







- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rnFa-IeY93EpjVu0yzzjkw) 中的学习记录博客**
- **🍖 原作者:[K同学啊](https://mtyjkh.blog.youkuaiyun.com/)**
一:介绍
SE-Net 是由WMW团队发布。具有复杂度低,参数少和计算量小的优点。且SENet思路很简单,很容易扩展到已有网络结构如Inception 和 ResNet中。
已经有很多工作在空间维度上来提高网络的性能,如Inception等,而SENet将关注点放在了特征通道之间的关系上。其具体策略为:通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征,这又叫做特征重标定策略。具体的SE模块如下图所示:
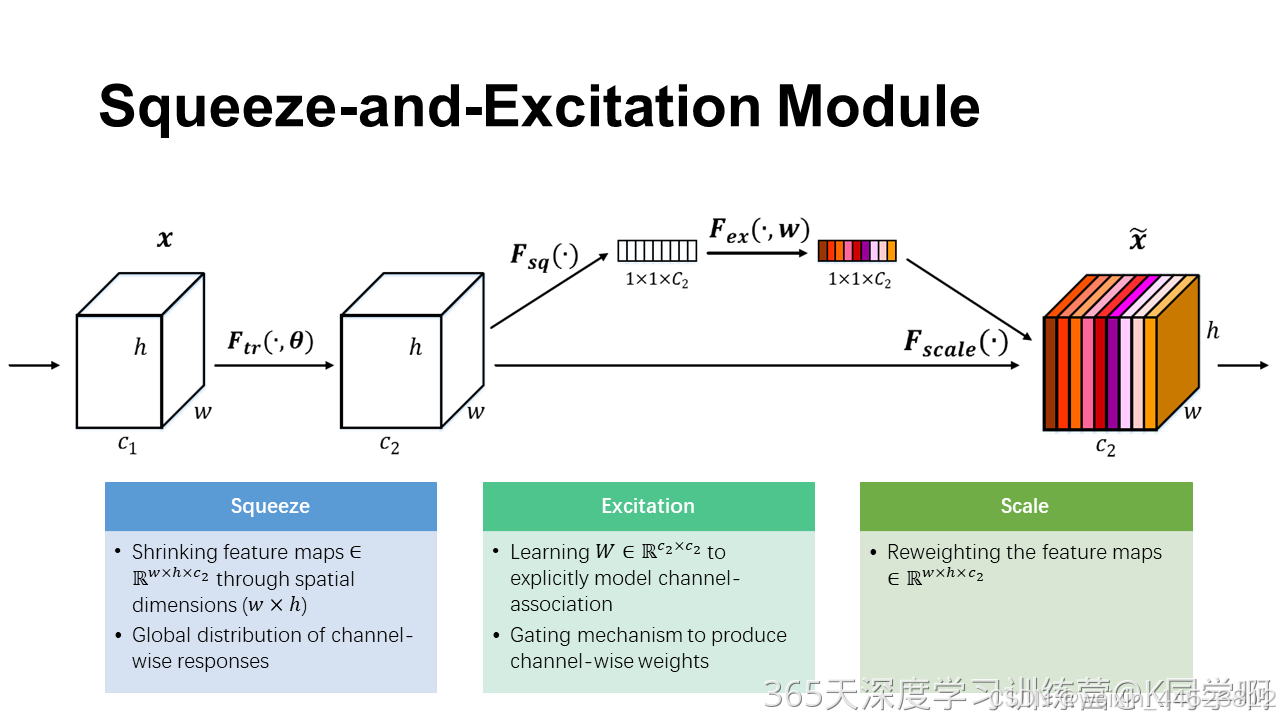
给定一个输入x,其特征通道数为c1,通过一系列卷积等一般变换 Ftr后得到一个特征通道数为c2的特征。与传统的卷积神经网络不同,我们需要通过下面三个操作来重标定前面得到的特征。
- 首先是Squeeze(压缩)操作:对每个通道的特征进行全局平均池化,将每个通道的二维特征图压缩成一个全局描述值。通过这个操作,SE模块能够获得每个通道的全局感受野,并生成一个通道的全局描述向量。数学公式为
,其中
表示输入特征图第c个通道的值,H和W是特征图的高度和宽度。
- 得到了全局描述特征后,我们进行Excitation操作来抓取特征通道之间的关系,这里采用包含两个全连接层的bottleneck结构,即中间小两头大的结构:其中第一个全连接层起到降维的作用,并通过ReLU激活,第二个全连接层用来将其恢复至原始的维度。进行Excitation操作的最终目的是为了每个特征通道生成权重,即学习到的各个通道的激活值。
- 最后一个是Scale操作,我们将Excitation的输出的权重看作是经过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定,从而使得模型对各个通道的特征更有辨别能力,这类似于attention机制。
二:SE模块应用分析
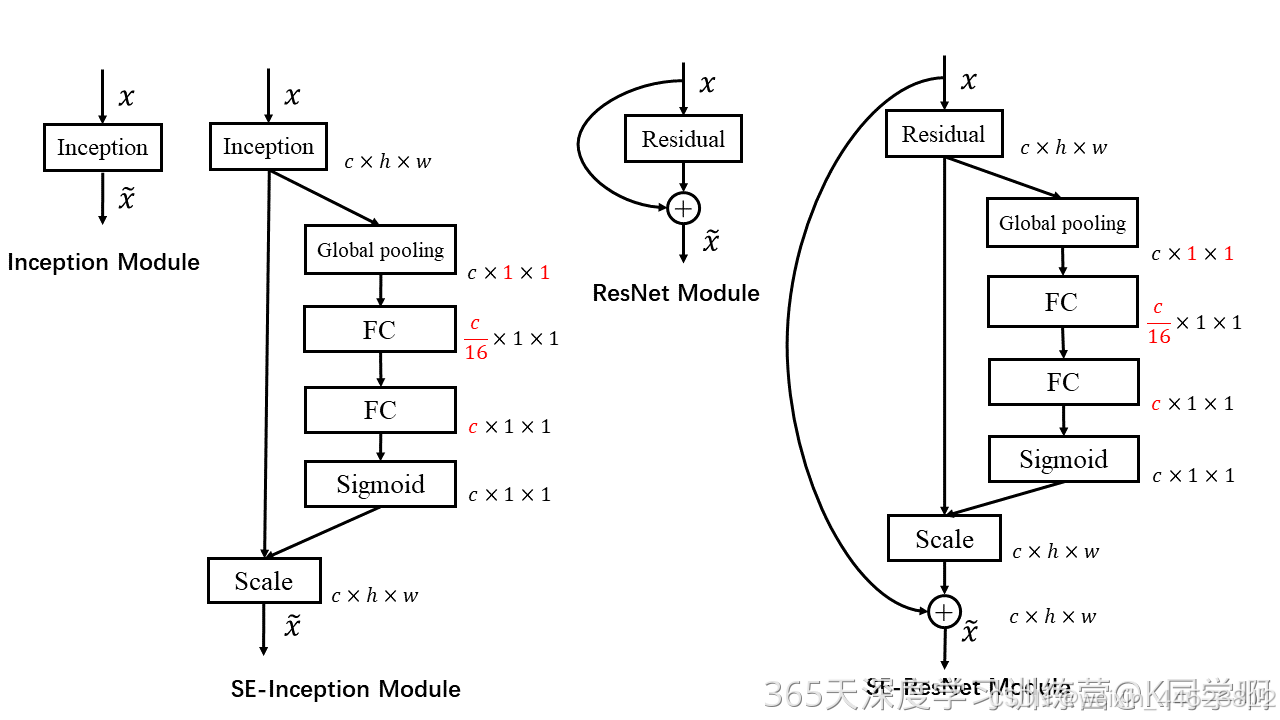
SE模块的灵活性在于它可以直接应用现有的网络结构中。以Inception和Resnet为例,我们只需要在Inception模块或Residual模块后添加一个SE模块即可。具体如下图所示:
三:前期准备
1.设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
import torch.nn.functional as F
from torchvision import transforms,datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings('ignore')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
2.导入数据
data_dir = "/content/drive/MyDrive/第4周"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片综数:",image_count)
data_path = list(data_dir.glob('*'))
class_names = [str(path).split("/")[-1] for path in data_path]
print(class_names)
3.查看数据
import matplotlib.pyplot as plt
import numpy as np
import random
from PIL import Image
plt.figure(figsize=(20, 4))
data_paths = list(data_dir.glob('*/*.jpg'))
for n in range(20):
ax = plt.subplot(2, 10, n + 1)
