







 这篇博客介绍了STL中的关联容器,包括set、map、multiset、multimap、unordered_set和unordered_map。关联容器存储键值对,其中set和map基于红黑树,查询效率为O(logN),元素自动排序且键唯一。unordered_set和unordered_map使用哈希表,查找、插入、删除近似O(1),但无序。文章还讨论了哈希冲突的解决方法以及有序和无序容器的优缺点和适用场景。
这篇博客介绍了STL中的关联容器,包括set、map、multiset、multimap、unordered_set和unordered_map。关联容器存储键值对,其中set和map基于红黑树,查询效率为O(logN),元素自动排序且键唯一。unordered_set和unordered_map使用哈希表,查找、插入、删除近似O(1),但无序。文章还讨论了哈希冲突的解决方法以及有序和无序容器的优缺点和适用场景。
STL模板库包括了容器、算法、迭代器、仿函数、适配器、分配器。
主要谈谈容器
STL中的容器有序列容器和关联容器,容器适配器等
1)序列容器(以线性序列的方式存储元素,没对元素进行排序,元素的顺序和存储它们的顺序相同)
主要包括 vector string list deque
2)关联容器(存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高)
主要包括 set map multiset multimap
3)适配容器 就是由基本的容器适配(改造)出来的那些容器
主要包括 queue stack priority_queue
这边主要谈谈关联容器
Set和Map底层都为红黑树,查询效率为O(logN),一个set和map关键字(key)必须唯一,但值可以不同(对于map,因为set键和值相同),自动排序。
拓展下红黑树可以认为是平衡的二叉查找树,只要不平衡就会调整,不会出现二叉查找树瘸脚导致效率低下的情况。
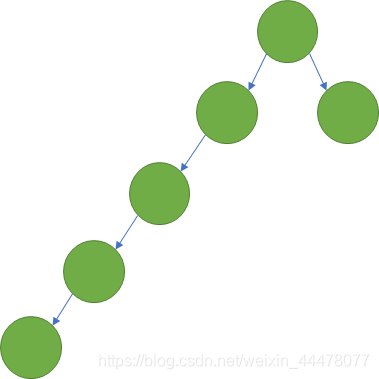
图为:二叉查找树瘸脚情况
set的特性是,所有元素都会根据元素的键值自动排序,set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值。set不允许两个元素有相同的键值。
代码:
set<int>s;
s.insert(7);
s.insert(2);
s.insert(3);
s.insert(4);
s.insert(1);
s.insert(6);
s.insert(5);
for (auto x:s)
{
cout << x << endl;
}
这个测试说明了set容器能够自动排序(默认从小到大),set无法使用[ ],输出得借助迭代器
for (it = s.begin(); it != s.end();it++)
{
cout << *it << endl;
}
插入两个相同的键
s.insert(7);
s.insert(7);
第二个不会起作用,在set和map中只允许一个键
Map中元素的键是唯一的,如果键已经存在,用insert插入相同的键的话不起作用,而如果用数组[key]=value的形式则改变其中的值
创建map的代码:
map<int, string>m;
m.insert(pair<int, string>(10, "bbb"));//10为键, bbb为值
m.insert(make_pair(11, "ccc"));
m.insert({ 9, "aaa" });
m[12] = "ddd";//12为键,ddd为值
for (auto x:m)
{
cout << x.first <<": "<< x.second<<endl;
}
和set一样,如果插入相同的键值,后插入的不起作用,例如:
m.insert(pair<int, string>(10, "bbb"));//10为键, bbb为值
m.insert(make_pair(10, "ccc"));
这两个的键都为10,下面的不起作用;
但如果用[key]=value的方式则可以改变键值对的值
m.insert(pair<int, string>(10, "bbb"));//10为键, bbb为值
m[10] = "ddd";//10为键,ddd为值
这样得到的值将为”ddd”
同样输出借用迭代器
map<int, string>m;
map<int, string>::iterator it;
m.insert(pair<int, string>(10, "bbb"));//10为键, bbb为值
m.insert(make_pair(10, "ccc"));
m.insert({ 9, "aaa" });
m[10] = "ddd";//10为键,ddd为值
for (it = m.begin(); it != m.end();it++)
{
cout << it->first << ": " << it->second << endl;
}


















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











