







 本文详细介绍了生成式对抗网络(GAN)的基本原理,包括其包含的生成器和判别器的神经网络结构,以及训练过程中的判别器和生成器的交互博弈。通过PyTorch实例展示了如何构建和训练GAN,最终生成逼真的图像。
本文详细介绍了生成式对抗网络(GAN)的基本原理,包括其包含的生成器和判别器的神经网络结构,以及训练过程中的判别器和生成器的交互博弈。通过PyTorch实例展示了如何构建和训练GAN,最终生成逼真的图像。
1、GAN是什么
GAN(生成式对抗网络,Generative Adversarial Networks)是一种深度学习模型,模型通过框架中两个模块(生成模型 Generative Model 和判别模型 Discriminative Model)的互相博弈学习,从而产生相当好的输出。原始GAN理论中,只要求G和D能拟合出相应生成和判别的函数即可,而并不要求他们必须都是神经网络,但是我们的实际应用中,一般都是采用深度神经网络作为G和D。
GAN论文:https://arxiv.org/abs/1406.2661
2、GAN的原理
@基本原理
GAN分为一个判别器(Discriminator,简称D)和一个生成器(Generator,简称G),简单的说,G和D就是两个多层感知机或卷积神经网络,它的基本思想,即为G和D的生成博弈过程。
G是一个生成图片的网络,它接收一个随机的噪声z,并且通过这个噪声生成图片,记做G(z)
D是一个进行判别的网络,它可以判别出一张图片是不是真实的。即给D输入真图片,它会将label赋值为1,输入假图片,就将label赋值为0
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D,使D认为自己生成的是真图片;而D的目标就是尽量将G生成的图片和真实的图片区别开来,这样G和D就形成了一个动态的博弈过程。
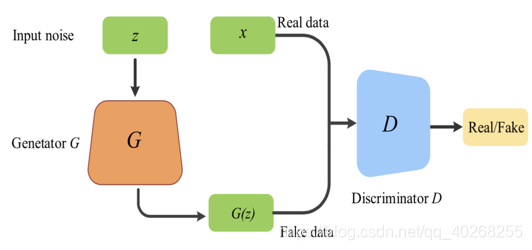
那么,最后博弈的结果是什么呢?在理想的状态下,G足以生成以假乱真的图片G(z),对于D来说,它难以判定G生成的图片究竟是不是真实的,因此有D(G(z))=0.5
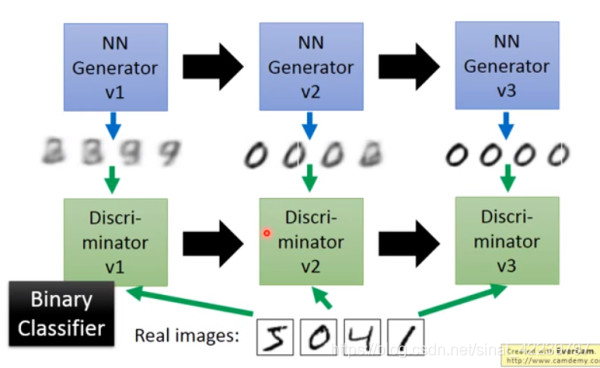
具体的流程如图中所示。
首先有一个一代的G,它生成的是一些很差的图片然后有一个一代的D,它能很准确的把G生成的假图片和真实的图片区分出来,打上标签0。其实这个D就是一个二分类器,对生成的图片输出0,而对真实的图片输出1。
接着经过训练,出现了二代的G,它能生成稍好一点的图片,能让一代的D认为他生成的是真图片。这时也出现了二代的D,它能识别哪些图片是G生成的,哪些是真实的图片。
以此类推,会有三代,四代。。。。n 代的 G(generator) 和D( discriminator),最后 D 无法分辨生成的图片和真实图片,这个网络就拟合了。
这两种网络具体是怎样的呢?
