







题目
知识密集型多步骤问题的交叉检索与思维链推理

论文地址:https://arxiv.org/abs/2212.10509
项目地址:https://github.com/stonybrooknlp/ircot
摘要
基于提示的大型语言模型(LLM)在为多步问答(QA)生成自然语言推理步骤或思维链(CoT)方面惊人地强大。然而,当必要的知识对于LLM来说是不可获得的或者在其参数内不是最新的时,它们会很困难。虽然使用问题从外部知识源检索相关文本有助于LLM,但我们注意到这种一步检索和阅读的方法对于多步问答是不够的。这里,检索什么取决于已经导出的内容,而导出的内容又可能取决于以前检索的内容。为了解决这个问题,我们提出了IRCoT,一种新的多步骤问答方法,它将检索与CoT中的步骤(句子)交错,用CoT指导检索,并反过来使用检索结果来改进CoT。在四个数据集上使用IRCoT和GPT3极大地提高了检索(高达21点)和下游QA(高达15点): HotpotQA、2WikiMultihopQA、MuSiQue和IIRC。我们在out-ofdistribution (OOD)设置以及Flan-T5-large等小得多的模型中观察到类似的显著收益,而无需额外培训。IRCoT减少了模型幻觉,导致事实上更准确的CoT推理。
引言
大型语言模型能够通过生成逐步的自然语言推理步骤来回答复杂的问题,即所谓的思维链(CoT),当得到适当的提示时(Wei等人,2022)。当回答问题所需的所有信息要么作为上下文(例如,代数问题)提供,要么假设存在于模型的参数中(例如,常识推理)时,这种方法是成功的。然而,对于许多开放领域的问题,所有需要的知识在模型参数中并不总是可用或最新的,从外部来源检索知识是有益的(Lazaridou等人,2022;Kasai等人,2022)。
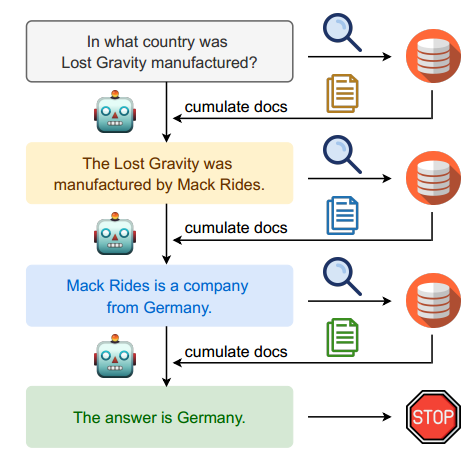
图1: IRCoT将思维链(CoT)生成和知识检索步骤交错在一起,以便通过CoT来指导检索,反之亦然。与仅使用问题作为查询的标准检索相比,这种交错允许为后面的推理步骤检索更多的相关信息。
对于需要复杂、多步推理的开放领域、知识密集型任务,我们如何增强思维链提示?虽然仅基于问题从知识源进行一次性检索可以成功地为LMs增加许多基于仿真陈述的任务的相关知识(Lewis等人,2020;Guu等人,2020;Borgeaud等人,2022年;Izacard等人,2022),这种策略对于更复杂的多步推理问题有明显的局限性。对于这样的问题,人们通常必须检索部分知识,进行部分推理,根据部分推理的结果检索附加信息推理到此为止,并迭代。作为一个例子,考虑图1中的问题,“失重在哪个国家生产?”。使用问题(特别是过山车失去重力)检索到的维基百科文档没有提到失去重力是在哪里制造的。相反,人们必须首先推断它是由一家名为Mack Rides的公司制造的,然后根据推断的公司名称进行进一步检索,以获得指向制造国的证据。
因此,检索和推理步骤必须相互通知。如果没有检索,模型很可能由于幻觉而产生不正确的推理步骤。此外,如果不生成第一个推理步骤,支持第二个步骤的文本就不容易识别,因为它们与问题没有词汇甚至语义重叠。换句话说,我们需要检索事实,以便生成事实上正确的推理步骤和检索相关事实的推理步骤。基于这种直觉,我们提出了一种解决这个问题的交错方法,其思想是使用检索来指导思想链(CoT)推理步骤,并使用CoT推理来指导检索。图1显示了我们的检索方法的概况,我们称之为IRCoT。
