






 DETR是首个将Transformer应用于端到端目标检测的任务,摒弃了手工设计的锚点和后处理步骤。模型由CNN特征提取器、Transformer编码器-解码器和前向网络组成,其中Transformer对位置信息进行了2D编码。DETR通过集合预测损失进行训练,解决了预测框的无序问题。实验表明,DETR在准确率和运行时间上与Faster R-CNN相当,并在泛光谱分割任务上表现出色。
DETR是首个将Transformer应用于端到端目标检测的任务,摒弃了手工设计的锚点和后处理步骤。模型由CNN特征提取器、Transformer编码器-解码器和前向网络组成,其中Transformer对位置信息进行了2D编码。DETR通过集合预测损失进行训练,解决了预测框的无序问题。实验表明,DETR在准确率和运行时间上与Faster R-CNN相当,并在泛光谱分割任务上表现出色。
End-to-End Object Detection with Transformers
主要工作
目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。 在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,整体结构如下所示:

文章的主要有两个关键的部分。
第一个是用transformer的encoder-decoder架构一次性生成 N 个box prediction。其中 N 是一个事先设定的、比远远大于image中object个数的一个整数。
第二个是设计了bipartite matching loss,基于预测的boxex和ground truth boxes的二分图匹配计算loss的大小,从而使得预测的box的位置和类别更接近于ground truth。
二、引言
DETR(DEtection TR ansformer)
目标检测可以预测出图片中物体的bbox与category,当前的检测算法都是在大量的proposals,anchors或者window centers上定义 一个回归与分类问题 来解决,因此这些模型会受限于 处理近似重复的预测物体 、anchor的创建、 将bbox分配给anchor的启发算法。
DETR提出了一种直接集合预测来跳过这些过程,即是一个end-to-end过程,它通过将CNN与transformer结合来直接预测最终的set of detections,它抛弃了像 anchors,NMS(极大值抑制) ,等这些自定义的层。

DETR证明了它在 大物体上的预测效果很好 ,但是在 小物体上效果比较差 ,并且也指出 后续可以利用FPN来以相同的方法解决。
这里简单介绍下 集合预测 , 常见的目标检测方法如Faster-RCNN,RetinaNet等都是通过预设anchor的方式进行预测,这种方式本质上就是类似滑动窗口的一种模式。而使用这种滑动窗口的方式其实是人为地给检测任务降低难度,这也确实是早期的传统方式做模式识别的一种主流方式。
而基于集合预测的方式就显得更简单粗暴了,输入一副图像,网络的输出就是最终的预测的集合(也不需要任何后处理)能够直接得到预测的集合就已经达到了检测的目的了。但这种方式从直觉上看会比基于滑动窗口的方式更难。基于滑窗的方式就像人为地给了一个梯子,帮助网络去越过障碍,而集合预测就更需要网络真正懂得图像的语义而直接越过障碍。
