






 本文详细介绍如何在ModelArts平台上实现图像分类项目的训练、推理代码编写及模型部署上线全流程,涵盖PyTorch环境下训练代码编写、推理代码及配置文件准备,并分享实战经验。
本文详细介绍如何在ModelArts平台上实现图像分类项目的训练、推理代码编写及模型部署上线全流程,涵盖PyTorch环境下训练代码编写、推理代码及配置文件准备,并分享实战经验。
默认已完成modelarts的注册登录以及秘钥设置。以图像分类项目为例(我用的是pytorch,就拿pytorch来说明)
一、编写训练代码(如果有训练好的模型就可以跳过这一步)
1、使用modelarts提供的notebook开发环境进行训练
- 把训练所需要的数据传到桶中,如果数量较多建议先压缩,往桶中传压缩包。可以使用OBS Browser+进行批量上传。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RhGVg2Bl-1591207750223)(./上传.png)]](https://i-blog.csdnimg.cn/blog_migrate/381d50a6bdd7665fdc1d20d23fb1d629.png)
- 在开发环境中创建并运行一个notebook环境,存储配置选择OBS中数据所在的位置。
- 新建一个ipynb文件,选择适合的引擎。
- 把训练需要的数据进行同步。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Vx2HYfJ-1591207750226)(./同步.png)]](https://i-blog.csdnimg.cn/blog_migrate/c833a12098a1e3c80d459b5431b1f9a6.png)
- 在notebook中可以查看当前的工作路径以及刚刚同步好的数据压缩包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3e8P90K5-1591207750227)(./工作路径子文件.png)]](https://i-blog.csdnimg.cn/blog_migrate/8ed2a9367015a4638e4c085b762a742e.png)
- 解压(按照自己的需求进行修改)
用其他的方法也能达到同步数据的效果,可在modelarts的官方文档中查看import zipfile def unzip_file(zip_src,dst_dir): r=zipfile.is_zipfile(zip_src) if r: fz=zipfile.ZipFile(zip_src,'r') for file in fz .namelist(): fz.extract(file,dst_dir) else: print('This is not zip') current_path = os.getcwd() unzip_file(os.path.join(current_path+'/1-11.zip'),os.path.join(current_path+'/train')) unzip_file(os.path.join(current_path+'/12-25.zip'),os.path.join(current_path+'/train')) unzip_file(os.path.join(current_path+'/26-41.zip'),os.path.join(current_path+'/train')) - 编写训练代码(Github上找找)
- 保存训练模型到obs
torch.save(model.state_dict(), 'model.pt') from modelarts.session import Session session=Session() session.upload_data(bucket_path="/桶名称/具体路径",path="/home/ma-user/work/model.pt")
2、使用PyCharm ToolKit插件利用pycharm进行训练
这部分我翻车了,诸君加油~,我择日再踩坑。