image_path = random.choice(data_paths)
image = Image.open(str(image_path))
plt.axis('off')
plt.title(image_path.parts[-2])
plt.imshow(np.asarray(image))
plt.tight_layout()
plt.show()
四:数据预处理
1.图片预处理
train_transforms = transforms.Compose([
transforms.Resize([224,224]), #将输入图片resize成统一尺寸
transforms.ToTensor(), #将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( #标准化处理-->转换为标准正态分布(高斯分布),使模型更容易收敛
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]) #mean和std从数据中随机抽样计算得到
])
test_transforms = transforms.Compose([
transforms.Resize([224,224]), #将输入图片resize成统一尺寸
transforms.ToTensor(), #将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( #标准化处理-->转换为标准正态分布(高斯分布),使模型更容易收敛
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]) #mean和std从数据中随机抽样计算得到
])
total_data = datasets.ImageFolder(root = data_dir,transform = train_transforms)
total_data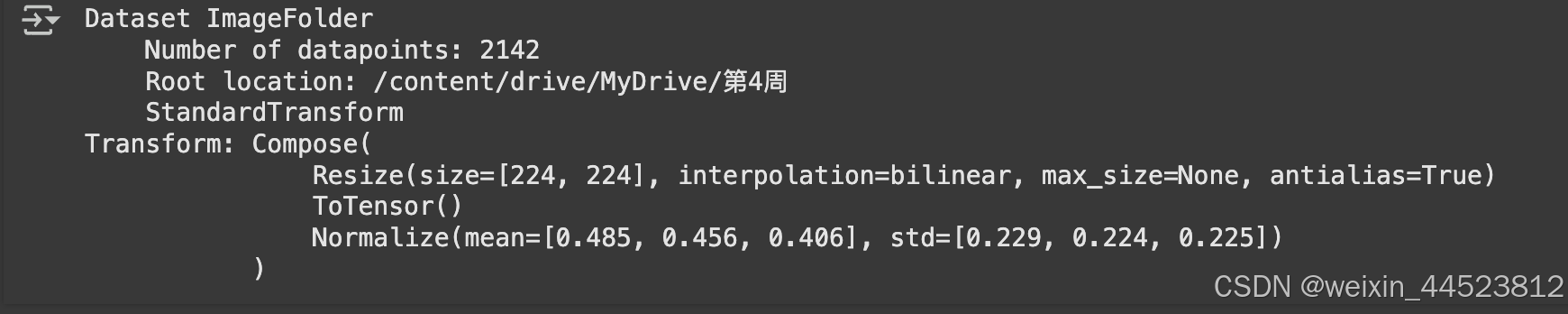
2.数据映射
total_data.class_to_idx
3.划分数据集
train_size = int(0.8*len(total_data))
test_size = len(total_data)-train_size
train_datasize , test_datasize = torch.utils.data.random_split(total_data,[train_size,test_size])
train_datasize,test_datasize
4.加载数据集
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_datasize,batch_size,shuffle = True)
test_dl = torch.utils.data.DataLoader(test_datasize,batch_size,shuffle=True)for x, y in test_dl:
print(x.shape, y.shape)
break
五:手动搭建DenseNet+SE-Net模型
1.搭建SE模块
import torch
import torch.nn as nn
class SEBlock(nn.Module):
def __init__(self, in_channels, reduction=16):
"""
Args:
in_channels (int): 输入特征图的通道数
reduction (int): 通道压缩比,默认为16
"""
super(SEBlock, self).__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
batch_size, channels, _, _ = x.size()
# Squeeze: 全局平均池化
y = self.global_avg_pool(x).view(batch_size, channels) # (B, C, 1, 1) -> (B, C)
