



一、简介
- 集成学习,是监督学习算法,支持分类与回归任务;
- 通过训练多个弱学习器(一般为决策树),加权融合为一个强学习器;
- 有bagging与boosting两种技术路径可以实现学习任务;
二、决策树
简介
- 通过特征分裂的方式,对特征中的信息进行学习,支持分类和回归任务;
- 特征分裂经典算法有:ID3, C4.5,以及Cart算法;
- 通过预剪枝或后剪枝的方式对模型的复杂度或泛化能力进行优化;
分裂收益评价
- 信息熵:刻画数据集D中信息的混乱程度,指标越大信息越混乱,Ent(D) = - Σ(pi * log(pi));
- 基尼值:刻画数据集D中信息纯度的指标,指标越大信息越纯,Gini(D) = 1 - Σ(pi ** 2);
- ID3分类:信息增益 = Ent(D) - Σ(Di / D * Ent(Di));
- C4.5分类:信息增益率 = 信息增益 / 特征属性熵,惩罚特征属性个数;
- Cart分类:基尼系数 = Σ(Di / D * Gini(Di)) - Gini(D);
- Cart回归:分裂评价 = Σ(yi - mean(y)) ** 2;
剪枝
- 决策树训练可能由于分裂充分,存在过拟合的问题;
- 预剪枝是在训练决策树过程中,自根节点而下,依次分别计算分裂时与剪枝时验证集的指标(如分类准确率),若剪枝时指标更高,则选择在该节点不分裂;
- 后剪枝是在决策树已充分训练分裂完成后,自最底层叶节点而上,依次计算剪枝时验证集的指标(如分类准确率),若剪枝时指标更高,则选择在该节点不分裂;
停止训练条件
- 所有特征已分裂完全;
- 到达预设最大树深度阈值;
- 叶子节点中的样本基尼值大于或熵值小于预设阈值;
- 分裂收益小于预设阈值;
- 叶子节点的样本数量小于预设阈值;
优缺点
- 优点:决策树的决策方式可以以树状结构进行展示,可视化效果好,可解释性好;
- 缺点:不剪枝容易过拟合,预剪枝容易欠拟合,后剪枝计算开销大;
sklearn实战
重要参数
class sklearn.tree.DecisionTreeClassifier(
criterion='gini',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=1e-07,
class_weight=None,
presort=False
):
# criterion 分裂算法,默认cart算法;
# max_depth 最大树深度,便于剪枝以及停止分裂;
# min_samples_leaf 叶子节点最小样本数;
# min_samples_split 内部节点最小样本数;
class sklearn.tree.DecisionTreeRegressor(criterion='mse'
,splitter='best'
,max_depth=None
,min_samples_split=2
,min_samples_leaf=1
,min_weight_fraction_leaf=0.0
,max_features=None
,random_state=None
,max_leaf_nodes=None
,min_impurity_split=1e-07
,presort=False):
# criterion 分裂算法,默认cart回归树mse损失函数评价分裂;
# 其它重要参数同上;
树结构可视化
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, export_graphviz
# 分类任务——鸢尾花数据
data = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(data["data"], data["target"], test_size=0.3, random_state=41)
# 决策树分类
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)
# 决策树可视化
import graphviz
dot_data = export_graphviz(model)
graph = graphviz.Source(dot_data)
graph.view()
三、bagging
简介
在集成学习中,bagging通过投票表决的方式进行决策,独立并行的训练n个弱学习器,将n个决策结果取均值或众数作为最终预测值,实现回归或分类任务,典型算法有随机森林;
随机森林
- 基学习器:决策树;
- 学习target:有放回抽样,学习原始target列;
- 特点:随机行采样(bootstrap采样)、列采样;
sklearn参数
# RandomForestClassifier
class sklearn.ensemble.RandomForestClassifier(
n_estimators=100,
criterion='gini',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='sqrt',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
):
# n_estimators 子树数量 默认10;
# criterion 衡量分类效果算法 默认gini,也可选择entropy;
# max_depth 最大树深度 默认全分裂;
# min_samples_split 结点分裂需满足最小样本数;
# min_samples_leaf 叶结点应满足的最小样本数;
# max_features 默认所有特征,可选择auto、sqrt、log2进行随机列采样;
# RandomForestRegressor
class sklearn.ensemble.RandomForestRegressor(