二、编写推理代码和配置文件
在modelarts上部署上线,需要按照要求把模型、推理代码、配置文件放在一起,详细要求以官方文档为准。仍旧以pytorch为例,将需要的文件放在model文件夹下,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XSYMLuwQ-1591207750229)(./模型包.png)]](https://i-blog.csdnimg.cn/blog_migrate/771548d61863bc88229c94577a44631b.png)
1、推理代码(我还是以pytorch说明的,其他情况看官方文档)
官方给出了使用MNIST数据集的一个推理代码,我们在它的基础上进行修改,主要是对输入的数据进行处理,使他适合模型的输入,:
from PIL import Image
import log
from model_service.pytorch_model_service import PTServingBaseService
import torch.nn.functional as F
import torch.nn as nn
import torch
import json
import numpy as np
logger = log.getLogger(__name__)
import torchvision.transforms as transforms
# 这一部分也还是根据个人需求进行修改的,直接删了也不影响,你也不一定会用到这个处理方式,看个人。
# 定义模型预处理
infer_transformation = transforms.Compose([
transforms.Resize((28,28)),
# 需要处理成pytorch tensor
transforms.ToTensor()
])
import os
class PTVisionService(PTServingBaseService):
def __init__(self, model_name, model_path):
# 调用父类构造方法
super(PTVisionService, self).__init__(model_name, model_path)
# 调用自定义函数加载模型
# 要是把最后面的函数名改了,这里也要改的。
self.model = Mnist(model_path)
# 加载标签 根据自己的模型进行修改
self.label = [0,1,2,3,4,5,6,7,8,9]
#我是初学者,不会整什么幺蛾子,没用下面的这个,直接给删了。
# 亦可通过文件标签文件加载
# model目录下放置label.json文件,此处读取
dir_path = os.path.dirname(os.path.realpath(self.model_path))
with open(os.path.join(dir_path, 'label.json')) as f:
self.label = json.load(f)
#按照自己训练模型中的数据处理方式去处理数据
#我没啥好办法,只能写一次,拿上去尝试部署上线一次,然后看日志报错接着改。
def _preprocess(self, data):
preprocessed_data = {}
for k, v in data.items():
input_batch = []
for file_name, file_content in v.items():
with Image.open(file_content) as image1:
# 灰度处理
# 很明显image1就是图片,按照训练代码中的要求转换为tensor
image1 = image1.convert("L")
if torch.cuda.is_available():
input_batch.append(infer_transformation(image1).cuda())
else:
input_batch.append(infer_transformation(image1))
