







CUDA 混合代码的编译与传统 C/C++ 代码编译分析
CUDA 混合代码的编译与传统 C/C++ 代码编译的主要不同在于,CUDA 编程涉及主机端代码(运行在 CPU 上)和设备端代码(运行在 GPU 上)。编译器需要处理两种不同的体系结构——主机(通常是 CPU)和设备(通常是 GPU),因此编译流程会有所不同。
分开编译(Separate Compilation)
分开编译是编译 CUDA 混合模式源代码的一种方法,它是由 NVIDIA 的 nvcc 编译器采用的方式。分开编译的流程如下:
-
源代码拆分:编译器将混合模式源代码通过一个名为“拆分器”(splitter)的组件分解成主机端和设备端代码。主机端代码是常规的 C/C++ 代码,设备端代码是 CUDA 核函数代码。
-
主机端和设备端代码的编译:
- 主机端代码通过标准的 C/C++ 编译器(如 GCC)进行编译。
- 设备端代码由 CUDA 编译器(nvcc)进行编译,最终生成 PTX(并行线程执行)汇编代码,这是一个针对 NVIDIA GPU 架构的中间表示。
-
合并二进制文件:编译后的主机端和设备端代码会分别生成目标文件,最后将这两个文件合并成一个二进制文件,这个文件通常被称为 fabinary 文件。这个文件包含了既可以在 CPU 上执行的主机代码,也可以在 GPU 上执行的设备代码。
双模式编译(Dual-Mode Compilation)
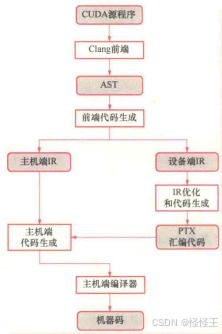
双模式编译是另一种用于编译 CUDA 混合模式源代码的方法,这种方法相较于分开编译的方式有以下几个优点:
-
避免中间源文件转换:双模式编译的关键是它不需要生成两个中间源文件(主机端和设备端源代码),而是直接为主机和设备生成 LLVM IR(中间表示)。LLVM IR 是一种与平台无关的中间表示,它能够支持各种优化,并且能够通过不同的后端生成目标机器代码。
-
编译过程:
- 首先,Clang 的 CUDA 前端生成源代码的 抽象语法树(AST)。
- 然后,Clang 根据主机端和设备端的需求分别处理 AST,生成适用于主机和设备的 LLVM IR。
- 设备端的 LLVM IR 会通过设备代码生成器转化为 PTX 汇编代码。
- PTX 汇编代码会通过主机代码生成器注入到主机代码中,以字符串形式嵌入到主机端代码中。
-
运行时编译:在运行时,CUDA 驱动程序会调用 JIT(即时编译器) 将 PTX 汇编代码编译为 GPU 可执行的机器代码。这使得设备端代码能够在运行时根据硬件架构进行优化和编译,从而提高执行效率。
分析与对比
-
灵活性:双模式编译不需要拆分源文件,直接生成中间代码并进行优化,能够更好地支持不同平台的代码生成和优化,适应性更强,尤其是在不同架构或平台上运行时。
-
效率:分开编译通过生成中间文件后再合并的方式,可能涉及更多的文件操作和中间转换,但它的过程相对简单,适合一些简单的 CUDA 应用。在某些情况下,分开编译的效率可能不如双模式编译,尤其是在对代码进行频繁修改时。
-
优化:双模式编译通过使用 LLVM IR 和 JIT 编译,能够实现更细粒度的优化。LLVM IR 可以在编译过程中进行多种优化(如跨平台优化、特定架构的优化等),并且 JIT 编译可以根据运行时的硬件信息进行优化,确保最终代码的高效性。
-
工具支持:双模式编译需要更强的工具支持,如 Clang 和 LLVM,可能对开发者的环境要求更高,但它提供了更先进的优化和编译特性。
总结
- 分开编译适合简单的 CUDA 应用,易于理解和实现,但可能不如双模式编译灵活,尤其是在需要进行复杂优化或跨平台支持时。
- 双模式编译则通过生成 LLVM IR 和 JIT 编译,能够提供更高的优化效率,尤其适用于需要高性能或支持多个平台的 CUDA 项目。
这两种方法各有优势,开发者可以根据具体需求选择适合的编译方式。

















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