我们首先使用问题作为查询来检索一组基本段落。随后,我们在以下两个步骤之间交替:(I)扩展CoT:使用问题、迄今收集的段落和迄今生成的CoT句子来生成下一个CoT句子;(ii)扩展检索到的信息:使用最后一个CoT句子作为查询来检索附加段落以添加到收集的集合中。我们重复这些步骤,直到CoT报告一个答案,或者我们达到最大允许推理步骤数。在终止时,所有收集的段落都作为检索结果返回。最后,我们通过直接问答提示(Brown等人,2020)或CoT提示(Wei等人,2022)将这些作为回答问题的背景。
我们在开放域设置下的4个多步推理数据集上评估了我们的系统的有效性:HotpotQA(杨等人,2018),2WikiMultihopQA (Ho等人,2020),MuSiQue (Trivedi等人,2022)和(Ferguson等人,2020)。我们的实验使用OpenAI GPT3(代码-davinci-002) (Brown等人,2020;欧阳等,2022;陈等,2021)证明使用IRCoT进行检索比在固定预算最优检索设置下通过11-21个检索点进行的基线、一步式、基于问题的检索有效得多。3当IRCoT与基于提示的阅读器结合使用时,它还能显著提高下游少数镜头QA性能(高达15 F1分),并将生成的CoT中的实际错误减少高达50%。我们的方法也适用于小得多的Flan-T5模型(11B、3B和0.7B),显示出类似的趋势。特别是,我们发现使用带有IRCoT的Flan-T5-XL (3B)的QA甚至优于具有一步基于问题的检索的58倍大的GPT3。此外,这些改进也适用于分布外(OOD)环境,在这种环境中,当在另一个数据集上进行测试时,会使用来自一个数据集的演示。最后,我们注意到,我们的问答分数超过了最近关于开放域问答的少量提示(ODQA)的工作报告的分数(Khot等人,2023;普雷斯等人,2022;Yao等人,2022),尽管不可能对它们进行公平的比较(参见附录C)。
总之,我们的主要贡献是一种新颖的检索方法,IRCoT,它利用LMs的思想链生成能力来指导检索,并反过来使用检索来改进CoT推理。我们证明了IRCoT:
- 在IID和面向对象的设置中,提高了几个多步骤开放域问答数据集的检索和少量问答性能;
- 减少生成的成本中的事实错误;
- 无需任何培训即可提高大型(175B型号)和小型(Flan-T5-*,≤11B)型号的性能。
相关工作
开放领域QA
提示。LLM可以通过简单地使用几个例子作为提示来学习各种任务(Brown et al,2020)。他们还被证明可以通过一步一步的推理(思维链,或CoT)来回答复杂的问题(魏等人,2022;小岛康誉等人,2022)。提示已经被应用于开放领域QA (Lazaridou等人,2022;孙等,2022;Yu等人,2023),但它在改进多步骤开放领域问题的检索和QA方面的价值仍然相对未得到充分探索。
最近有三种方法被提出用于多步开放域问答。SelfAsk (Press et al,2022)提示LLM将一个问题分解成子问题,并通过调用Google搜索API来回答子问题。分解(Khot等人,2023年)是一个通用框架,分解一个任务,并委托子任务到适当的子模型。他们也分解问题,但是将检索委托给基于BM25的检索器。这两种方法都不是为CoT推理开发的,不关注检索问题,并且需要单跳QA模型来回答分解的问题。最近提出的ReAct (Yao等人,2022)系统将问题框架为生成一系列推理和行动步骤。这些步骤要复杂得多,依赖于大得多的模型(PaLM-540B ),并且需要微调以优于多步ODQA的CoT。此外,这些工作都没有显示出对没有任何训练的较小模型有效。
虽然与这些方法的直接比较并不直接(知识语料库、LLM、示例的差异),但我们发现我们的ODQA性能远远高于他们所有可用的报告数字(5)。
有监督的多步骤开放领域问答