input_batch_var = torch.autograd.Variable(torch.stack(input_batch, dim=0), volatile=True)
print(input_batch_var.shape)
preprocessed_data[k] = input_batch_var
return preprocessed_data
#根据模型返回的数据判断类别(参照训练时计算acc和loss的那一部分代码),把要输出的结果append到results中
def _postprocess(self, data):
results = []
for k, v in data.items():
result = torch.argmax(v[0])
result = {k: self.label[result]}
results.append(result)
return results
#参考自己的神经网络结构,直接从训练代码中复制过来替换这一部分,调用的时候注意一下就行
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden1 = nn.Linear(784, 5120, bias=False)
self.output = nn.Linear(5120, 10, bias=False)
def forward(self, x):
x = x.view(x.size()[0], -1)
x = F.relu((self.hidden1(x)))
x = F.dropout(x, 0.2)
x = self.output(x)
return F.log_softmax(x)
#这部分基本不用改,要是看着函数名字难受可以给改了
def Mnist(model_path, **kwargs):
# 生成网络
model = Net()
# 加载模型
if torch.cuda.is_available():
device = torch.device('cuda')
model.load_state_dict(torch.load(model_path, map_location="cuda:0"))
else:
device = torch.device('cpu')
model.load_state_dict(torch.load(model_path, map_location=device))
# CPU或者GPU映射
model.to(device)
# 声明为推理模式
model.eval()
return model
需要改的地方:
- def init(self, model_name, model_path)里标签和加载模型的函数
- class Net(nn.Module)直接换成自己的网络代码。
- def _preprocess(self, data):
- def _postprocess(self, data):
其它不用管
2、配置文件
遇事不决,复制粘贴。网址在此:https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0092.html#modelarts_23_0092__table7143191919436
根据需求把model_algorithm,dependencies,metrics改改
推理代码的坑慢慢踩吧,每个人的都不一样 :)
三、导入模型、部署上线
在ModelArts中找到模型管理选择导入,元模型来源选择OBS,选中model的"上一级文件夹"就行。选择创建,等它完成之后部署上线。
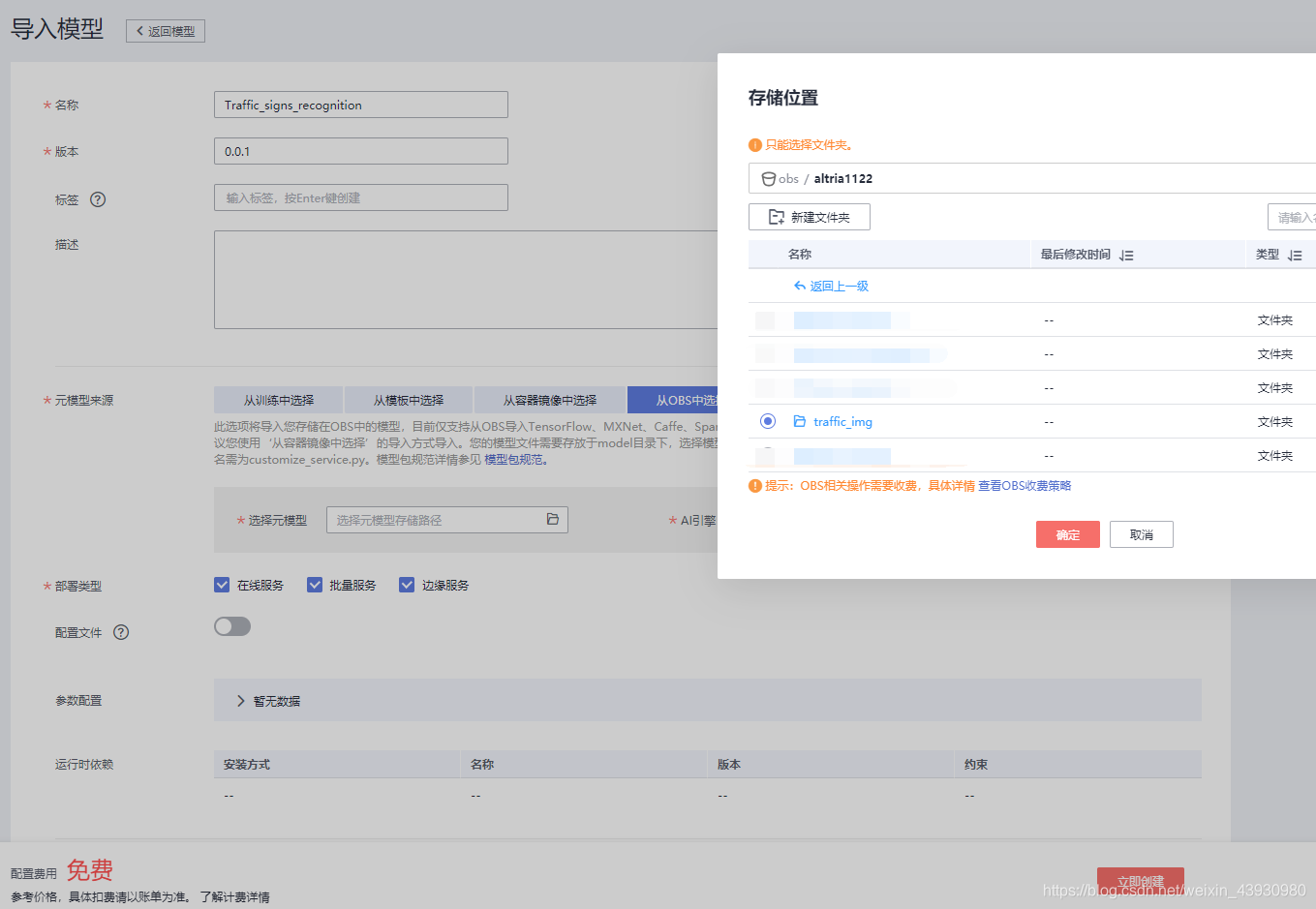
(其实这一部分在编写推理代码的时候会频繁用到,因为modelarts暂时不支持推理代码的运行调试,只有部署上去运行才能发现错误)
ps:导入数据、导入模型等各个步骤都不唯一,选择自己需要的方式
pps:官方文档写的很全,多看看,很多问题都能找到答案

















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









