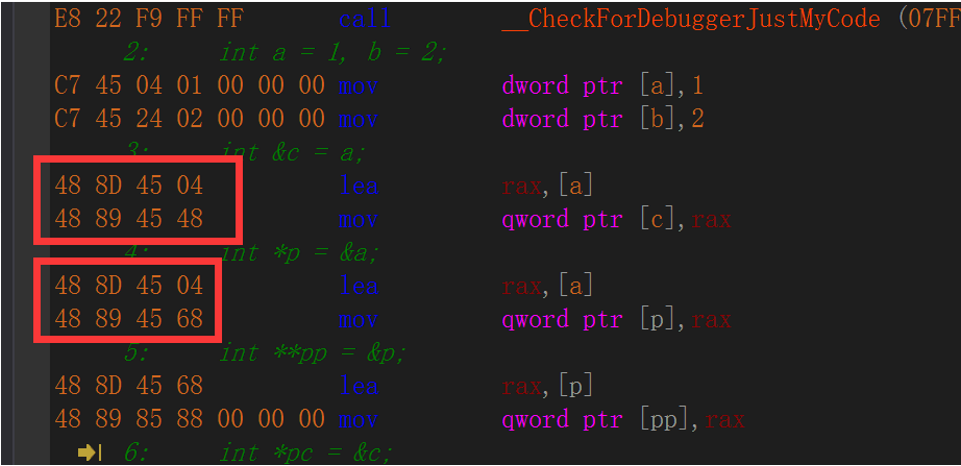
我们发现引用c和指针p一样,都取得了a的偏移地址,每个红框的第二句指令,发现他们存向了不同的地址,且两者偏移地址相差0x20H,我们回看上面的内存,发现存储第一个地址的内存地址和指针p刚好相差0x20h,且两个都占64位(当前机器位数,因为指针实际上存储的是寻址地址,取决于你CPU的寻址范围,太大用不着,太小不够用。严格来说,取决于你CPU位数,操作系统位数和编译器位数的最小值)
所以至此我们可以确定,上述的那个未知地址确实是引用c
为什么是0x20h
因为当前是debug版编译,会在内存对齐的基础上,DEBUG 版为了在变量访问越界的时候做出检测,在变量之间添加保护段并且用0xCC填充(也就是“烫”(0xCCCC)),0xCC在x86下是INT 3指令,这个指令会触发断点,这时候调试器便可发现越界等原因。相应的,堆里是0xCD填充,也就是“屯”(0xCDCD)
如果切换成release版本就会发现是对8字节对齐了
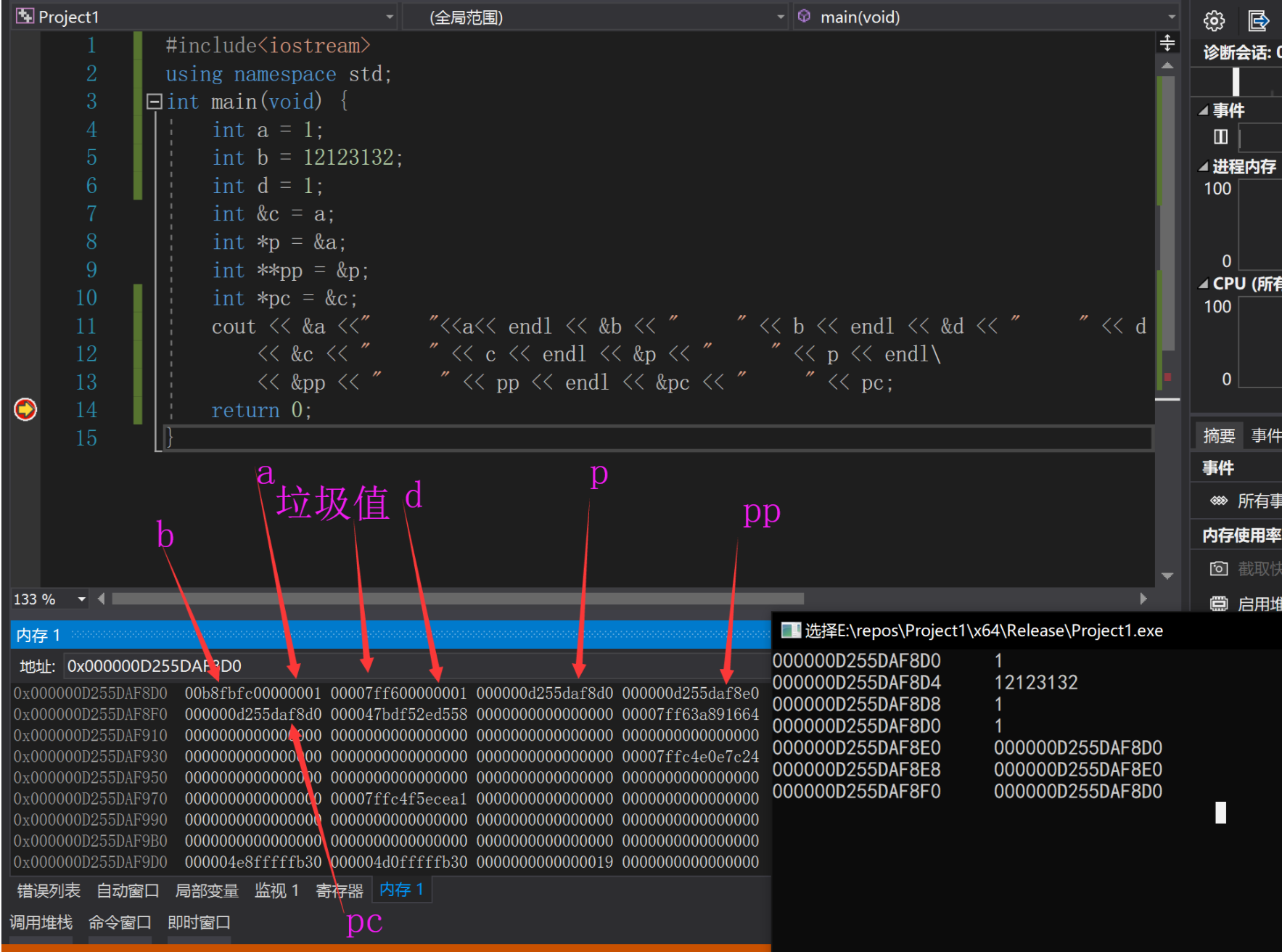
我们可以看到Debug下的0xCC不见了,但是c也不见了,而且a和b也存储在了同一个8字节中,且b在a“之前”,但是p又不跟在d之后存储。
我们一个一个解释
本次测试是在64位平台进行的
我们知道64位CPU的字长为64位,数据总线和地址总线也为64位,且除去8个80位浮点寄存器和16个128位XMM寄存器以外,剩下的均为64位寄存器,所以指针的大小为64位
因为CPU支持变字长运算,所以我们a和b被存在了一个字长(8字节)中,然后通过半字长运算即可取出