集合预测带来的最大好处就是训练与预测变成真正的端到端,无需NMS的后处理,十分方便。同时,也不用人为地预设anchor size/ratio 了。坏处就是这玩意儿能收敛吗?
上述这段解释来自于:原文链接
3、DETR模型
3.1 DETR网络架构
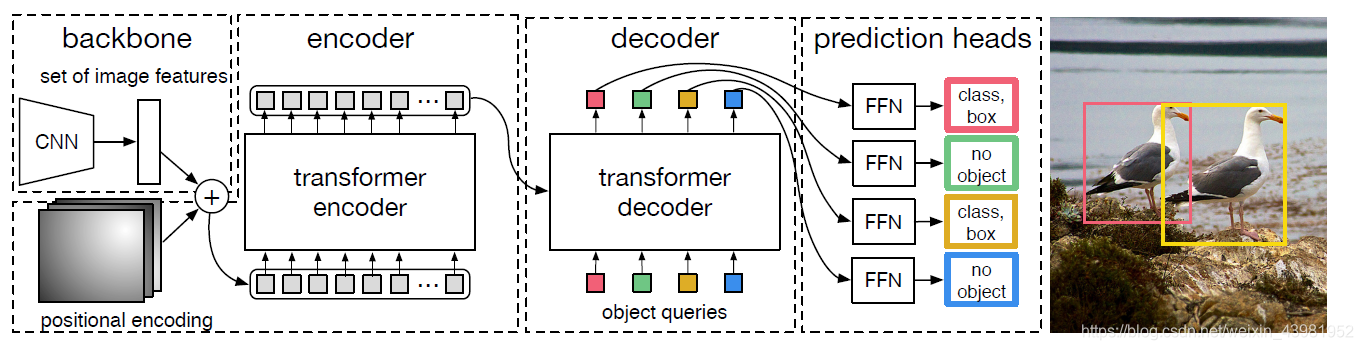
DETR有三部分组成:一个CNN特征提取器,一个encoder-decoder transformer,一个前向网络FFN
Backbone :img =》feature map(B, C, H, W), C=2048,H,W为原来的32分之一
Transformer :
(1)encoder :encoder的输入是[B, C, H, W] 维的feature map,接下来依次进行以下过程:
- 通道数压缩 : 先用1 x 1卷积处理,将channels数从C降到d,得到[B,d, H, W]维的新特征图
- 转化为序列化数据 : 将特征图的H 与 W 压缩为一个维度,变为[B, d, HW]
- 位置编码 : 因为在self-attention中需要有表示位置的信息,否则你的sequence = “A打了B” 还是sequence = "B打了A"的效果是一样的。但是transformer encoder这个结构本身却无法体现出位置信息。也就是说,我们需要对这个特征图做位置编码。
这里Vision Transformer 使用的位置编码与原版的Transformer是有一定的区别的,原来的因为是nlp问题,只需要在一个维度上编码即可,而这里是图像,不能只考虑在一个方向上位置编码,需要从h和w两个方向上编码。
Transformer的Position Encoding表达式如下:
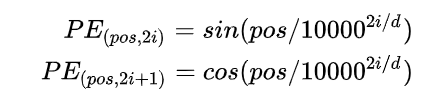
式中,d就是[B, d, HW] 中的d,pos ∈[1, HW],表示token在sequence中的位置,而sequence的长度就是HW, 例如,第一个token的pos就为0。i 表示了位置编码的维度,它的取值范围为: [0,1,2,…,d/2] 。例如,当pos为1是,位置编码可以表示为:
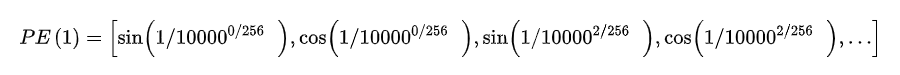
式中,d=256。
- 第一点不同是: Transformer只考虑 x 方向 的位置编码,但是DETR考虑了 x和y 方向的位置编码,因为图像特征是2-D特征。采用的依然是sin和cos 模式,但是需要考虑 x和y 两个方向。不是类似vision transoformer做法简单的将其拉伸为 [d, HW] ,然后从 [1, HW] 进行长度为256的位置编码,而是考虑了 x和y 方向同时编码,每个方向各编码128维向量 ,这种编码方式更符合图像特点。
Positional Encoding的输出张量是:[B, d, H, W], d = 256,表示编码的长度。H, W表示编码的位置,也就是说,特征图上的任意一点(H1, W1)都有一个256位的位置编码,其中前128维表示H1的位置编码,后128维表示W1的位置编码。
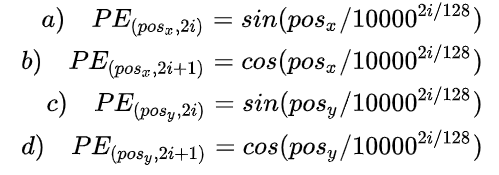