先前的工作已经探索了在完全监督的环境下开放领域问答的迭代检索。Das等人(2019)提出了一种迭代检索模型,该模型使用神经查询表示进行检索,然后根据阅读理解模型的输出进行更新。Feldman和El-Yaniv (2019)将类似的神经查询重构思想应用于多跳开放域QA。熊等(2021)将广泛使用的密集通道检索(DPR) (Karpukhin等人,2020)扩展到多跳设置,此后Khattab等人(2021)对此进行了改进。Asai等人(2020)利用维基百科段落中存在的实体链接诱导的图结构来执行迭代的多步检索。黄金(黄金实体)检索器(Qi等人,2019)基于从现成的检索器检索的段落迭代地生成文本查询,但是需要用于下一个查询生成器的训练数据。中野等人(2021)使用GPT3通过与浏览器交互来回答长格式问题,但依赖于这些交互的人工注释。所有这些方法都依赖于大规模数据集上的监督训练,并且不容易扩展到少数镜头设置。
思维链引导的检索和开域问答
我们的目标是利用包含大量文档的知识源,在几个镜头的设定下回答一个知识密集型的多步推理问题Q。为了做到这一点,我们遵循一个检索和读取范式(朱等,2021),其中检索器首先从知识源检索文档,QA模型读取检索到的文档和问题以生成最终答案。我们的贡献主要是在检索步骤(3.1),我们在读取步骤(3.2)使用标准的提示策略。如前所述,对于多步骤推理,检索可以帮助指导下一个推理步骤,这反过来可以通知接下来检索什么。这激发了我们的交错策略,下面讨论。
利用思想链推理的交错检索
我们提出的检索器方法IRCoT可以由以下三个成分实例化:(I)基本检索器,其可以接受查询并从语料库或知识源返回给定数量的段落;㈡具有零/少量思维链生成能力的语言模型;以及(iii)少量带注释的问题,带有解释如何以自然语言(思维链)得出答案的推理步骤,以及来自知识源的一组段落,这些段落共同支持推理链和答案。
IRCoT的概况见图2。我们首先通过使用问题Q作为查询检索K个段落来收集基本段落集。然后,我们迭代地交错两个步骤(推理和检索),直到满足终止标准。检索引导推理步骤(“推理”)使用问题、目前收集的段落和目前生成的CoT句子生成下一个CoT句子。该任务的提示模板如下所示:维基百科标题:<页面标题> <段落文本>…
维基百科标题:< Page Title> 问:< Question >答:< CoT-Sent-1 >…< CoT-Sent-n >对于上下文演示,我们使用上述格式的完整CoT。对于一个测试实例,我们只向模型显示迄今为止生成的CoT句子,并让它完成其余部分。即使模型可能输出多个句子,对于每个推理步骤,我们只取第一个生成的句子,而丢弃其余的。
对于上下文演示中的段落,我们使用基本事实支持段落和M个随机抽样的段落,以上述格式混洗并连接在一起。对于一个测试实例,我们显示了在所有之前的检索步骤中收集到的所有段落。如果生成的CoT语句具有“答案是:”字符串,或者已经达到最大步骤数4,我们将终止该过程,并将所有收集的段落作为检索结果返回。CoT引导的检索步骤(“检索”)使用最后生成的CoT句子作为查询来检索更多的段落,并将它们添加到收集的段落中。我们对收集到的段落总数进行了限制,以便在模型的上下文限制中至少适合一些演示。
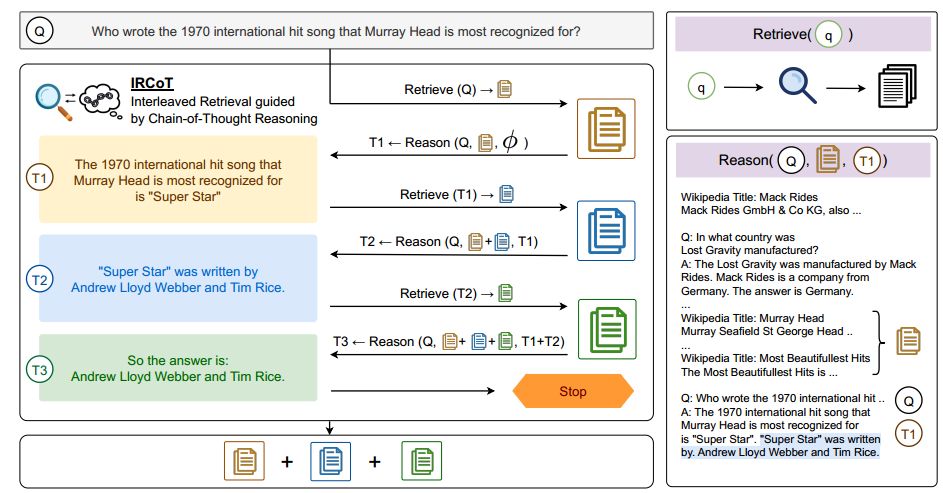
图2: IRCoT将思想链(CoT)的生成和检索步骤交织在一起,通过CoT来指导检索,反之亦然。我们从使用问题检索K个文档开始,当它们查询时,交替重复两个步骤,直到终止。(I)推理步骤基于问题、到目前为止检索到的段落和CoT句子生成下一个CoT句子。(ii)检索-步骤基于最后一个CoT句子再检索K个段落。当生成的CoT具有“答案是”或步骤数超过阈值时,该过程终止。所有段落的集合在终止时作为检索结果返回。
