






- 🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客
- 🍖 原作者:K同学啊 | 接輔導、項目定制
一、前期准备
1. 导入数据
# Import the required libraries
import numpy as np
import PIL,pathlib
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,models
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# load the data
data_dir = './data/48-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
classeNames
2. 查看数据
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)![]()
stars = list(data_dir.glob('Jennifer Lawrence/*.jpg'))
PIL.Image.open(str(stars[0]))
二、数据预处理
1. 加载数据
# Data loading and preprocessing
batch_size = 32
img_height = 224
img_width = 224
label_mode:
int:标签将被编码成整数(使用的损失函数应为:sparse_categorical_crossentropy loss)。
categorical:标签将被编码为分类向量(使用的损失函数应为:categorical_crossentropy loss)。
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="training",
label_mode = "categorical",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)![]()
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="validation",
label_mode = "categorical",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']2. 可视化数据
# Visualize the data
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[np.argmax(labels[i])])
plt.axis("off")
# Check the shape of the data
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
3. 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)三、训练模型
1. 构建CNN网络模型
"""
关于卷积核的计算不懂的可以参考文章:https://blog.youkuaiyun.com/qq_38251616/article/details/114278995
layers.Dropout(0.5) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/115826689
"""
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Dropout(0.5),
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.AveragePooling2D((2, 2)),
layers.Dropout(0.5),
layers.Conv2D(128, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.5),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 224, 224, 3) 0
conv2d (Conv2D) (None, 222, 222, 16) 448
average_pooling2d (Average (None, 111, 111, 16) 0
Pooling2D)
conv2d_1 (Conv2D) (None, 109, 109, 32) 4640
average_pooling2d_1 (Avera (None, 54, 54, 32) 0
gePooling2D)
dropout (Dropout) (None, 54, 54, 32) 0
conv2d_2 (Conv2D) (None, 52, 52, 64) 18496
average_pooling2d_2 (Avera (None, 26, 26, 64) 0
gePooling2D)
dropout_1 (Dropout) (None, 26, 26, 64) 0
conv2d_3 (Conv2D) (None, 24, 24, 128) 73856
dropout_2 (Dropout) (None, 24, 24, 128) 0
flatten (Flatten) (None, 73728) 0
dense (Dense) (None, 128) 9437312
dense_1 (Dense) (None, 17) 2193
=================================================================
Total params: 9536945 (36.38 MB)
Trainable params: 9536945 (36.38 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
2. 设置动态学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=60, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])3.早停与保存最佳模型参数
epochs = 100
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=20,
verbose=1)4. 模型训练
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])Epoch 1/100
51/51 [==============================] - ETA: 0s - loss: 2.8104 - accuracy: 0.0969
Epoch 1: val_accuracy improved from -inf to 0.13889, saving model to best_model.h5
51/51 [==============================] - 55s 982ms/step - loss: 2.8104 - accuracy: 0.0969 - val_loss: 2.7776 - val_accuracy: 0.1389
Epoch 2/100
51/51 [==============================] - ETA: 0s - loss: 2.7429 - accuracy: 0.1216
Epoch 2: val_accuracy improved from 0.13889 to 0.17222, saving model to best_model.h5
