




 本文探讨了为什么最小二乘法在优化中如此强大,尤其是在处理不同类型的噪声(如高斯、拉普拉斯、均匀分布)时。尽管最小二乘法源于高斯噪声下的最大似然估计,但即使噪声分布不遵循高斯假设,最小二乘法仍能提供良好的优化近似。文章还介绍了凸优化的概念,包括洛文斯坦-约翰椭圆和KKT条件,以及最小体积椭球体如何近似任意凸集。
本文探讨了为什么最小二乘法在优化中如此强大,尤其是在处理不同类型的噪声(如高斯、拉普拉斯、均匀分布)时。尽管最小二乘法源于高斯噪声下的最大似然估计,但即使噪声分布不遵循高斯假设,最小二乘法仍能提供良好的优化近似。文章还介绍了凸优化的概念,包括洛文斯坦-约翰椭圆和KKT条件,以及最小体积椭球体如何近似任意凸集。
Why least squares so powerful?
考虑到翻译会有不严谨的地方,很多地方我直接使用英语描述。
1. Residual Distribution

- 通常,我们使用Generalized Gauss-Markov假设。假设输出变量的残差都是zero-mean,服从高斯分布,同时他们之间的关系使用covariance matrix表示(对角线是变量的variance,非对角线则表示了不同变量之间的纠缠关系)。
- 但是明显的是,这样的假设并不一定是正确的。我们面临的可能是非高斯的分布。
在下面我们会看到:
- 对高斯误差的优化,其实是最小二乘优化。
- 对非高斯误差的优化,也可以使用最小二乘获得很好的近似。
2. 不同噪音下线性系统的ML
下面我们分别考虑不同的噪音影响下的,Maximum likelihood estimation的不同形式。
我们列举了高斯噪音,拉普拉斯噪音以及均匀分布噪音。
考虑高斯噪音下的线性系统:
linear measurement model:
matrix form:
Y
=
A
X
+
ν
Y = AX + \nu
Y=AX+ν
component form:
y
i
=
a
i
T
x
+
ν
i
y_{i} = a_{i}^{T}x + \nu_{i}
yi=aiTx+νi
2.1 Maximum likelihood Esimation
对系统,我们优化Maximum log likelihood :
m a x i m i z e ( o v e r x ) log p x ( y ) maximize \ (over \ x) \ \ \log p_{x}(y) maximize (over x) logpx(y)
m a x i m i z e ( o v e r x ) l ( x ) = ∑ i = 1 m log p ( y i − a i T x ) maximize \ (over \ x) \ \ l(x) = \sum_{i=1}^{m} \log p(y_{i} - a_{i}^{T}x) maximize (over x) l(x)=i=1∑mlogp(yi−aiTx)
这实际上是一个对penality的优化,penality则是噪音的分布。
2.2 Gaussian noise
考虑高斯噪音 N ( 0 , σ 2 ) \mathcal{N}(0, \sigma^{2}) N(0,σ2):
p ( z ) = ( 2 π σ 2 ) − 1 / 2 exp ( − z 2 / ( 2 σ 2 ) ) p(z) = (2 \pi \sigma^{2})^{-1/2}\exp (- z^{2}/(2\sigma^{2})) p(z)=(2πσ2)−1/2exp(−z2/(2σ2))
那么我们的优化目标函数就变为了:
l ( x ) = − m 2 log ( 2 π σ 2 ) − 1 2 σ 2 ∑ i = 1 m ( a i T x − y i ) 2 l(x) = -\frac{m}{2}\log(2 \pi \sigma^{2})-\frac{1}{2 \sigma^{2}}\sum_{i = 1}^{m} (a_{i}^{T}x-y_{i})^{2} l(x)=−2mlog(2πσ2)−2σ21i=1∑m(aiTx−yi)2
第一项与优化参数x无关,我们只需要考虑上面的第二项,而它则是一个
l
2
\mathcal{l}_{2}
l2范数:最小二乘(least square)。
但是其他的噪音假设会得到什么样的结果呢?我们来考量几个其他的假设。
2.3 Laplacian noise
考虑拉普拉斯噪音:
p ( z ) = 1 2 a exp ( − ∣ z ∣ a ) p(z) = \frac{1}{2a} \exp(- \frac{|z|}{a}) p(z)=2a1exp(−a∣z∣)
l ( x ) = − m log ( 2 a ) − 1 a ∑ i = 1 m ∣ a i T x − y i ∣ l(x) = -m\log(2a) - \frac{1}{a}\sum_{i= 1}^{m}|a_{i}^{T}x-y_{i}| l(x)=−mlog(2a)−a1i=1∑m∣aiTx−yi∣
ML的优化其实是对 l 1 \mathcal{l}_{1} l1范数的优化。
2.4 Unifrom noise
考虑误差均匀分布在 [ − a , a ] [-a, a] [−a,a]:
l ( x ) = { − m log ( 2 a ) ∣ a i T x − y i ∣ ≤ a , i = 1 , . . , m − inf o t h e r w i s e l(x) = \begin{cases}-m\log(2a) \quad \ \ & |a_{i}^{T}x-y_{i}| \le a, \ i = 1, ..,m\\ -\inf \quad \ \ &otherwise \end{cases} l(x)={−mlog(2a) −inf ∣aiTx−yi∣≤a, i=1,..,motherwise
2.5 Summary
- Least-squares is exactly maximum likelihood estimation under the assumption that the noises are gaussian!
- 但是其他的噪音假设,会导致不同的优化目标函数的表达式。
- 那我们还能不能(几乎)“无脑”得使用最小二乘优化呢?或者说最小二乘是不是比我们想象中得更强大呢?
下面会介绍凸包的一些定理,以展现最小二乘的强大。
3. convex optimization
3.1 convex set
在这里不需要凸优化的过多概念,只需要知道凸函数就足够继续了。
Definition:
for
x
1
,
x
2
∈
A
x_{1}, x_{2} \in A
x1,x2∈A, we say
A
A
A is a convex set if and only if the following holds for any
θ
∈
[
0
,
1
]
\theta \in [0,1]
θ∈[0,1]:
θ
x
1
+
(
1
−
θ
)
x
2
∈
A
\theta x_{1} + (1- \theta)x_{2} \in A
θx1+(1−θ)x2∈A
3.2 Minimum volume ellipsoid around a set
Lowner-John ellipsoid for a set C minimum volume ellipsoid E \mathcal{E} E such that C ⊆ E C \subseteq \mathcal{E} C⊆E
我们考虑一个特殊的例子来证明:



优化问题可以写成:
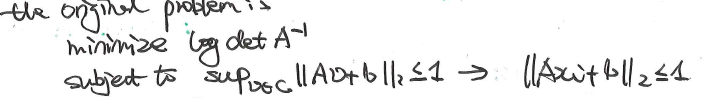
3.3 rewrite constraints
通过一个简单的变化,我们重写原本的约束函数:
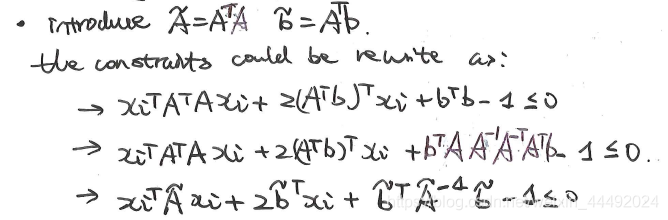
3.4 KKT condition
这个是和凸优化duality相关的特性。具体的话,可以参考convex optimization的课程和教材。
简单来说的话:
- 如果一个凸优化问题有strong dualtiy。
- 那么我们可以通过求解dual problem,来求解原本的问题。
- strong duality的条件之一是KKT condition。
- KKT condition由四个类组成(下面是当前问题的KKT condition)
我们可以(不正式地)理解为由于我们问题的凸函数特征,下面的几个条件是一定满足的。

上面的几个条件的表达明显很复杂,不够幸运的是,我们可以通过一些线性的坐标系变化得到简答的表达式。坐标系变换的例子图示如下:

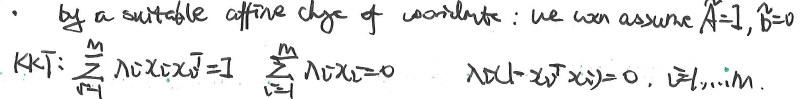
另外,通过上面的条件,我们可以得到:
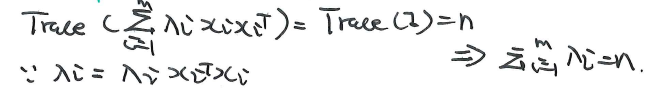
3.5 1/n scale the ellipsoid
我们考虑缩放LJ椭圆,使用一个缩放尺度1/n。然后我们考虑这个新的缩小的椭圆内的元素:

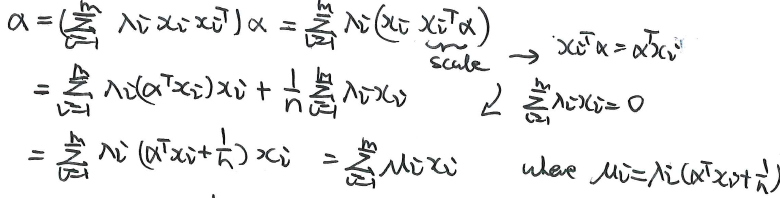
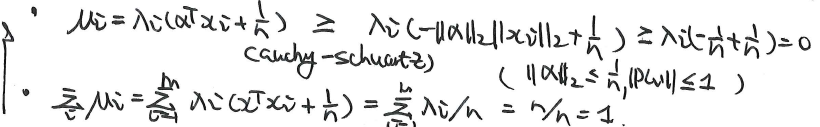

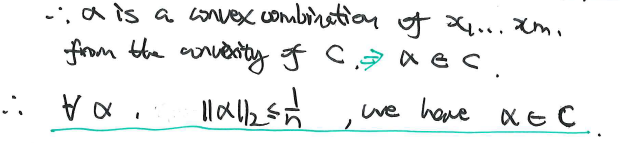
在这里我们证明了,任意新的缩小椭圆内的元素,都属于原本的凸集C。也就是说,这个缩小的椭圆是严格在C集合内部的。

上图来自《convex optimization》page 412。
3.6 for symmetric set

在C是对称集合的情况下,这个缩放因子还能进一步被控制为
n
\sqrt n
n。
4. 其他范数
下文来自《convex optimization》page 412-413。


对于这个结论,我们可以有以下几个非常好的描述:
-
Ellipsoides are universal approximations of convex sets.
-
Any norm on R n \mathcal{R}^{n} Rn,can be approximated by a quadratic norm, with a factor of n \sqrt n n
-
Any sysmetric convex set can be approximated by an ellipsoid within a factor n \sqrt n n
-
LJ“椭圆”是所有对称凸集的在scale为 n \sqrt n n下的近似。
-
L2是其他所有模在 n \sqrt n n下的近似。
总得来说:
- 如果我们假设高斯噪音,那么最小二乘是最合适的范数选择。
- 但是哪怕假设不成立,无论实际是什么样的误差,应该选取什么样的范数。最小二乘都可以取得一个很好的近似。
也就是说,当然高斯假设下用最小二乘是最好的。但是无论你是什么噪音模型,使用最小二乘都可以得到很好的结果!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









