







SENet学习笔记
Abstract
-
CNN的核心构件是卷积算子(卷积核),它能使网络融合每一层局部感受野上的空间和通道信息来提取特征
-
本文针对通道关系,提出了“Squeeze and Excitation” 块,通过建模通道之间的相互依赖关系,自适应的校准通道方面的特征
we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels.
-
在ILSVRC2017分类竞赛中排名第一
Introduction
-
显式地建模特征通道之间的相互依赖关系
-
通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
-
SE block如下图,对于一个输入 X X X,其通道数为 C ′ C^{'} C′,经过卷积等一系列变换后得到一个通道数为 C C C的特征 U U U
- 先Squeeze,对通道间的关系进行建模
- 然后进行Excitation操作(两层全连接层),最后使用sigmoid限制到[0,1]内
- 最后将Excitation操作生成的权值乘以
U
U
U的相对应的通道上作为下一层的输入

-
略微增加模型的复杂性和计算负担
-
可以将现有网络中的层用SE block替代
Related Work
- VGG和Inception表明增加网络的深度可以提高网络的学习能力
- ResNet表明通过使用跳跃连接可以构建更深更强的网络
- 分组卷积和多分支卷积用来 减少模型和计算复杂度
- 通道关系可以被表述为具有局部感受野的实例不可知的函数的组合(即不同通道间的关系)
- Attention and gating mechanisms(注意力和门控机制)
SQUEEZE-AND-EXCITATION BLOCKS
- 下图为SE block的结构,其中 F t r F_{tr} Ftr是卷积操作, F s q F_{sq} Fsq表示Squeeze操作, F e x F_{ex} Fex表示Excitation操作, F s c a l e F_{scale} Fscale表示加权操作

- 用 V = [ v 1 , v 2 , v 3 . . . , v C ] V=[v_1,v_2,v_3...,v_C] V=[v1,v2,v3...,vC]表示一组卷积核,其中 v c v_c vc表示第 c c c个卷积核的参数, U = [ u 1 , u 2 , . . . . , u C ] U=[u_1,u_2,....,u_C] U=[u1,u2,....,uC]代表经过卷积操作的输出, u c u_c uc表示输入 X X X经过卷积核为 v c v_c vc的卷积操作之后的输出(即 U U U的一个通道), C ′ C{'} C′表示输入特征图 X X X的通道数,即卷积核的通道数,公式(1)表示常规的卷积操作,为了方便表示省略了偏置项

- 每一个卷积核都有局部的感受野,因此卷积操作的每个输出 U U U都不能利用感受野之外的上下文信息,为了缓解这个问题,提出了Squeeze操作,通过全局平均池化将全局空间信息压缩到一个channel descriptor(通道描述符)中,公式(2)表示Squeeze操作 F s q F_{sq} Fsq, z c z_c zc表示 z z z中的第 c c c个元素,通过 U U U中的第 c c c个通道全局平均池化得到(也可以采用其他策略)

-
为了利用Squeeze之后的信息,进行第二个操作Excitation( F e x F_{ex} Fex),该操作的目的旨在学习到通道间的相互关系,需满足两个条件:(1)灵活,能够学习到通道间的非线性关系;(2)学习非互斥关系,确保允许强调多个通道,而不是one-hot( 一位有效编码,这里表示只强调或保留一个通道 )
-
公式(3)表示Excitation操作 F e x F_{ex} Fex, δ \delta δ表示ReLU函数,
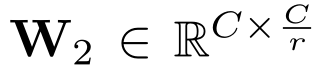
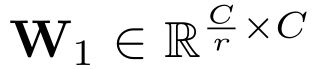
分别表示两个全连接层的参数, r r r表示缩放率,即第一个全连接把 C C C个通道压缩成了 C r \frac{C}{r} rC个通道来降低计算量(后面跟了ReLU),第二个全连接再恢复回C个通道(后面跟了Sigmoid(0-1之间))

-
公式(4)表示加权操作 F s c a l e F_{scale} Fscale, X ~ = [ x 1 ~ , x 2 ~ , x 3 ~ , . . . x C ~ ] 和 F s c a l e ( u c , s c ) \widetilde{X} = [\widetilde{x_1},\widetilde{x_2}, \widetilde{x_3},...\widetilde{x_C}]和F_{scale}(u_c,s_c) X =[x1 ,x2 ,x3 ,...xC ]和Fscale(uc,sc)表示标量(权值) s c s_c sc和特征图 u c u_c uc相乘