51/51 [==============================] - 61s 1s/step - loss: 2.7429 - accuracy: 0.1216 - val_loss: 2.6774 - val_accuracy: 0.1722
Epoch 3/100
51/51 [==============================] - ETA: 0s - loss: 2.6460 - accuracy: 0.1512
Epoch 3: val_accuracy improved from 0.17222 to 0.21667, saving model to best_model.h5
51/51 [==============================] - 83s 2s/step - loss: 2.6460 - accuracy: 0.1512 - val_loss: 2.5815 - val_accuracy: 0.2167
Epoch 4/100
51/51 [==============================] - ETA: 0s - loss: 2.5256 - accuracy: 0.1889
Epoch 4: val_accuracy did not improve from 0.21667
51/51 [==============================] - 48s 925ms/step - loss: 2.5256 - accuracy: 0.1889 - val_loss: 2.5280 - val_accuracy: 0.2111
Epoch 5/100
51/51 [==============================] - ETA: 0s - loss: 2.4414 - accuracy: 0.2025
Epoch 5: val_accuracy did not improve from 0.21667
51/51 [==============================] - 42s 827ms/step - loss: 2.4414 - accuracy: 0.2025 - val_loss: 2.5463 - val_accuracy: 0.1889
Epoch 6/100
51/51 [==============================] - ETA: 0s - loss: 2.3298 - accuracy: 0.2599
Epoch 6: val_accuracy did not improve from 0.21667
51/51 [==============================] - 57s 1s/step - loss: 2.3298 - accuracy: 0.2599 - val_loss: 2.5459 - val_accuracy: 0.2056
Epoch 7/100
51/51 [==============================] - ETA: 0s - loss: 2.2399 - accuracy: 0.2623
Epoch 7: val_accuracy did not improve from 0.21667
51/51 [==============================] - 54s 1s/step - loss: 2.2399 - accuracy: 0.2623 - val_loss: 2.4820 - val_accuracy: 0.2167
Epoch 8/100
51/51 [==============================] - ETA: 0s - loss: 2.1601 - accuracy: 0.2963
Epoch 8: val_accuracy improved from 0.21667 to 0.22222, saving model to best_model.h5
51/51 [==============================] - 60s 1s/step - loss: 2.1601 - accuracy: 0.2963 - val_loss: 2.5153 - val_accuracy: 0.2222
Epoch 9/100
51/51 [==============================] - ETA: 0s - loss: 2.0753 - accuracy: 0.3358
Epoch 9: val_accuracy did not improve from 0.22222
51/51 [==============================] - 58s 1s/step - loss: 2.0753 - accuracy: 0.3358 - val_loss: 2.5161 - val_accuracy: 0.2222
Epoch 10/100
51/51 [==============================] - ETA: 0s - loss: 1.9911 - accuracy: 0.3519
Epoch 10: val_accuracy improved from 0.22222 to 0.22778, saving model to best_model.h5
51/51 [==============================] - 43s 836ms/step - loss: 1.9911 - accuracy: 0.3519 - val_loss: 2.4262 - val_accuracy: 0.2278
Epoch 11/100
51/51 [==============================] - ETA: 0s - loss: 1.9407 - accuracy: 0.3710
Epoch 11: val_accuracy did not improve from 0.22778
51/51 [==============================] - 41s 808ms/step - loss: 1.9407 - accuracy: 0.3710 - val_loss: 2.4870 - val_accuracy: 0.2111
Epoch 12/100
51/51 [==============================] - ETA: 0s - loss: 1.8644 - accuracy: 0.4006
Epoch 12: val_accuracy improved from 0.22778 to 0.24444, saving model to best_model.h5
51/51 [==============================] - 61s 1s/step - loss: 1.8644 - accuracy: 0.4006 - val_loss: 2.3879 - val_accuracy: 0.2444
Epoch 13/100
51/51 [==============================] - ETA: 0s - loss: 1.7614 - accuracy: 0.4364
Epoch 13: val_accuracy did not improve from 0.24444
51/51 [==============================] - 46s 902ms/step - loss: 1.7614 - accuracy: 0.4364 - val_loss: 2.3441 - val_accuracy: 0.2278
Epoch 14/100
51/51 [==============================] - ETA: 0s - loss: 1.6527 - accuracy: 0.4741