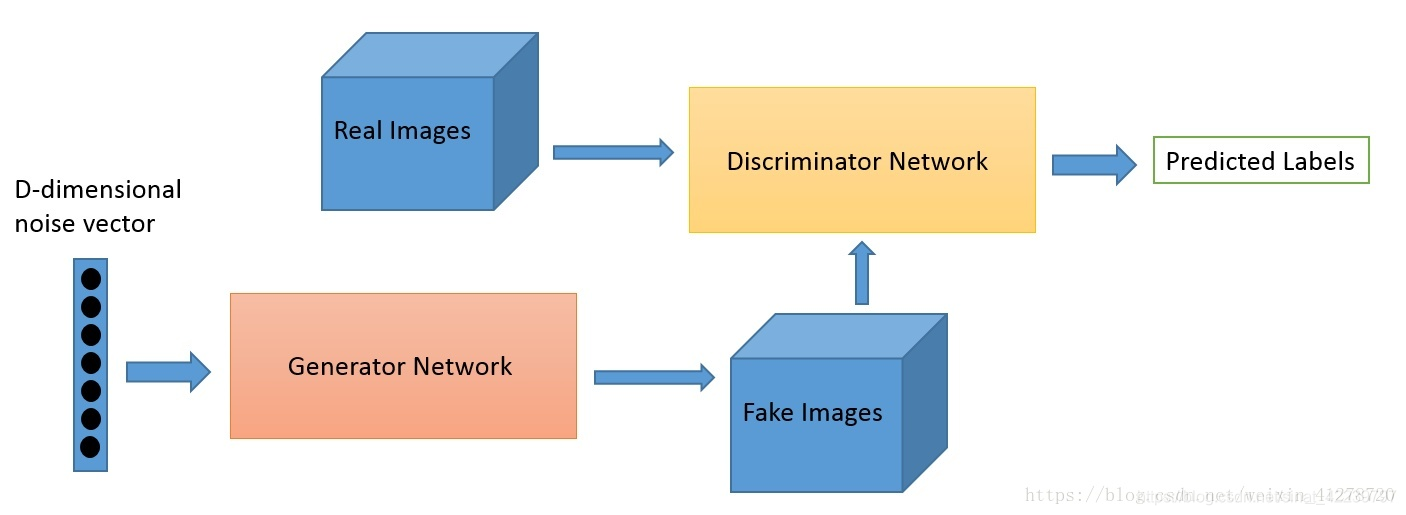
@Discriminator Network
首先要说的是对抗网络,因为这个网络相对较为简单。
对抗网络简单来说就是一个判断真假的判别器,解决的是一个二分类的问题。输入一张真的图片时我们希望它的输出结果是1,输入一张假的图片我们希望它能输出0。这其实和原图片的类别没有什么关系,无论原图片是什么类别的图片,我们都统称它为真图片,label为1;而生成的图片它是假的,label为0
我们对D训练的过程就是希望这个判别器能准确地判别出真的图片和假的图片,对于这个二分类问题可以有很多解决的方法,比如 logistic回归,深层网络,卷积神经网络,循环神经网络都可以。
# 判别网络
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256), nn.LeakyReLU(0.2),
nn.Linear(256, 1),
# sigmoid激活函数得到一个0到1之间的概率进行二分类
nn.Sigmoid())
def forward(self, x):
x = self.dis(x)
return x
@Generative Network
怎样才能生成一张假的图片呢?
首先给出一个简单高维的正态分布的噪声向量,如上图所示的D-dimensional noise vector,通过对它进行仿射变换,也就是将 xw+b 映射到一个更高的维度,然后将它重新排列成一个矩形,这样看起来就更加像一张图片,然后经过一系列的卷积、池化、激活操作,最后得到了一个与我们输入图片大小一模一样的噪声矩阵,这就是我们所说的假的图片。这个时候是怎样训练我们的生成器呢?其实通过判别器来得到结果,我们不断增大判别器识别生成图片为真的概率,在这一步我们不会更新判别器的参数,只会更新生成器的参数。
# 生成网络
class generator(nn.Module):
def __init__(self, input_size):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(True),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Linear(256, 784),
#Tanh激活函数是希望生成的假的图片数据分布能够在-1~1之间
nn.Tanh()
)
def forward(self, x):
x 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1427
1427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