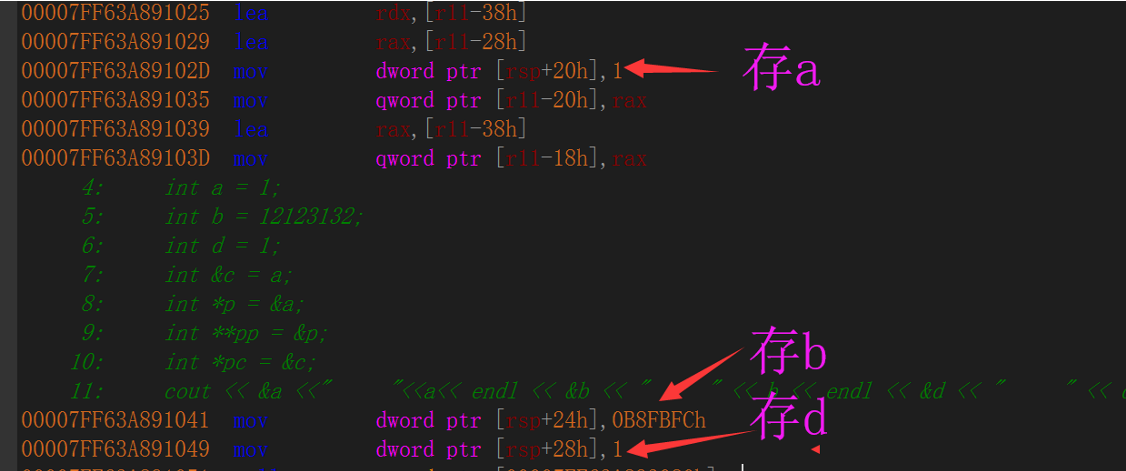
即指定以4字节(双字)存储在内存中
关于具体如何取值,我没有找到相关资料,以下括号内是我的猜测
{
我搜到了资料一般控制字是取模取值,所以我猜测像是b这样的地址,即不是字长整数倍的地址
,在字长对齐的前提下,可能是这样取地址的
OFFSET=内存地址%字长
读取 内存地址-OFFSET地址一个字长的内容
然后 访问OFFSET之后的指定长度的内容。
多倍字长运算则分解为多个单字长运算
//如果有朋友看出了错误,还望能在评论区指出,最好有附带资料,十分感谢
}
内存对齐以及内存对齐存取粒度
上面提到了内存对齐,内存对齐的原因是为了减少不必要的操作,牺牲部分空间来换取性能上的大幅提升,此时就引入了一个概念,内存对齐存取粒度
我们可能以为内存是一字节一字节连续的

但是CPU可不这么看,CPU读取内存是以字长为单位的(这里以字长32位为例)

我们以一个十分简单的例子来看内存对齐存取粒度对于性能的影响
假设我们要取一个4字节的数据到寄存器中
首先内存对齐存取粒度为1字节的情况

可以看到需要读取四次内存,我们知道现代CPU从内存中读取一次数据大约需要上百个时钟周期,这就造成了极大的浪费
我们再来看看内存对齐存取粒度为2字节的情况

这里可以看到,对于对齐地址只需要读取两次内存就可以了,但是如果我们要访问非对齐地址1开始的4个字节,我们需要进行三次内存读取,并且要对于两个红色方块读取的数据进行舍弃,合并才能完成读取,带来了额外的开销。减缓了操作的速度。
如果内存对齐存取粒度为4字节,即等于寄存器大小的情况下
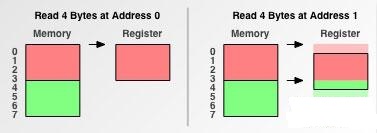
