





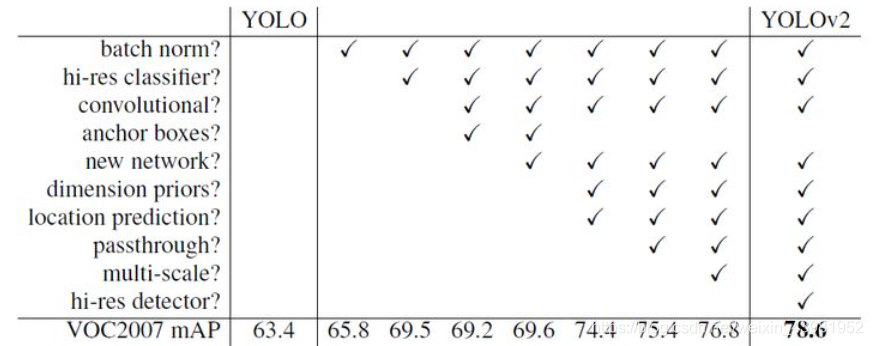
YOLOv-2是在YOLO的基础上添加了很多改进策略最后得出的,
Batch Normalization
High Resolution Classifier:ImageNet数据集中的图像分辨率大都为224224,YOLO是在ImageNet上预训练后直接应用在448448上,这会使模型难以适应,而YOLOv-2是在ImageNet448*448上进行微调训练后,才进行在检测数据集上微调。
Convolutional with anchor boxes :采用faster rcnn中rpn生成anchor的思想
Dimension Clusters :采用K-means对训练集中的边界框做聚类分析,使得模型更容易训练
New Network: Darknet-19 :19个卷积层,5个maxpooling层。这个新模型时map没有显著提升,但是计算量减少了33%
Direct location prediction:YOLOv-2是根据anchor boxes来预测bbox
的,这会导致预测的边界框落在图片的任何位置,YOLOv-2采用YOLO的思想,将每个框的中心点定义为对应cell左上角位置的相对偏移值,将中心坐标限制在cell内部,防止偏移过多。
Fine-Grained Feature(细粒度特征) :v2提出了一种passthrough层来利用更精细的特征图,它与resnet中的shortcut连接有点相似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上,只不过,passthrough将前面一层的高分辨率特征图划分为2X2的局部区域,在channel维度拼接,并与下一层特征图再拼接,最后在此特征图上卷积预测。
Multi-Scale Training :具体来说是就是在训练过程中每间隔一定的iterations之后改变模型的输入图片大小,由于YOLOv2的下采样总步长为32,输入图片大小选择一系列为32倍数的值: {320,352,…,608},
YOLOv-2论文笔记
最新推荐文章于 2024-10-05 13:26:58 发布


















 9054
9054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