计算所有位置的编码,就得到了 (256,H, W) 的张量,代表这个batch的位置编码。编码矩阵的维度是 (B, 256,H, W) ,也把它序列化成维度为 [HW, B, 256] 维的张量。 , 准备与(HW, B, 256)维的feature map相加后输入到Encoder中。
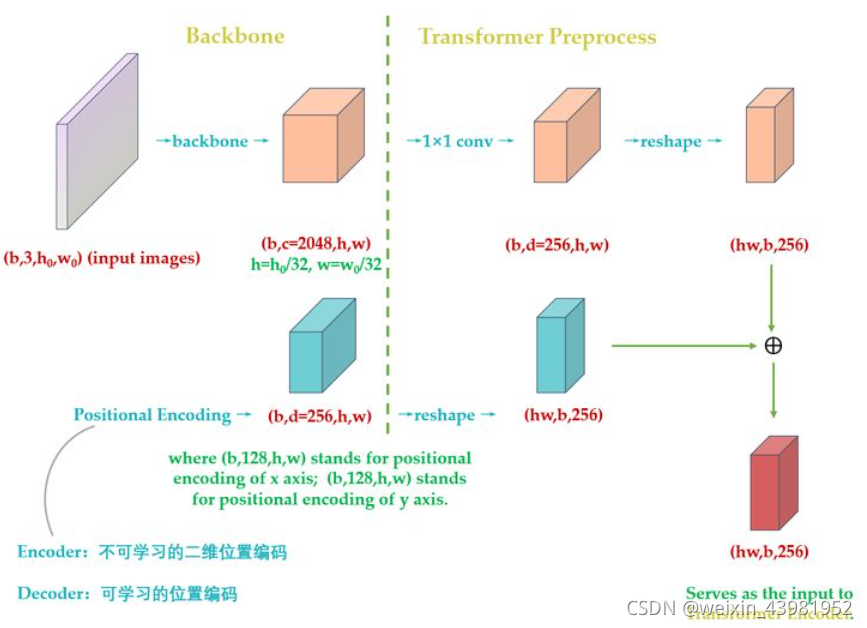
- 另一点不同的是 :原版Transformer只在Encoder之前使用了Positional Encoding,而且是在输入上进行Positional Encoding,再把输入经过transformation matrix变为Query,Key和Value这几个张量。但是DETR在Encoder的每一个Multi-head Self-attention之前都使用了Positional Encoding,且只对Query和Key使用了Positional Encoding,即:只把维度为[HW, B, 256] 维的位置编码与维度为[HW, B, 256] 维的Query和Key相加,而不与Value相加。
Encoder最终输出的是 [HW, B, 256] (seq,batch,feature) 维的编码矩阵Embedding,按照原版Transformer的做法,把这个东西给Decoder。
总结下和原始transformer编码器不同的地方:
- 输入编码器的位置编码需要考虑2-D空间位置。
- 位置编码向量需要加入到每个Encoder Layer中。
- 在编码器内部位置编码Positional Encoding仅仅作用于Query和Key,即只与Query和Key相加,Value不做任何处理。
(2)decoder :
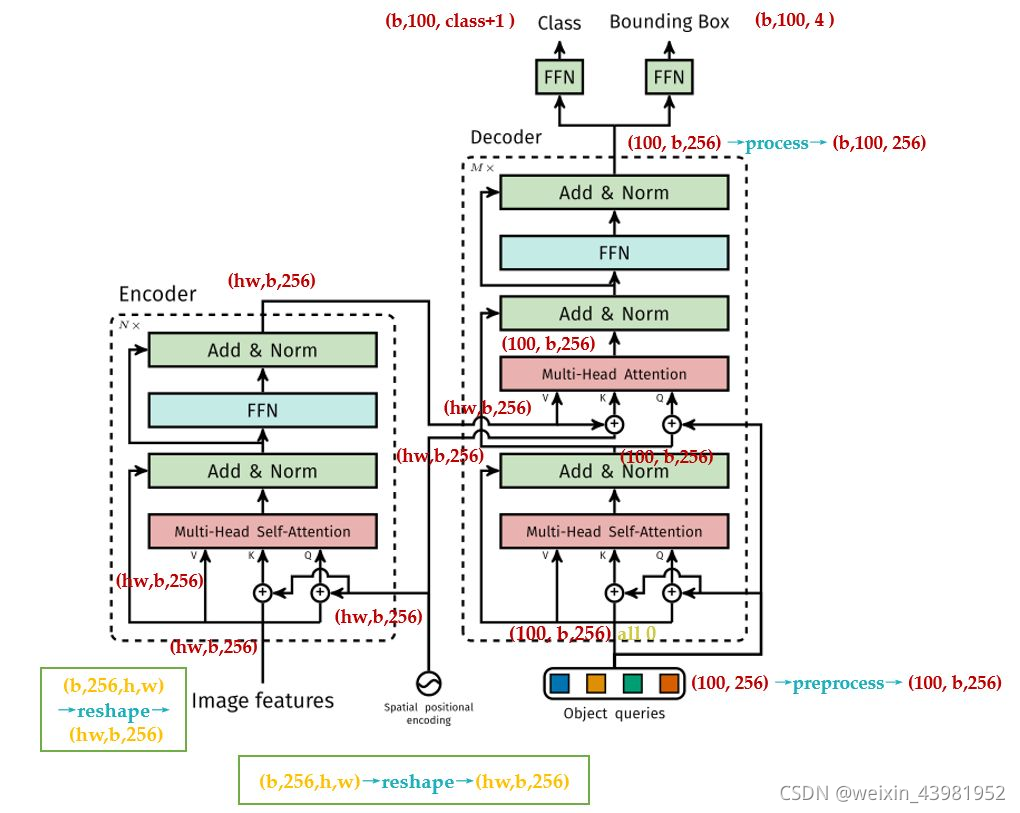
DETR的Decoder和原版Transformer的decoder是不太一样的。
先回忆下原版Transformer,decoder的最后一个框:output probability,代表我们一次只产生一个单词的softmax,根据这个softmax得到这个单词的预测结果。这个过程我们表达为:predicts the output sequence one element at a time。
不同的是,DETR的Transformer Decoder是一次性处理全部的object queries,即一次性输出全部的predictions;而不像原始的Transformer是auto-regressive的,从左到右一个词一个词地输出。这个过程我们表达为:decodes the N objects in parallel at each decoder layer。
DETR的Decoder主要有两个输入:
- Transformer Encoder输出的Embedding与 position encoding 之和。
- Object queries。
其中,Enbedding就是[HW, b, 256] 维的矩阵。下面讲一下Object queries。
Object queries是一个维度为 [100, b, 256] 维的张量,数值类型是nn.Embedding,说明这个张量是可以学习的,即:我们的Object queries是可学习的。Object queries矩阵内部通过学习建模了100个物体之间的全局关系,例如房间里面的桌子旁边(A类)一般是放椅子(B类),而不会是放一头大象(C类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出。
