




推荐算法工程师面试题
- 二分类的分类损失函数?
二分类的分类损失函数一般采用交叉熵(Cross Entropy)损失函数,即CE损失函数。二分类问题的CE损失函数可以写成: 其中,y是真实标签,p是预测标签,取值为0或1。
其中,y是真实标签,p是预测标签,取值为0或1。
- 多分类的分类损失函数(Softmax)?
多分类的分类损失函数采用Softmax交叉熵(Softmax Cross Entropy)损失函数。Softmax函数可以将输出值归一化为概率分布,用于多分类问题的输出层。Softmax交叉熵损失函数可以写成: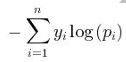 ,其中,n是类别数,yi是第i类的真实标签,pi是第i类的预测概率。
,其中,n是类别数,yi是第i类的真实标签,pi是第i类的预测概率。
- 关于梯度下降的sgdm,adagrad,介绍一下。
- SGD(Stochastic Gradient Descent)是最基础的梯度下降算法,每次迭代随机选取一个样本计算梯度并更新模型参数
- SGDM(Stochastic Gradient Descent withMomentum)在SGD的基础上增加了动量项,可以加速收敛
- Adagrad(AdaptiveGradient)是一种自适应学习率的梯度下降算法,它根据每个参数的梯度历史信息调整学习率,可以更好地适应不同参数的变化范围。
- 为什么不用MSE分类用交叉熵?
MSE(Mean Squared Error)损失函数对离群点敏感,而交叉嫡(CrossEntropy)损失函数在分类问题中表现更好,因为它能更好地刻画分类任务中标签概率分布与模型输出概率分布之间的差异。
- yolov5相比于之前增加的特性有哪些?
YOLOv5相比于之前版本增加了一些特性,包括:使用CSP(Cross StagePartial)架构加速模型训练和推理;采用Swish激活函数代替ReLU;引入多尺度训l练和测试,以提高目标检测的精度和召回率;引入AutoML技术,自动调整超参数以优化模型性能。
- 可以介绍一下attention机制吗?
Attention机制是一种用于序列建模的技术,它可以自适应地对序列中的不同部分赋予不同的权重,以实现更好的特征表示。在Attention机制中,通过计算查询向量与一组键值对之间的相似度,来确定每个键值对的权重,最终通过加权平均的方式得到Attention向量.
- 关于attention机制,三个矩阵KQ,KV,K.的作用是什么?
在Attention机制中,KQV是一组与序列中每个元素对应的三个矩阵,其中K和V分别代表键和值,用于计算对应元素的权重,Q代表查询向量,用于确定权重分配的方式。三个矩阵K、Q、V在Attention机制中的具体作用如下:
- K(Key)矩阵:K矩阵用于计算每个元素的权重,是一个与输入序列相同大小的矩阵。通过计算查询向量Q与每个元素的相似度,确定每个元素在加权平均中所占的5比例。
- Q(Query)向量:Q向量是用来确定权重分配方式的向量,与输入序列中的每个元素都有一个对应的相似度,可以看作是一个加权的向量。
- V(Value)矩阵:V矩阵是与输入序列相同大小的矩阵,用于给每个元素赋予一个对应的特征向量。在Attention机制中,加权平均后的向量就是V矩阵的加权平均向量。
通过K、Q、V三个矩阵的计算,Attention机制可以自适应地为输入序列中的每个元素分配一个权重,以实现更好的特征表示。
- 介绍一下文本检测EAST。
EAST(Efficient and Accurate Scene Text)是一种用于文本检测的神经网络模型。EAST通过以文本行为单位直接预测文本的位置、方向和尺度,避免了传统方法中需要多次检测和合并的过程,从而提高了文本检测的速度和精度。EAST采用了一种新的训练方式,即以真实文本行作为训练样本,以减少模型对背景噪声的干扰,并在测试阶段通过非极大值抑制(NMS)算法进行文本框的合并。
- 编程题(讲思路):给定两个字符串s,在$字符串中找到包含t字符串的最小字串。
给定两个字符串s、t,可以采用滑动窗口的方式在s中找到包含t的最小子串。具体做法如下:
- 定义两个指针left和right,分别指向滑动窗口的左右边界。
- 先移动ight指针,扩展滑动窗口,直到包含了t中的所有字符。
- 移动left指针,缩小滑动窗口,直到无法再包含t中的所有字符。
- 记录当前滑动窗口的长度,如果小于之前记录的长度,则更新最小长度和最小子串。
- 重复(2)到(4)步骤,直到ight指针到达s的末尾为止。
算法工程师暑期实习面试题
- 如何理解交叉熵的物理意义
交叉熵是一种用于比较两个概率分布之间的差异的指标。在机器学习中,它通常用于比较真实标签分布与模型预测分布之间的差异。
- 过拟合如何去解决?
L1正则为什么能够使得参数稀疏,从求导的角度阐述。过拟合的解决方法有很多:数据的角度:获取和使用更多的数据(数据集增强)模型角度:降低模型复杂度、L1L2 Dropout正则化、Early stopping(提前终止)
模型融合的角度:使用bagging等模型融合方法。L1正则化在损失函数中加入参数的绝对值之和,可以使得一些参数变得非常小或者为零,从而使得模型更加稀疏,减少过拟合的风险。从求导的角度来看:L1正则化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