Epoch 14: val_accuracy did not improve from 0.24444
51/51 [==============================] - 40s 785ms/step - loss: 1.6527 - accuracy: 0.4741 - val_loss: 2.4992 - val_accuracy: 0.2444
Epoch 15/100
51/51 [==============================] - ETA: 0s - loss: 1.5427 - accuracy: 0.5210
Epoch 15: val_accuracy did not improve from 0.24444
51/51 [==============================] - 52s 1s/step - loss: 1.5427 - accuracy: 0.5210 - val_loss: 2.4521 - val_accuracy: 0.2278
Epoch 16/100
51/51 [==============================] - ETA: 0s - loss: 1.4529 - accuracy: 0.5389
Epoch 16: val_accuracy improved from 0.24444 to 0.25000, saving model to best_model.h5
51/51 [==============================] - 53s 1s/step - loss: 1.4529 - accuracy: 0.5389 - val_loss: 2.5397 - val_accuracy: 0.2500
Epoch 17/100
51/51 [==============================] - ETA: 0s - loss: 1.3803 - accuracy: 0.5586
Epoch 17: val_accuracy did not improve from 0.25000
51/51 [==============================] - 41s 798ms/step - loss: 1.3803 - accuracy: 0.5586 - val_loss: 2.5153 - val_accuracy: 0.2444
Epoch 18/100
51/51 [==============================] - ETA: 0s - loss: 1.2879 - accuracy: 0.5926
Epoch 18: val_accuracy did not improve from 0.25000
51/51 [==============================] - 49s 968ms/step - loss: 1.2879 - accuracy: 0.5926 - val_loss: 2.6099 - val_accuracy: 0.2389
Epoch 19/100
51/51 [==============================] - ETA: 0s - loss: 1.2063 - accuracy: 0.6185
Epoch 19: val_accuracy improved from 0.25000 to 0.27222, saving model to best_model.h5
51/51 [==============================] - 48s 932ms/step - loss: 1.2063 - accuracy: 0.6185 - val_loss: 2.5122 - val_accuracy: 0.2722
Epoch 20/100
51/51 [==============================] - ETA: 0s - loss: 1.1112 - accuracy: 0.6494
Epoch 20: val_accuracy did not improve from 0.27222
51/51 [==============================] - 42s 815ms/step - loss: 1.1112 - accuracy: 0.6494 - val_loss: 2.5638 - val_accuracy: 0.2611
Epoch 21/100
51/51 [==============================] - ETA: 0s - loss: 1.0587 - accuracy: 0.6630
Epoch 21: val_accuracy did not improve from 0.27222
51/51 [==============================] - 56s 1s/step - loss: 1.0587 - accuracy: 0.6630 - val_loss: 2.5780 - val_accuracy: 0.2667
Epoch 22/100
51/51 [==============================] - ETA: 0s - loss: 0.9566 - accuracy: 0.6920
Epoch 22: val_accuracy did not improve from 0.27222
51/51 [==============================] - 47s 922ms/step - loss: 0.9566 - accuracy: 0.6920 - val_loss: 2.6150 - val_accuracy: 0.2444
Epoch 23/100
51/51 [==============================] - ETA: 0s - loss: 0.8799 - accuracy: 0.7247
Epoch 23: val_accuracy improved from 0.27222 to 0.27778, saving model to best_model.h5
51/51 [==============================] - 42s 827ms/step - loss: 0.8799 - accuracy: 0.7247 - val_loss: 2.6924 - val_accuracy: 0.2778
Epoch 24/100
51/51 [==============================] - ETA: 0s - loss: 0.8433 - accuracy: 0.7333
Epoch 24: val_accuracy improved from 0.27778 to 0.31111, saving model to best_model.h5
51/51 [==============================] - 54s 1s/step - loss: 0.8433 - accuracy: 0.7333 - val_loss: 2.6021 - val_accuracy: 0.3111
Epoch 25/100
51/51 [==============================] - ETA: 0s - loss: 0.7853 - accuracy: 0.7401
Epoch 25: val_accuracy did not improve from 0.31111
51/51 [==============================] - 52s 1s/step - loss: 0.7853 - accuracy: 0.7401 - val_loss: 2.7423 - val_accuracy: 0.2889
Epoch 26/100