问答阅读器
问答阅读器使用从检索器获取的检索段落来回答问题。我们在实验中考虑将4设为8。在我们的实验中设置为15。问答阅读器的两个版本通过两种提示策略实现:魏等(2022)提出的CoT提示,布朗等(2020)提出的直接提示。对于CoT提示,我们使用与3.2所示相同的模板,但是在测试时,我们要求模型从头开始生成完整的CoT。CoT的最后一句话的形式应该是“答案是:……”,以便可以通过编程提取答案。如果不是那种形式,则返回全代作为答案。对于直接提示,我们使用与CoT提示相同的模板,但是答案字段(" A:")只包含最终答案,而不包含CoT。参见应用程序。详情见g。
实验设置
我们在开放域设置中的4个多步问答数据集上评估我们的方法:HotpotQA (Yang等人,2018),2WikiMultihopQA (Ho等人,2020),MuSiQue的可回答子集(Trivedi等人,2022),和的可回答子集(Ferguson等人,2020)。对于HotpotQA,我们使用它附带的维基百科语料库进行开放域设置。对于最初来自阅读理解或混合环境的其他三个数据集的每一个,我们使用相关的上下文来构建一个我们的开放域设置语料库(见应用。详情见a)。对于每个数据集,我们使用来自原始开发集的100个随机抽样问题来调优超参数,并使用500个其他随机抽样问题作为我们的测试集。
型号检索器
我们使用在Elasticsearch6中实现的BM25 (Robertson等人,2009)作为我们的基本检索器。我们比较两个检索器系统:
- 一步检索器(OneR)使用问题作为查询来检索K个段落。我们选择K ∈ {5,7,9,11,13,15},这在开发集上是最好的。
- IRCoT Retriever是我们在3中描述的方法。我们使用BM25作为其底层检索器,并使用OpenAI GPT3(代码-davinci-002)进行实验(Brown等人,2020;欧阳等,2022;Chen等,2021)和Flan-T5 (Chung等,2022)作为其CoT发生器。
为了向这些LMs演示上下文中的示例,我们为所有数据集的20个问题编写了CoTs(参见App。g)。然后,我们通过为每个数据集抽取15个问题来创建3个演示(“训练”)集。对于每个实验,我们使用第一个演示集搜索开发集的最佳超参数,并使用选择的超参数评估测试集上的每个演示集。我们报告了每个实验的这3个结果的平均值和标准偏差。在测试时,我们在模型的上下文长度限制内打包尽可能多的演示。GPT3(代码-davinci-002)的上下文限制是8K字段。Flan-T5-*没有任何硬性限制,因为它使用相对位置嵌入。但我们将Flan-T5的上下文限制为6K个单词,这是我们80G A100 GPUs的内存所能容纳的最大值。
IRCoT Retriever有一个关键的超参数:K ∈ {2,4,6,8},即每步要检索的段落数。此外,在为IRCoT的推理器模块创建“训练”演示时,我们使用黄金段落和数量较少的M ∈ {1,2,3}个干扰项段落(3.1)。检索度量:我们允许所有检索系统最多有15个段落,并在检索到的段落集中测量黄金段落的召回率。我们在开发集上搜索最大化召回率的超参数K(和IRCoT的M ),并在测试集上使用它。因此,报告的指标可以被视为每个系统的固定预算最佳召回率。7 QA阅读器。为了实现阅读器,我们使用IRCoT Retriever的reason-step中使用的相同LMs。我们发现用Flan-T5-*实现的问答阅读器在直接提示策略下表现更好,而GPT3在CoT提示策略下表现更好(参见应用。e)。
