









ReLU全名Rectified Linear Unit,意思是修正线性单元。Relu激活函数是常用的神经激活函数。
ReLU函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被成为单侧抑制。
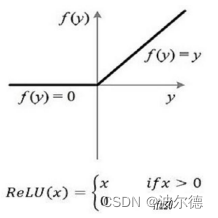
ReLU的优点:①ReLu具有稀疏性,可以使稀疏后的模型能够更好地挖掘相关特征,拟合训练数据;
②在x>0区域上,不会出现梯度饱和、梯度消失的问题;
③计算复杂度低,不需要进行指数运算,只要一个阈值就可以得到激活值。
RuLU的缺点也同样明显:①输出不是0对称
②由于小于0的时候激活函数值为0,梯度为0,所以存在一部分神经元永远不会得到更新
资料扩展
为了弥补sigmoid函数和tanh函数的缺陷,所以出现了ReLU激活函数。
这些激活函数的出现有一个历史先后问题, sigmoid函数出现的早, ReLU是晚辈;其次,不存在绝对的说法让ReLU完胜其它任何方案,因为在很多时候,不试一试别的方案,谁都不敢拍胸脯说这个网络已经没法提升了, 这就是神经网络的特点。
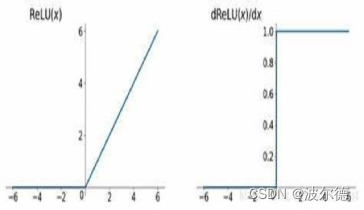
ReLU激活函数求导不涉及浮点运算,所以速度更快。在z大于零时梯度始终为1;在z小于零时梯度始终为0;z等于零时的梯度可以当成1也可以当成0,实际应用中并不影响。
对于隐藏层,选择ReLU作为激活函数,能够保证z大于零时梯度始终为1,从而提高神经网络梯度下降算法运算速度。

















 2064
2064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