51/51 [==============================] - ETA: 0s - loss: 0.7109 - accuracy: 0.7728
Epoch 26: val_accuracy did not improve from 0.31111
51/51 [==============================] - 42s 815ms/step - loss: 0.7109 - accuracy: 0.7728 - val_loss: 2.8648 - val_accuracy: 0.2722
Epoch 27/100
51/51 [==============================] - ETA: 0s - loss: 0.6554 - accuracy: 0.7957
Epoch 27: val_accuracy did not improve from 0.31111
51/51 [==============================] - 53s 1s/step - loss: 0.6554 - accuracy: 0.7957 - val_loss: 2.8639 - val_accuracy: 0.3056
Epoch 28/100
51/51 [==============================] - ETA: 0s - loss: 0.5959 - accuracy: 0.8142
Epoch 28: val_accuracy improved from 0.31111 to 0.34444, saving model to best_model.h5
51/51 [==============================] - 42s 813ms/step - loss: 0.5959 - accuracy: 0.8142 - val_loss: 2.8515 - val_accuracy: 0.3444
Epoch 29/100
51/51 [==============================] - ETA: 0s - loss: 0.5638 - accuracy: 0.8210
Epoch 29: val_accuracy did not improve from 0.34444
51/51 [==============================] - 40s 777ms/step - loss: 0.5638 - accuracy: 0.8210 - val_loss: 2.7636 - val_accuracy: 0.3167
Epoch 30/100
51/51 [==============================] - ETA: 0s - loss: 0.5263 - accuracy: 0.8426
Epoch 30: val_accuracy did not improve from 0.34444
51/51 [==============================] - 50s 975ms/step - loss: 0.5263 - accuracy: 0.8426 - val_loss: 2.9591 - val_accuracy: 0.3111
Epoch 31/100
51/51 [==============================] - ETA: 0s - loss: 0.4815 - accuracy: 0.8481
Epoch 31: val_accuracy did not improve from 0.34444
51/51 [==============================] - 43s 838ms/step - loss: 0.4815 - accuracy: 0.8481 - val_loss: 2.9548 - val_accuracy: 0.3167
Epoch 32/100
51/51 [==============================] - ETA: 0s - loss: 0.4384 - accuracy: 0.8642
Epoch 32: val_accuracy did not improve from 0.34444
51/51 [==============================] - 42s 832ms/step - loss: 0.4384 - accuracy: 0.8642 - val_loss: 3.0466 - val_accuracy: 0.3222
Epoch 33/100
51/51 [==============================] - ETA: 0s - loss: 0.4125 - accuracy: 0.8772
Epoch 33: val_accuracy did not improve from 0.34444
51/51 [==============================] - 62s 1s/step - loss: 0.4125 - accuracy: 0.8772 - val_loss: 3.0511 - val_accuracy: 0.3333
Epoch 34/100
51/51 [==============================] - ETA: 0s - loss: 0.4033 - accuracy: 0.8833
Epoch 34: val_accuracy did not improve from 0.34444
51/51 [==============================] - 43s 845ms/step - loss: 0.4033 - accuracy: 0.8833 - val_loss: 3.0960 - val_accuracy: 0.3278
Epoch 35/100
51/51 [==============================] - ETA: 0s - loss: 0.3463 - accuracy: 0.9012
Epoch 35: val_accuracy did not improve from 0.34444
51/51 [==============================] - 39s 760ms/step - loss: 0.3463 - accuracy: 0.9012 - val_loss: 3.1227 - val_accuracy: 0.3278
Epoch 36/100
51/51 [==============================] - ETA: 0s - loss: 0.3127 - accuracy: 0.9080
Epoch 36: val_accuracy improved from 0.34444 to 0.36667, saving model to best_model.h5
51/51 [==============================] - 48s 934ms/step - loss: 0.3127 - accuracy: 0.9080 - val_loss: 3.1175 - val_accuracy: 0.3667
Epoch 37/100
51/51 [==============================] - ETA: 0s - loss: 0.3058 - accuracy: 0.9043
Epoch 37: val_accuracy did not improve from 0.36667
51/51 [==============================] - 46s 904ms/step - loss: 0.3058 - accuracy: 0.9043 - val_loss: 3.2871 - val_accuracy: 0.3389
Epoch 38/100