实例
-
SE Block的灵活性意味着它可以直接应用于标准卷积之外的变换。
-
fig.2表示将SE Block应用于Inception

- fig.3表示将SE Block应用于ResNet

MODEL AND COMPUTATIONAL COMPLEXITY
- 以ResNet50为例,对于224x224的输入图像,ResNet50在一次正向传播中需要大约3.86GFLOPs(浮点运算次数),当把缩放率 r r r设置为16时,SE-ResNet50一次正向传播中需要大约3.87GFLOPs,会造成很少的额外计算,但是SE-ResNet50的精度超过了ResNet50,更接近ResNet-101的精度(7.58GFLOPs)
- 为了更好地部署,计算了单次CPU推理时间
- ResNet50 164ms
- SE-ResNet50 167ms
- 公式(5)表示额外引入的参数量, r r r表示缩放率, S S S表示Block的集合(一个S中若干个Block),表示输出的通道数, N s N_s Ns表示 S S S中Block的个数(比如残差块的个数)(全连接层中的偏置项忽略不计)

EXPERIMENTS
-
Network depth
-
在ImageNet 2012上将SE-ResNet与不同深度的ResNet架构进行比较,在计算复杂度增加极小的情况下,SE块在不同深度都能提高性能。(括号里是对比前者的提高指标)

- 训练曲线,可以看到增加了SE Block后,整个优化过程得到了改善

- 轻量化网络,略微增加计算量和参数量,精度得到了提升

- 不同数据集上的表现

ABLATION STUDY(消融研究)
Reduction ratio
-
设置r = 16可以在精度和复杂性之间实现良好的平衡。
-
在实践中,在整个网络中使用相同的缩放率率可能不是最佳的(由于不同层执行不同的角色),因此通过调整比率以满足给定基础架构的需求,可以实现进一步的改进。

Squeeze Operator
- 平均池化优于最大池化

Excitation Operator
- 不同的激活函数影响很大

Different stages
- 在ResNet50的各个stage应用SE Block都有效果提升

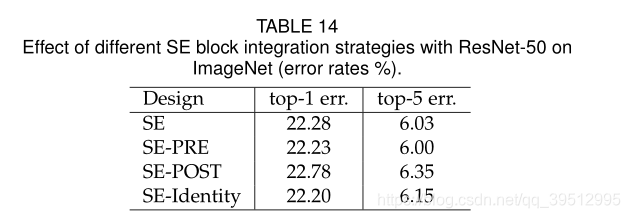
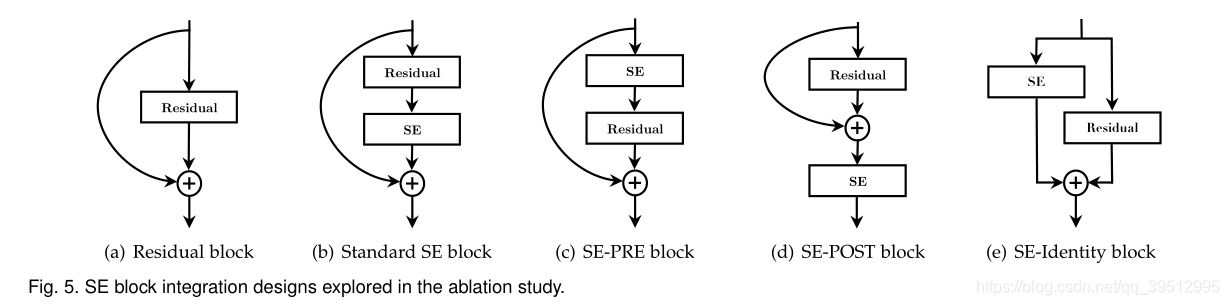
Integration strategy
ROLE OF SE BLOCKS
Effect of Squeeze
- NoSqueeze:移除pooling操作,将两个全连接层替换成对应大小的1x1卷积(参数量相同)

Role of Excitation

CONCLUSION
- SE block取得了很好的效果
- SE block可以用于其他任务,比如网络剪枝
问题
- 两个激活函数的区别?

















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