n_estimators=100,
criterion='mse',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto',
max_leaf_nodes=None,
min_impurity_split=1e-07,
bootstrap=True,
oob_score=False,
n_jobs=1,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
):
# criterion 衡量回归效果指标,默认mse,也可选mae;
四、boosting
在集成学习中,boosting通过再学习的方式串行训练多个弱学习器,每个新的弱学习器都对前面的知识进行复用再优化,并将多个弱学习器进行加权融合或简单加和,得到一个强学习器进行决策,实现分类或回归任务,典型算法有Adaboost、GBDT、Xgboost、LightGBM、Catboost等;
Adaboost
- 基学习器:决策树、朴素贝叶斯、线性回归等弱学习器;
- 学习target:不断调整样本权重或者说样本分布的target列;
- 特点:提高训练预测错误的样本的权重,降低训练预测正确的样本的权重,作为后面的学习器的样本集;降低模型评价指标低(如mse或acc等)的模型权重,提高模型评价指标高的模型权重,加权融合为强学习器;
GBDT
- 基学习器:cart决策树;
- 学习target:不放回子采样、梯度学习;
- 优点:损失函数一阶泰勒展开、沿着损失函数梯度的反方向进行shrinkage学习;
XGBoost
- 基学习器:cart决策树、线性回归、逻辑回归;
- 学习target:有放回抽样,学习损失函数的一阶导数及二阶导数;
- 优点:损失函数二阶泰勒展开,并引入叶子结点数量及叶子结点值惩罚项,并给出最优叶子结点值及其分裂收益度量;对缺失值引入稀疏感知算法;level-wise广度优先并行分裂算法;
- 缺点:特征预排序以及所有叶结点样本计算一阶、二阶导数,计算开销大;
LightGBM
- 特征分箱:为优化xgb的特征预排序计算开销大的问题,提前对特征进行分箱;
- 单边梯度采样:为优化xgb的所有叶子结点样本计算一二阶导数的计算开销大问题,对梯度大的样本全量计算,梯度小的样本抽样计算线性估计;
- 互斥特征捆绑算法:对离散变量进行捆绑,优化特征稀疏的问题;
- leaf-wise分裂:基于深度优先的分裂算法,选分裂收益最大的叶结点深度分裂;
Catboost
- 特征编码:分类任务中,将离散特征进行order target编码,采用样本随机排序的方式,依次基于前面的样本对当前样本进行greedy target编码;下图中a为超参数、p为先验正类概率;
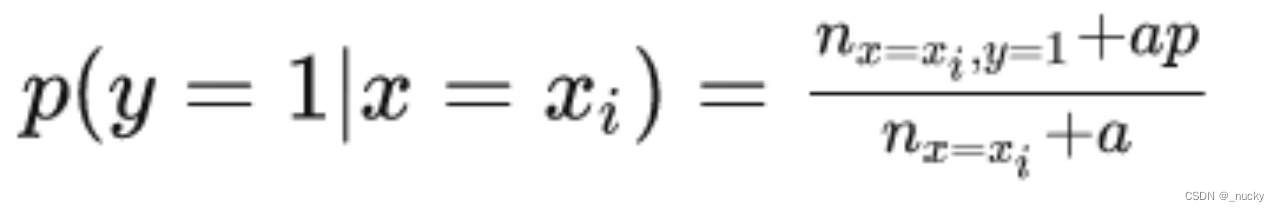
- 特征组合:将新的待分裂类别特征,与前面选择分裂过的离散特征进行两两组合,形成新的特征,丰富特征维度,优化稀疏特征;
- 对称树:在每一层树分裂时,都选择相同的特征及分裂条件,以一种新的分裂收益度量,选择分裂收益最大的特征及分裂条件;提高泛化能力、提高训练速度、提高预测速度;
- 梯度无偏估计:将样本进行随机排序,依次训练n-1个模型,去估计第n个样本的梯度;
- 共用样本排序:做特征编码与梯度无偏估计用的同一个样本排序;
- 共用无偏估计模型:在第一棵树的梯度无偏估计训练出n个模型后,后面的新树训练时,只做样本随机排序编码,梯度无偏估计复用第一棵树的多个模型;
sklearn参数
# AdaBoostClassifier
class sklearn.ensemble.AdaBoostClassifier(
base_estimator=None,
n_estimators=50,
learning_rate=1.0,
algorithm='SAMME.R',
random_state=None
):
# base_estimator 基分类器,默认决策树,也可指定其它弱分类器;
# n_estimators 基学习器个数,默认50个;
# learning_rate 学习率,默认1,调节梯度学习收敛速度
# AdaBoostRegressor
class sklearn.ensemble.AdaBoostRegressor(
base_estimator=None,
n_estimators=50,
learning_rate=1.0,
loss='linear',
random_state=None
):
# loss 训练误差度量算法,默认线性,可选择linear, square, exponential;
# GBDT cls
class sklearn.ensemble.GradientBoostingClassifier(
loss=’deviance’,
learning_rate=0.1,
n_estimators=100,
subsample=1.0,
criterion=’friedman_mse’,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
min_impurity_decrease=0.0,
min_impurity_split=None,
init=None,
random_state=None,
max_features=None,
verbose=0,
max_leaf_nodes=None,
warm_start=False,
presort=’auto’
):