因此,我们在实验中使用Flan-T5-*的问答和GPT3的CoT的直接提示策略。8问答阅读器有一个超参数M:语境演示中干扰项段落的数量。我们在{1,2,3}中搜索M。当与IRCoT retriever M一起使用时,它与CoT发生器和阅读器相连。开放域质量保证(ODQA)模型。将检索器和阅读器放在一起,我们用ODQA模型进行实验,ODQA模型是由各种语言模型构造的,表示为OneR QA和IRCoT QA。对于IRCoT QA,CoT发生器和阅读器的LM选择保持不变。我们还用无检索器的问答阅读器和问答系统进行实验,以评估LMs仅从参数知识回答问题的能力。为了选择ODQA模型的最佳超参数,我们搜索在开发集上最大化答案F1的超参数K和M。IIRC的结构与其他数据集略有不同,因为它的问题基于一个主要段落,其他支持段落来自本文提到的实体的维基百科页面。我们稍微修改了检索器和阅读器来解决这个问题(参见App。b)。
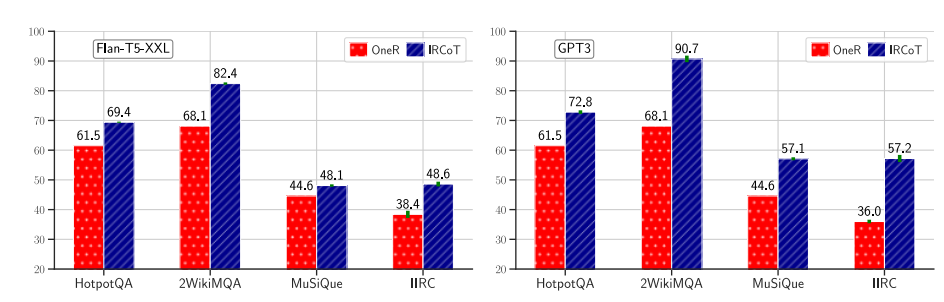
图3:从Flan-T5-XXL(左)和GPT3(右)模型实例化的一步检索器(OneR)和IRCoT的检索召回。IRCoT在模型和所有数据集上都优于OneR。
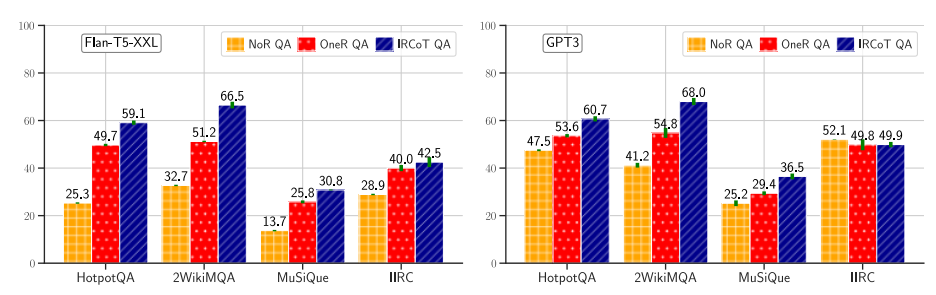
图4:使用(I)无检索器(NoR QA) (ii)一步检索器(OneR QA)和(iii)从Flan-T5-XXL(左)和GPT3(右)模型实例化的IRCoT QA得出的ODQA模型的答案F1。在所有数据集上,IRCoT QA优于OneR QA和NoR QA,除了IIRC的GPT3。
结果
IRCoT检索优于一步法。图3比较了OneR和由以下材料制成的IRCoT取回器Flan-T5-XXL和GPT3 LMs。对于这两个模型,IRCoT在所有数据集上都明显优于一步检索。对于Flan-T5-XXL,IRCoT相对于一步检索提高了我们的召回指标,在HotpotQA上提高了7.9分,在2WikiMultihopQA上提高了14.3分,在MuSiQue上提高了3.5分,在IIRC上提高了10.2分。对于GPT3,这一改善分别为11.3、22.6、12.5和21.2点。IRCoT QA优于NoR和OneR QA。
图4比较了使用由Flan-T5-XXL和GPT3 LMs制造的NoR、OneR和IRCoT检索器的ODQA性能。对于Flan-T5-XXL,IRCoT QA在HotpotQA上领先OneR QA 9.4分,在2WikiMultihopQA上领先15.3分,在MuSiQue上领先5.0分,在F1上领先IIRC 2.5分。对于GPT3,相应的数字(除了IIRC)是7.1,13.2和7.1 F1分。对于GPT3,IRCoT没有提高IIRC的QA分数,尽管显著提高了检索(如图3所示的21分)。这可能是因为IIRC相关知识可能已经存在于GPT3中,这也由它的NoR QA分数相似所证明。对于其他数据集和模型组合,NoR QA比IRCoT QA差得多,这表明了模型参数知识的局限性。
IRCoT在OOD设置中有效。由于CoT可能不总是易于为新数据集编写,我们评估NoR、OneR和IRCoT对新数据集的推广,即OOD设置。为此,我们使用一个数据集的即时演示来评估另一个数据集。9对于所有数据集对10以及Flan-T5-XXL和GPT3,我们发现了与IID设置相同的趋势:IRCoT检索优于OneR(图5),IRCoT QA优于OneR QA和NoR QA(图6)。IRCoT生成的C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











