






 SSD(Single Shot MultiBox Detector)与YOLO(You Only Look Once)都是目标检测算法,但SSD通过多尺度特征图和先验框提升了速度与精度。它在每个特征图单元格上预测多个尺度和长宽比的边界框,减少了训练难度。训练过程中,SSD采用hard negative mining平衡样本,并使用Smooth L1和Softmax损失函数。预测时,经过NMS等步骤筛选高置信度的检测结果。
SSD(Single Shot MultiBox Detector)与YOLO(You Only Look Once)都是目标检测算法,但SSD通过多尺度特征图和先验框提升了速度与精度。它在每个特征图单元格上预测多个尺度和长宽比的边界框,减少了训练难度。训练过程中,SSD采用hard negative mining平衡样本,并使用Smooth L1和Softmax损失函数。预测时,经过NMS等步骤筛选高置信度的检测结果。
首先讲解一下one-stage与two-stage的不同:
(1)two-stage方法 ,如R-CNN系算法,其主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,two-stage方法的优势是准确度高;(2)one-stage方法 ,如Yolo和SSD,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡(参见Focal Loss),导致模型准确度稍低。
相比YOLO,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层 之后做检测。同时还有其他两个不同点:一是 SSD提取了不同尺度的特征图 来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框 (Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。
设计理念
SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图
(1)采用多尺度特征图用于检测
这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标
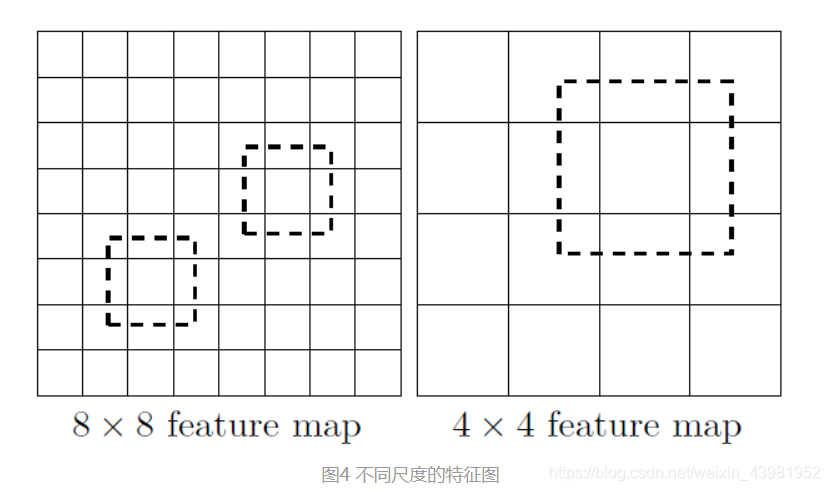
(2)采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为mnp的特征图,只需要采用33p这样比较小的卷积核得到检测值。
(3)设置bbox
yolo中每个单元格预测多个bbox,每bbox(x,y,w,h)中x,y是相对于该单元格左上角的相对坐标的,而w,h是相对于整张图片的比例的。 SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。
对于一个大小m*n 的特征图,共有mn个单元,每个单元设置的先验框数目记为k,那么每个单元共需要(c+4)*k个预测值,其中c表示类别数,包括背景,所有的单元共需要(c+4)kmn 个预测值,由于SSD采用卷积做检测,所以就需要 (c+4)k 个卷积核完成这个特征图的检测过程。
网络结构
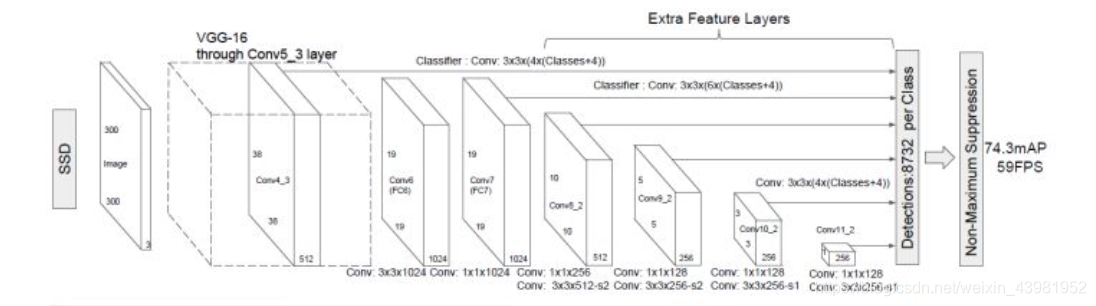
将Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2以及Conv4_3层特征图作为检测所用的特征图,但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加 。
训练过程
(1)先验框匹配 :在Yolo中 ,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。在SSD中 :对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。这样会造成正负样本数不均衡,未解决该问题,SSD对于剩余的未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。为了保证正负样本尽量平衡 ,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
(2)损失函数
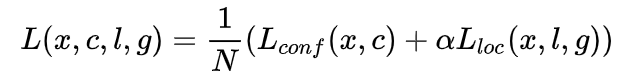
其中N是正样本数量,位置误差使用smooth L1 loss,置信度误差使用softmax loss。
(3)数据扩增
水平翻转,随机裁剪,颜色扰动
预测过程
首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。

















 2129
2129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