51/51 [==============================] - ETA: 0s - loss: 0.2899 - accuracy: 0.9179
Epoch 38: val_accuracy did not improve from 0.36667
51/51 [==============================] - 44s 852ms/step - loss: 0.2899 - accuracy: 0.9179 - val_loss: 3.3441 - val_accuracy: 0.3389
Epoch 39/100
51/51 [==============================] - ETA: 0s - loss: 0.2924 - accuracy: 0.9154
Epoch 39: val_accuracy did not improve from 0.36667
51/51 [==============================] - 51s 1s/step - loss: 0.2924 - accuracy: 0.9154 - val_loss: 3.4429 - val_accuracy: 0.3333
Epoch 40/100
51/51 [==============================] - ETA: 0s - loss: 0.2470 - accuracy: 0.9309
Epoch 40: val_accuracy improved from 0.36667 to 0.37222, saving model to best_model.h5
51/51 [==============================] - 43s 839ms/step - loss: 0.2470 - accuracy: 0.9309 - val_loss: 3.3887 - val_accuracy: 0.3722
Epoch 41/100
51/51 [==============================] - ETA: 0s - loss: 0.2460 - accuracy: 0.9327
Epoch 41: val_accuracy did not improve from 0.37222
51/51 [==============================] - 39s 764ms/step - loss: 0.2460 - accuracy: 0.9327 - val_loss: 3.5563 - val_accuracy: 0.3167
Epoch 42/100
51/51 [==============================] - ETA: 0s - loss: 0.2411 - accuracy: 0.9296
Epoch 42: val_accuracy did not improve from 0.37222
51/51 [==============================] - 48s 948ms/step - loss: 0.2411 - accuracy: 0.9296 - val_loss: 3.4190 - val_accuracy: 0.3556
Epoch 43/100
51/51 [==============================] - ETA: 0s - loss: 0.2156 - accuracy: 0.9395
Epoch 43: val_accuracy did not improve from 0.37222
51/51 [==============================] - 46s 888ms/step - loss: 0.2156 - accuracy: 0.9395 - val_loss: 3.6015 - val_accuracy: 0.3333
Epoch 44/100
51/51 [==============================] - ETA: 0s - loss: 0.2391 - accuracy: 0.9302
Epoch 44: val_accuracy did not improve from 0.37222
51/51 [==============================] - 40s 780ms/step - loss: 0.2391 - accuracy: 0.9302 - val_loss: 3.5229 - val_accuracy: 0.3333
Epoch 45/100
51/51 [==============================] - ETA: 0s - loss: 0.1866 - accuracy: 0.9475
Epoch 45: val_accuracy did not improve from 0.37222
51/51 [==============================] - 43s 848ms/step - loss: 0.1866 - accuracy: 0.9475 - val_loss: 3.5975 - val_accuracy: 0.3611
Epoch 46/100
51/51 [==============================] - ETA: 0s - loss: 0.1977 - accuracy: 0.9469
Epoch 46: val_accuracy did not improve from 0.37222
51/51 [==============================] - 69s 1s/step - loss: 0.1977 - accuracy: 0.9469 - val_loss: 3.5875 - val_accuracy: 0.3333
Epoch 47/100
51/51 [==============================] - ETA: 0s - loss: 0.1788 - accuracy: 0.9512
Epoch 47: val_accuracy did not improve from 0.37222
51/51 [==============================] - 40s 771ms/step - loss: 0.1788 - accuracy: 0.9512 - val_loss: 3.5546 - val_accuracy: 0.3444
Epoch 48/100
51/51 [==============================] - ETA: 0s - loss: 0.1751 - accuracy: 0.9549
Epoch 48: val_accuracy did not improve from 0.37222
51/51 [==============================] - 40s 785ms/step - loss: 0.1751 - accuracy: 0.9549 - val_loss: 3.5999 - val_accuracy: 0.3611
Epoch 49/100
51/51 [==============================] - ETA: 0s - loss: 0.1670 - accuracy: 0.9580
Epoch 49: val_accuracy did not improve from 0.37222
51/51 [==============================] - 47s 915ms/step - loss: 0.1670 - accuracy: 0.9580 - val_loss: 3.5886 - val_accuracy: 0.3556
Epoch 50/100