# loss 默认deviance对数似然损失函数, 可选择exponential指数损失函数;
# subsample 基学习器训练使用的样本比例,不放回抽样,默认不进行子采样,全量训练;
# 其他可参考决策树及随机森林等模型重要参数
# GBDT reg
class sklearn.ensemble.GradientBoostingRegressor(
loss=’ls’,
learning_rate=0.1,
n_estimators=100,
subsample=1.0,
criterion=’friedman_mse’,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
min_impurity_decrease=0.0,
min_impurity_split=None,
init=None,
random_state=None,
max_features=None,
alpha=0.9,
verbose=0,
max_leaf_nodes=None,
warm_start=False,
presort=’auto’
):
# loss 默认均方误差ls,也可选择绝对损失"lad", Huber损失"huber"和分位数损失“quantile”;alpha与quantile相匹配;
# 其他重要参数与分类参数相似;
五、sklearn实战
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
# 分类任务——鸢尾花数据
data = datasets.load_wine()
X_train, X_test, y_train, y_test = train_test_split(data["data"], data["target"], test_size=0.3, random_state=41)
# 决策树分类
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)
print("acc train dt: ", model.score(X_train, y_train))
print("acc test dt: ", model.score(X_test, y_test))
# 随机森林分类
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
print("acc train rf: ", model.score(X_train, y_train))
print("acc test rf: ", model.score(X_test, y_test))
# adaboost分类
model = AdaBoostClassifier(random_state=42)
model.fit(X_train, y_train)
print("acc train ada: ", model.score(X_train, y_train))
print("acc test ada: ", model.score(X_test, y_test))
# gbdt分类
model = GradientBoostingClassifier(random_state=42)
model.fit(X_train, y_train)
print("acc train gbdt: ", model.score(X_train, y_train))
print("acc test gbdt: ", model.score(X_test, y_test))
# xgb分类
model = XGBClassifier(random_state=42)
model.fit(X_train, y_train)
print("acc train xgb: ", model.score(X_train, y_train))
print("acc test xgb: ", model.score(X_test, y_test))
# lgbm分类
model = LGBMClassifier(random_state=42)
model.fit(X_train, y_train)
print("acc train lgbm: ", model.score(X_train, y_train))
print("acc test lgbm: ", model.score(X_test, y_test))
# catboost分类
model = CatBoostClassifier(random_state=42, verbose=False)
model.fit(X_train, y_train)
print("acc train cat: ", model.score(X_train, y_train))
print("acc test cat: ", model.score(X_test, y_test))
参考
https://blog.youkuaiyun.com/qq_45956730/article/details/126689318
https://www.yii666.com/blog/399381.html
https://zhuanlan.zhihu.com/p/477750675
https://blog.youkuaiyun.com/junhongzhang/article/details/103686756
https://www.cnblogs.com/sylz/p/6859724.html
https://blog.youkuaiyun.com/geduo_feng/article/details/79561571
https://www.jianshu.com/p/0602e2093c1a

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