# Excitation: 全连接层生成通道权重
y = self.fc(y).view(batch_size, channels, 1, 1) # (B, C) -> (B, C, 1, 1)
# Scale: 对输入特征图进行加权
return x * y.expand_as(x)2.搭建DenseNet-SE
class DenseLayer(nn.Module):
def __init__(self, in_channels, growth_rate, reduction=16):
super(DenseLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = nn.Conv2d(in_channels, 4 * growth_rate, kernel_size=1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(4 * growth_rate)
self.conv2 = nn.Conv2d(4 * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)
self.se = SEBlock(growth_rate, reduction)
def forward(self, x):
out = self.bn1(x)
out = F.relu(out)
out = self.conv1(out)
out = self.bn2(out)
out = F.relu(out)
out = self.conv2(out)
# Apply SE Block
out = self.se(out)
# Concatenate input and output
return torch.cat([x, out], dim=1)
class DenseBlock(nn.Module):
def __init__(self, num_layers, in_channels, growth_rate, reduction=16):
super(DenseBlock, self).__init__()
layers = []
for i in range(num_layers):
layers.append(DenseLayer(in_channels + i * growth_rate, growth_rate, reduction))
self.block = nn.Sequential(*layers)
def forward(self, x):
return self.block(x)
class TransitionLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super(TransitionLayer, self).__init__()
self.bn = nn.BatchNorm2d(in_channels)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(2, stride=2)
def forward(self, x):
x = self.bn(x)
x = F.relu(x)
x = self.conv(x)
x = self.pool(x)
return x
class SEDenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, num_classes=1000):
super(SEDenseNet, self).__init__()
# Initial Convolution
self.conv1 = nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(num_init_features)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Dense Blocks and Transition Layers
num_features = num_init_features
self.blocks = nn.ModuleList()
