






在医学影像分割中,为了可视化分割效果,我们可以将不同网络生成的prediction和mask进行细致的对比,并将结果展示在图1。其中绿色表示prediction正确分割的区域,红色表示over segmentation region,蓝色表示under segmentation region.
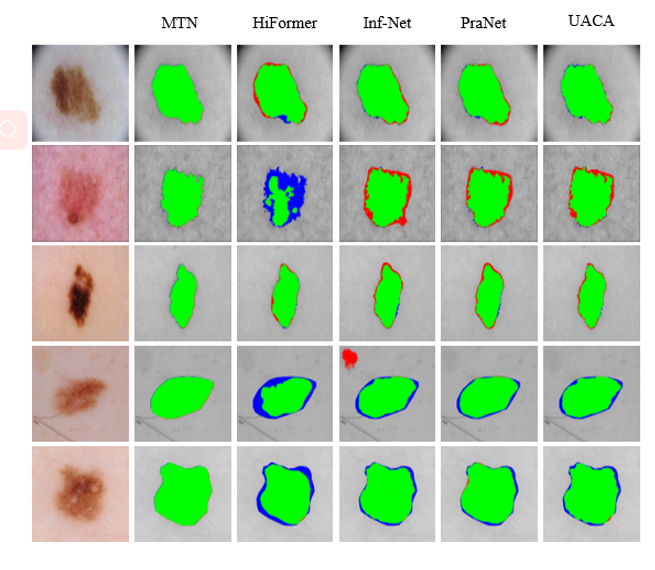
这一效果实现的代码如下:
需要注意,代码中RGB images、mask、prediction宽和高的比例都要相同。
import torch
import torchvision
from PIL import Image
def image_gray2RGB(image):
image_RGB = torch.zeros(size=(image.shape[0] + 2, image.shape[1], image.shape[2]))
# 维度上复制三次
image_RGB[0, :, :] = image
image_RGB[1, :, :] = image
image_RGB[2, :, :] = image
return image_RGB
pass
def get_tp(mask, prd):
# 都是基于tensor计算
# tp 取共同的像素,矩阵相乘
tp = mask * prd
return tp
def get_fp(mask, prd):
# fp prd中去除mask的部分
fp = prd * (1 - mask)
return fp
def get_fn(mask, prd):
# FN 取mask去掉prd的部分
fn = mask * (1 - prd)
return fn
def get_background(image, tp, fp, fn):
tp_fp_fn = tp + fp + fn
background = image * (1 - tp_fp_fn)
return background
pass
def image_gray2RGBRed(image):
image_RGB_RED = torch.zeros(size=(image.shape[0] + 2, image.shape[1], image.shape[2]))
# 维度上复制三次
image_RGB_RED[0, :, :] = image
return image_RGB_RED
pass
def converge_image(image_RGB, tp_RGB, fp_RGB, fn_RGB):
image = image_RGB + tp_RGB + fp_RGB + fn_RGB
return image
pass
def save_image(image, dst):
# image的格式为[H,W,C]
image = torch.clamp(image * 255, 0, 255).permute(1, 2, 0).byte().cpu().numpy()
image = Image.fromarray(image) # PIL.Image接受[H,W,C]这样格式图
image.save(dst)
def image_gray2RGBGreen(image):
image_RGB_GREEN = torch.zeros(size=(image.shape[0] + 2, image.shape[1], image.shape[2]))
# 维度上复制三次
image_RGB_GREEN[1, :, :] = image
return image_RGB_GREEN
pass
def image_gray2RGBlue(image):
image_RGB_BLUE = torch.zeros(size=(image.shape[0] + 2, image.shape[1], image.shape[2]))
# 维度上复制三次
image_RGB_BLUE[2, :, :] = image
return image_RGB_BLUE
def image_gray2RGBYellow(image):
image_RGB_BLUE = torch.zeros(size=(image.shape[0] + 2, image.shape[1], image.shape[2]))
# 维度上复制三次
image_RGB_BLUE[0, :, :] = image
image_RGB_BLUE[1, :, :] = image
return image_RGB_BLUE
def get_tensor_image(image_path):
# 转换格式
transform2tensor = torchvision.transforms.ToTensor()
image = Image.open(image_path)
image = image.convert("L")
image_tensor = transform2tensor(image)
return image_tensor
def test():
# original_image需要和mask_image以及prd_image的尺寸一致
origin_image_path = r'/home/stu/zy/data/ISIC2018/test/images/ISIC_0000510.png'
mask_image_path = r'/home/stu/zy/data/ISIC2018/test/masks/ISIC_0000510.png'
prd_image_path = r'/home/stu/zy/data/ISIC2018/overunder/UACA/ISIC_0000510_segmentation.png'
save_dst_path = r'/home/stu/zy/data/ISIC2018/overunder/UACA/ISIC_0000510_segmentation(2).png' # 这里直接写生成的图片的名称
origin_image = get_tensor_image(image_path=origin_image_path)
mask_image = get_tensor_image(image_path=mask_image_path)
prd_image = get_tensor_image(image_path=prd_image_path)
# 取TP, FP, FN
tp = get_tp(mask=mask_image, prd=prd_image)
fn = get_fn(mask=mask_image, prd=prd_image)
fp = get_fp(mask=mask_image, prd=prd_image)
# 获取背景
background_image = get_background(image=origin_image, tp=tp, fp=fp, fn=fn)
# 转化为RGB,并取一定的颜色
# 红色表示过分割、蓝色表示欠分割、绿色表示正常分割
background_image_RGB = image_gray2RGB(background_image)
tp_image_GREEN = image_gray2RGBGreen(tp)
fp_image_RED = image_gray2RGBRed(fp)
fn_image_Blue = image_gray2RGBlue(fn)
# 图片融合
image = converge_image(image_RGB=background_image_RGB, tp_RGB=tp_image_GREEN, fp_RGB=fp_image_RED, fn_RGB=fn_image_Blue)
# 保存结果
save_image(image=image, dst=save_dst_path)
if __name__=="__main__":
test()

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