51/51 [==============================] - ETA: 0s - loss: 0.1653 - accuracy: 0.9549
Epoch 50: val_accuracy did not improve from 0.37222
51/51 [==============================] - 45s 880ms/step - loss: 0.1653 - accuracy: 0.9549 - val_loss: 3.6597 - val_accuracy: 0.3667
Epoch 51/100
51/51 [==============================] - ETA: 0s - loss: 0.1601 - accuracy: 0.9605
Epoch 51: val_accuracy did not improve from 0.37222
51/51 [==============================] - 39s 770ms/step - loss: 0.1601 - accuracy: 0.9605 - val_loss: 3.7600 - val_accuracy: 0.3722
Epoch 52/100
51/51 [==============================] - ETA: 0s - loss: 0.1573 - accuracy: 0.9531
Epoch 52: val_accuracy did not improve from 0.37222
51/51 [==============================] - 44s 864ms/step - loss: 0.1573 - accuracy: 0.9531 - val_loss: 3.7125 - val_accuracy: 0.3667
Epoch 53/100
51/51 [==============================] - ETA: 0s - loss: 0.1432 - accuracy: 0.9642
Epoch 53: val_accuracy did not improve from 0.37222
51/51 [==============================] - 47s 913ms/step - loss: 0.1432 - accuracy: 0.9642 - val_loss: 3.6886 - val_accuracy: 0.3722
Epoch 54/100
51/51 [==============================] - ETA: 0s - loss: 0.1508 - accuracy: 0.9519
Epoch 54: val_accuracy did not improve from 0.37222
51/51 [==============================] - 40s 783ms/step - loss: 0.1508 - accuracy: 0.9519 - val_loss: 3.7534 - val_accuracy: 0.3444
Epoch 55/100
51/51 [==============================] - ETA: 0s - loss: 0.1364 - accuracy: 0.9642
Epoch 55: val_accuracy did not improve from 0.37222
51/51 [==============================] - 41s 793ms/step - loss: 0.1364 - accuracy: 0.9642 - val_loss: 3.8380 - val_accuracy: 0.3556
Epoch 56/100
51/51 [==============================] - ETA: 0s - loss: 0.1404 - accuracy: 0.9617
Epoch 56: val_accuracy did not improve from 0.37222
51/51 [==============================] - 54s 1s/step - loss: 0.1404 - accuracy: 0.9617 - val_loss: 3.7046 - val_accuracy: 0.3667
Epoch 57/100
51/51 [==============================] - ETA: 0s - loss: 0.1171 - accuracy: 0.9710
Epoch 57: val_accuracy did not improve from 0.37222
51/51 [==============================] - 42s 822ms/step - loss: 0.1171 - accuracy: 0.9710 - val_loss: 3.8028 - val_accuracy: 0.3500
Epoch 58/100
51/51 [==============================] - ETA: 0s - loss: 0.1149 - accuracy: 0.9735
Epoch 58: val_accuracy did not improve from 0.37222
51/51 [==============================] - 40s 780ms/step - loss: 0.1149 - accuracy: 0.9735 - val_loss: 3.7751 - val_accuracy: 0.3722
Epoch 59/100
51/51 [==============================] - ETA: 0s - loss: 0.1113 - accuracy: 0.9741
Epoch 59: val_accuracy did not improve from 0.37222
51/51 [==============================] - 45s 871ms/step - loss: 0.1113 - accuracy: 0.9741 - val_loss: 3.8863 - val_accuracy: 0.3389
Epoch 60/100
51/51 [==============================] - ETA: 0s - loss: 0.1221 - accuracy: 0.9679
Epoch 60: val_accuracy did not improve from 0.37222
51/51 [==============================] - 53s 1s/step - loss: 0.1221 - accuracy: 0.9679 - val_loss: 3.8284 - val_accuracy: 0.3722
Epoch 60: early stopping
四、模型评估
1. Loss与Accuracy图
# Evaluate the model
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()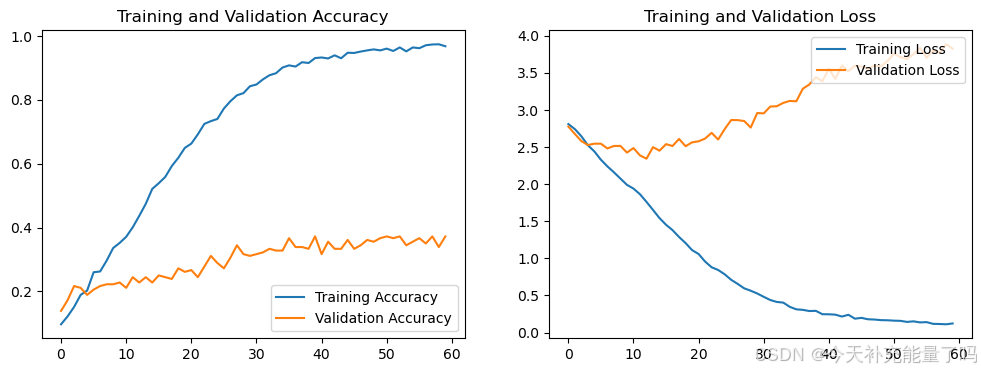
2. 指定图片进行预测
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
img = Image.open("./data/48-data/Jennifer Lawrence/003_963a3627.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