对于对齐地址读取一次内存即可,对于非对齐内存地址读取后的操作如下
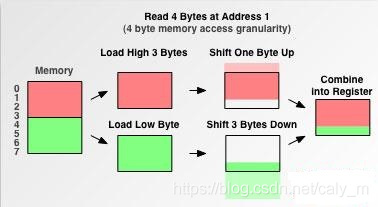
通过上述例子,我们应该可以明白为什么访问对齐内存地址要快的多了,那么,究竟能快多少呢,才能让我们去舍弃部分空间去换取时间性能,下面是几组数据。
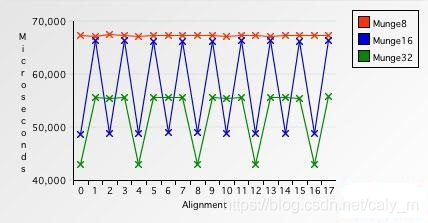
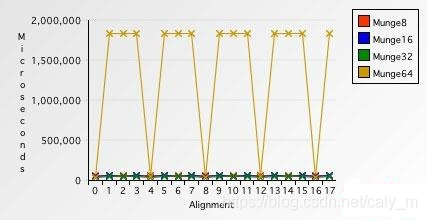
可以看出,对于任何内存对齐存取粒度来说,非对齐地址访问速度比对齐地址访问速度要慢的多,尤其是8字节的情况下,非对齐地址访问要比对齐地址访问慢4610%,这组数据还有个有趣的现象
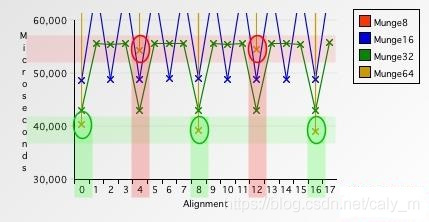
可以看出8字节在读取非对齐内存(4,12字节)的速度要慢于4字节存取粒度,所以说纯正的32位程序在64位平台上跑的时候,在其他条件相同的情况下,内存存取的速度是不如32位平台的,但是这个性能损失相比4610%就显得可以接受了。
相信看到这里,大家就明白了内存对齐的必要性,和为什么p不在d后面的连续地址存储了,如果这样存储,我们读取p的时候需要进行两次内存读取操作,多次移位和合并操作
那么再次回到引用:
为什么Debug下底层存储指针来实现,换到Release版引用 就不占用内存空间了
因为Debug 版本就是为调试而生的,编译器在生成 Debug 版本的程序时会加入调试辅助信息,并且很少会进行优化,程序还是“原汁原味”的。
Release 版本就是最终交给用户的程序,编译器会使尽浑身解数对它进行优化,以提高执行效率,虽然最终的运行结果仍然是我们期望的,但底层的执行流程可能已经改变了。编译器还会尽量降低 Release 版本的体积,把没用的数据一律剔除,包括调试信息。