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, num_features, growth_rate)
self.blocks.append(block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1: # Add Transition Layer between Dense Blocks
trans = TransitionLayer(num_features, num_features // 2)
self.blocks.append(trans)
num_features = num_features // 2
# Final BatchNorm
self.bn_final = nn.BatchNorm2d(num_features)
# Classification Layer
self.fc = nn.Linear(num_features, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.pool1(x)
for block in self.blocks:
x = block(x)
x = self.bn_final(x)
x = F.relu(x)
x = F.adaptive_avg_pool2d(x, (1, 1)).view(x.size(0), -1)
x = self.fc(x)
return xmodel = SEDenseNet().to(device)
modelSEDenseNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool1): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(blocks): ModuleList(
(0): DenseBlock(
(block): Sequential(
(0): DenseLayer(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(se): SEBlock(
(global_avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=32, out_features=2, bias=False)
(1): ReLU(inplace=True)
(2): Linear(in_features=2, out_features=32, bias=False)
(3): Sigmoid()
)
)
)
(1): DenseLayer(
(bn1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(se): SEBlock(
(global_avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=32, out_features=2, bias=False)
(1): ReLU(inplace=True)
(2): Linear(in_features=2, out_features=32, bias=False)
(3): Sigmoid()
)
)
)
(2): DenseLayer(
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(se): SEBlock(
(global_avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=32, out_features=2, bias=False)
(1): ReLU(inplace=True)
(2): Linear(in_features=2, out_features=32, bias=False)
(3): Sigmoid()
)
)
)
(3): DenseLayer(
(bn1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