Decoder的输入一开始也初始化成维度为 [100, b, 256] 维的全部元素都为0的张量,和Object queries加在一起之后充当第1个multi-head self-attention的Query和Key。第一个multi-head self-attention的Value为Decoder的输入,也就是全0的张量。
到了每个Decoder的第2个multi-head self-attention,它的Key和Value来自Encoder的输出张量,维度为 [HW, b, 256] ,其中Key值还进行位置编码。Query值一部分来自第1个Add and Norm的输出,维度为 [100, b, 256] 的张量,另一部分来自Object queries,充当可学习的位置编码。 所以,第2个multi-head self-attention的Key和Value的维度为 [HW, b, 256] ,而Query的维度为[100, b, 256]。
每个Decoder的输出维度为 [1, b, 100, 256] ,送入后面的前馈网络,生成最后的cls与bbox。
到这里你会发现:Object queries充当的其实是位置编码的作用 ,只不过它是可以学习的位置编码
(3)FFN :
3.2 集合预测损失
DETR会预测出固定的N个物体(N=100大于一张图片所有物体的数量),对于真值,可以通过padding空物体φ来达到N,只不过,计算Loss时回归分支仅计算有物体位置,填充的背景。
但问题来了,由于输出的(b, 100) 是无序的,模型怎么知道第47个预测框对应图片里的狗,第88个预测框对应图片里的汽车呢?这就应用到经典的双边匹配算法了
DETR就是找出一个能够使得代价最低的N的排列,然后根据这个排列优化object-specific损失,
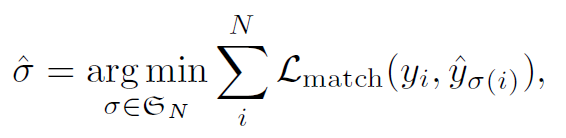
其中,δ帽表示生成的最优的全排列,Lmatch公式如下:
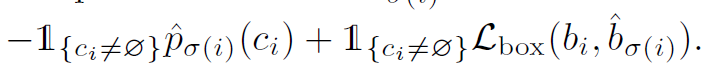
其中ci表示第i个物体的类别,p表示可能性。
当得到最优的全排列后,计算损失值,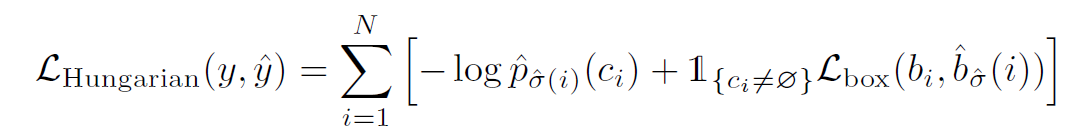
其中,box的损失计算如下:
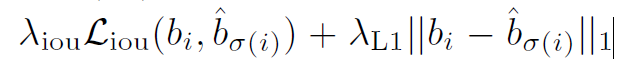
因为在common的检测任务中对于bbox的loss都是L1损失,他们对于尺寸不同的bbox,有着相似的相对错误,这里采用将L1与IOU损失的线性组合。
训练结束后,模型如何预测呢?
训练结束后,模型就学习到了一种能力,即:模型产生的100个预测框,它知道某个预测框该对应什么Object 。
4、实验
(1)使用resize将图像的短边为p[480, 800],而长边最长为1333
(2)随机的crop,使得AP上升了1,随机概率为0.5
(3)dropout概率为0.1

















 4822
4822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