在最常用的向函数传递应用调用的情况下,Release版本引用仍然不占用空间
如对代码段
#include<iostream>
using namespace std;
void changea(int &b) {
b = 2;
cout << &b;
}
int main(void) {
int a = 1;
changea(a);
cout << &a;
}
我们反汇编一下
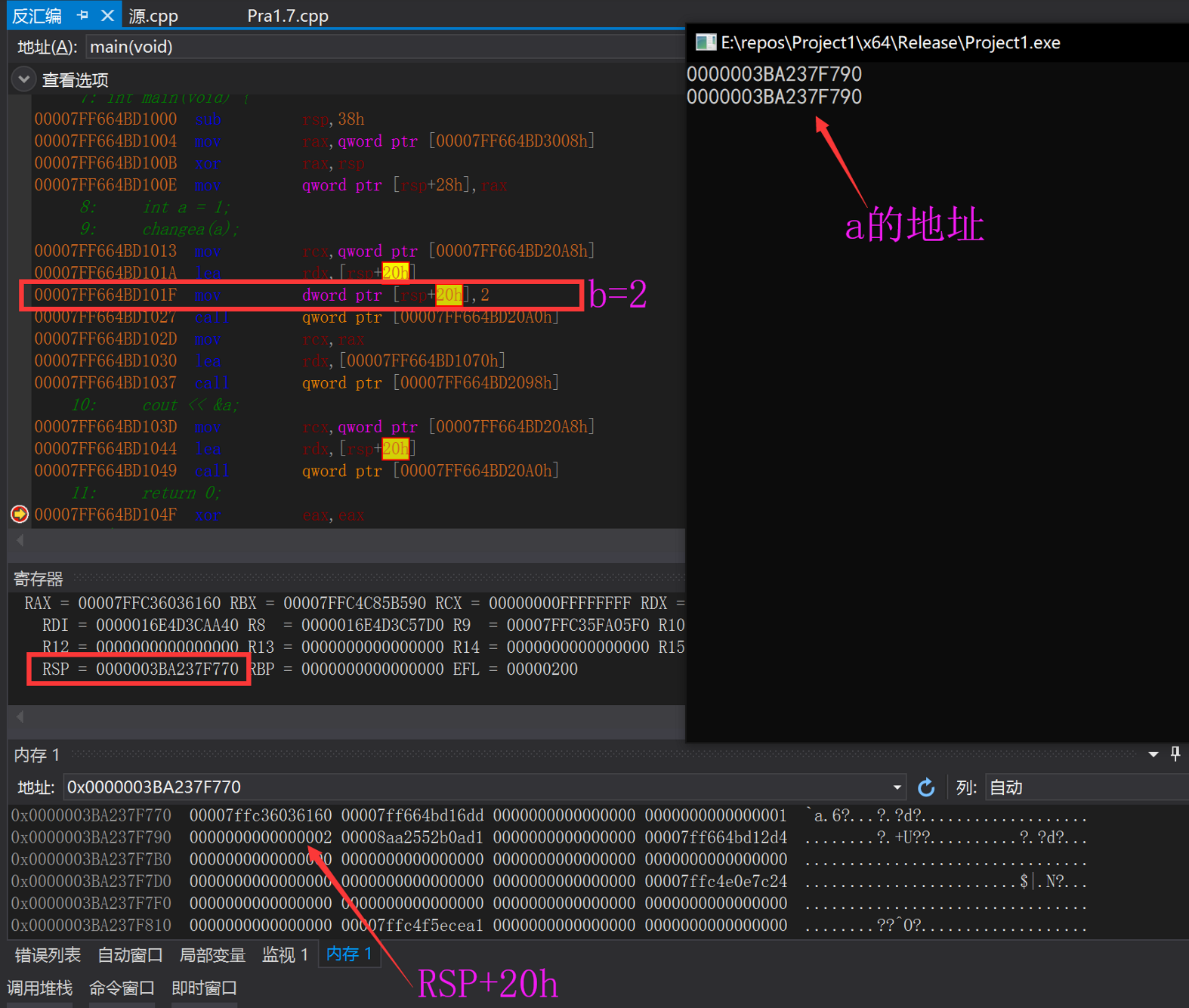
图中框中的指令就是b=2,我们可以看到b的地址被解析为了RSP+20H,我们计算完RSP+20H后发现,b的并不像debug版本中指向一个存储了a的地址的内存空间,而是直接等于a的地址,说明编译器对齐完成了优化
为什么能够进行优化呢,因为计算机的任何操作实质上都是对于内存的操作,当我们声明一个引用b,它的值无法更改,始终和a强绑定,所以在他的生命周期内都可以将其替换为符号表中a的地址,引用的使命是给使用高级语言的我们带来一种便利,它的使命已经完成。
总结:
至此,我们可以知道,在概念上引用不占用空间,引用在底层是使用指针来实现的,会申请一个指针大小的内存空间,并且在Release版本中会被优化掉,即不占用内存的空间,我们还了解了为什么要内存对齐,内存对齐存取粒度是怎么样影响性能的。
(以上内容为个人见解,由于个人知识和经验的限制难免有些错误,还望各位指正)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









